 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning based Multi-Source Localization with Source Splitting and its Effectiveness in Multi-Talker Speech Recognition
Paper and Code
Feb 16, 2021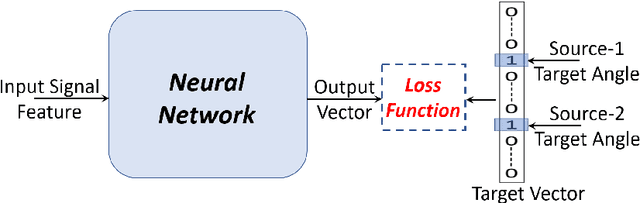
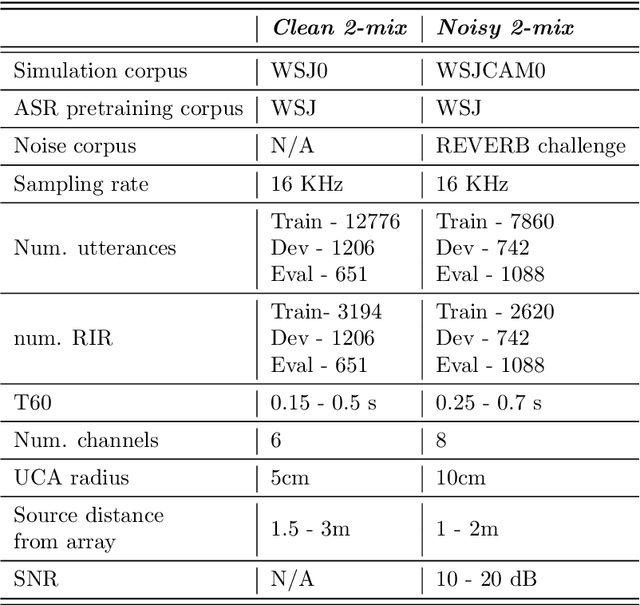
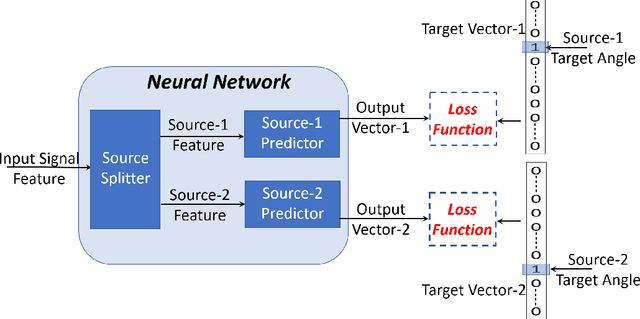
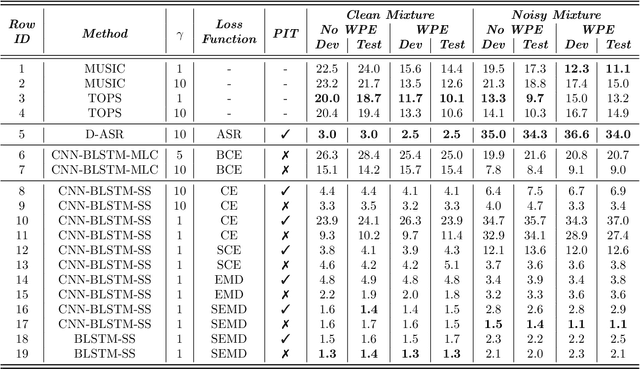
Multi-source localization is an important and challenging technique for multi-talker conversation analysis. This paper proposes a novel supervised learning method using deep neural networks to estimate the direction of arrival (DOA) of all the speakers simultaneously from the audio mixture. At the heart of the proposal is a source splitting mechanism that creates source-specific intermediate representations inside the network. This allows our model to give source-specific posteriors as the output unlike the traditional multi-label classification approach. Existing deep learning methods perform a frame level prediction, whereas our approach performs an utterance level prediction by incorporating temporal selection and averaging inside the network to avoid post-processing. We also experiment with various loss functions and show that a variant of earth mover distance (EMD) is very effective in classifying DOA at a very high resolution by modeling inter-class relationships. In addition to using the prediction error as a metric for evaluating our localization model, we also establish its potency as a frontend with automatic speech recognition (ASR) as the downstream task. We convert the estimated DOAs into a feature suitable for ASR and pass it as an additional input feature to a strong multi-channel and multi-talker speech recognition baseline. This added input feature drastically improves the ASR performance and gives a word error rate (WER) of 6.3% on the evaluation data of our simulated noisy two speaker mixtures, while the baseline which doesn't use explicit localization input has a WER of 11.5%. We also perform ASR evaluation on real recordings with the overlapped set of the MC-WSJ-AV corpus in addition to simulated mixtures.