 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailing Forward: Improving Generative Error Correction for ASR with Synthetic Data and Retrieval Augmentation
Oct 17, 2024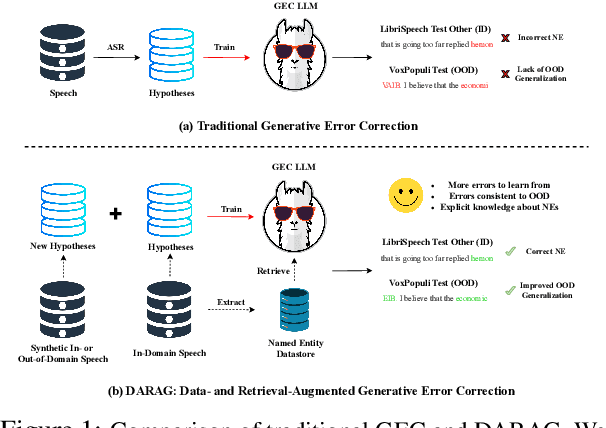
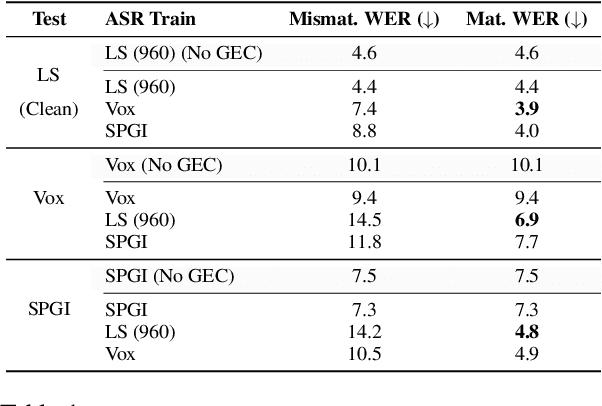
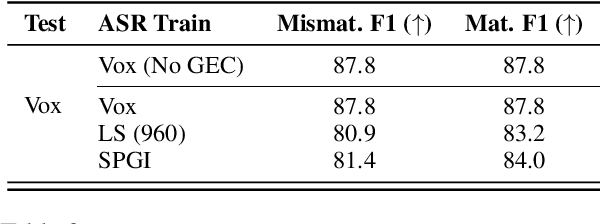
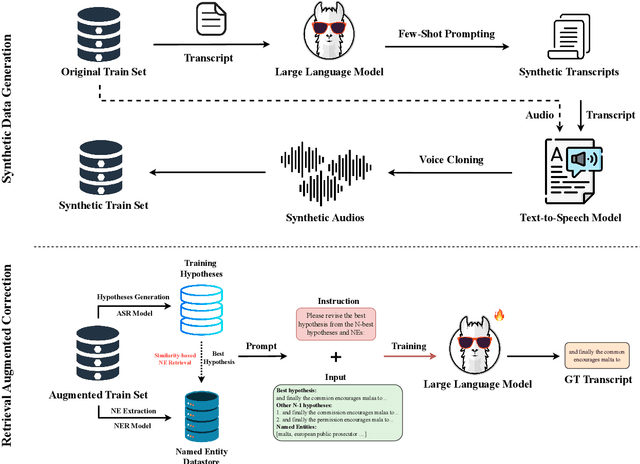
Generative Error Correction (GEC) has emerged as a powerful post-processing method to enhance the performance of Automatic Speech Recognition (ASR) systems. However, we show that GEC models struggle to generalize beyond the specific types of errors encountered during training, limiting their ability to correct new, unseen errors at test time, particularly in out-of-domain (OOD) scenarios. This phenomenon amplifies with named entities (NEs), where, in addition to insufficient contextual information or knowledge about the NEs, novel NEs keep emerging. To address these issues, we propose DARAG (Data- and Retrieval-Augmented Generative Error Correction), a novel approach designed to improve GEC for ASR in in-domain (ID) and OOD scenarios. We augment the GEC training dataset with synthetic data generated by prompting LLMs and text-to-speech models, thereby simulating additional errors from which the model can learn. For OOD scenarios, we simulate test-time errors from new domains similarly and in an unsupervised fashion. Additionally, to better handle named entities, we introduce retrieval-augmented correction by augmenting the input with entities retrieved from a database. Our approach is simple, scalable, and both domain- and language-agnostic. We experiment on multiple datasets and settings, showing that DARAG outperforms all our baselines, achieving 8\% -- 30\% relative WER improvements in ID and 10\% -- 33\% improvements in OOD settings.
External Language Model Integration for Factorized Neural Transducers
May 26, 2023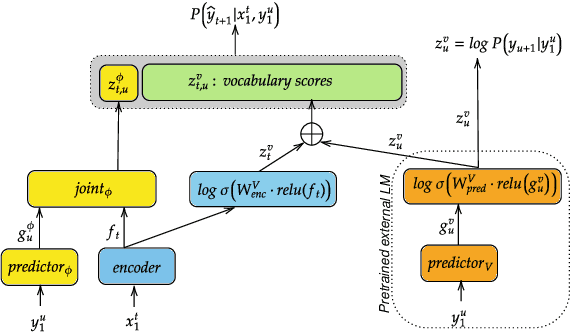
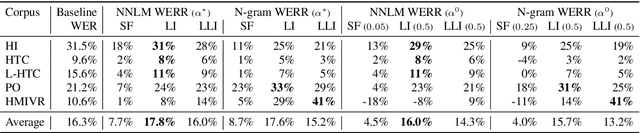

We propose an adaptation method for factorized neural transducers (FNT) with external language models. We demonstrate that both neural and n-gram external LMs add significantly more value when linearly interpolated with predictor output compared to shallow fusion, thus confirming that FNT forces the predictor to act like regular language models. Further, we propose a method to integrate class-based n-gram language models into FNT framework resulting in accuracy gains similar to a hybrid setup. We show average gains of 18% WERR with lexical adaptation across various scenarios and additive gains of up to 60% WERR in one entity-rich scenario through a combination of class-based n-gram and neural LMs.
Bidirectional Language Models Are Also Few-shot Learners
Sep 29, 2022

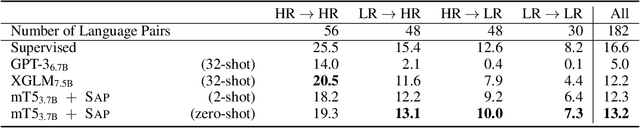
Large language models such as GPT-3 (Brown et al., 2020) can perform arbitrary tasks without undergoing fine-tuning after being prompted with only a few labeled examples. An arbitrary task can be reformulated as a natural language prompt, and a language model can be asked to generate the completion, indirectly performing the task in a paradigm known as prompt-based learning. To date, emergent prompt-based learning capabilities have mainly been demonstrated for unidirectional language models. However, bidirectional language models pre-trained on denoising objectives such as masked language modeling produce stronger learned representations for transfer learning. This motivates the possibility of prompting bidirectional models, but their pre-training objectives have made them largely incompatible with the existing prompting paradigm. We present SAP (Sequential Autoregressive Prompting), a technique that enables the prompting of bidirectional models. Utilizing the machine translation task as a case study, we prompt the bidirectional mT5 model (Xue et al., 2021) with SAP and demonstrate its few-shot and zero-shot translations outperform the few-shot translations of unidirectional models like GPT-3 and XGLM (Lin et al., 2021), despite mT5's approximately 50% fewer parameters. We further show SAP is effective on question answering and summarization. For the first time, our results demonstrate prompt-based learning is an emergent property of a broader class of language models, rather than only unidirectional models.
Multilingual Bidirectional Unsupervised Translation Through Multilingual Finetuning and Back-Translation
Sep 09, 2022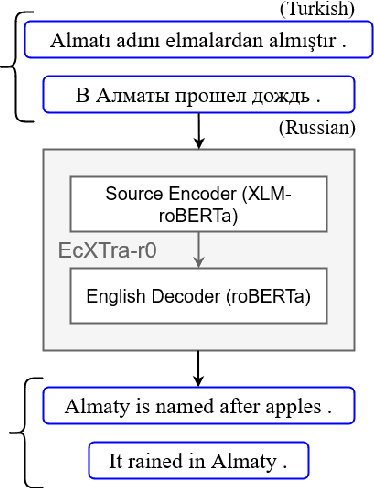

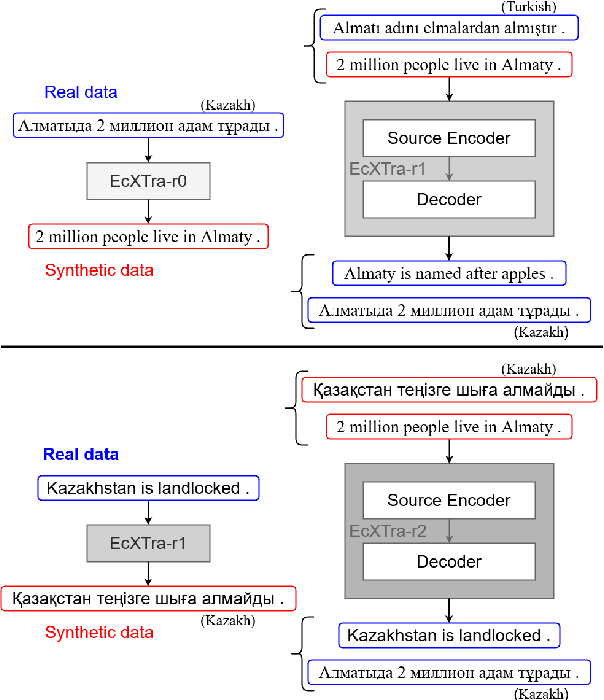
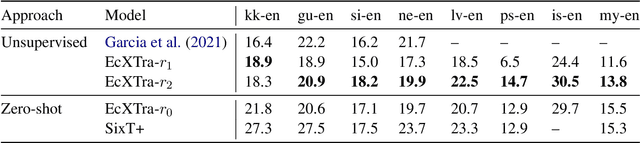
We propose a two-stage training approach for developing a single NMT model to translate unseen languages both to and from English. For the first stage, we initialize an encoder-decoder model to pretrained XLM-R and RoBERTa weights, then perform multilingual fine-tuning on parallel data in 25 languages to English. We find this model can generalize to zero-shot translations on unseen languages. For the second stage, we leverage this generalization ability to generate synthetic parallel data from monolingual datasets, then train with successive rounds of back-translation. The final model extends to the English-to-Many direction, while retaining Many-to-English performance. We term our approach EcXTra (English-centric Crosslingual (X) Transfer). Our approach sequentially leverages auxiliary parallel data and monolingual data, and is conceptually simple, only using a standard cross-entropy objective in both stages. The final EcXTra model is evaluated on unsupervised NMT on 8 low-resource languages achieving a new state-of-the-art for English-to-Kazakh (22.3 > 10.4 BLEU), and competitive performance for the other 15 translation directions.
"Wikily" Neural Machine Translation Tailored to Cross-Lingual Tasks
Apr 16, 2021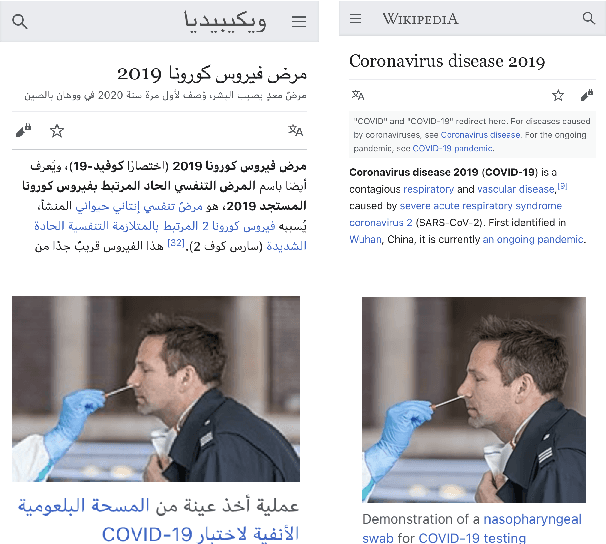

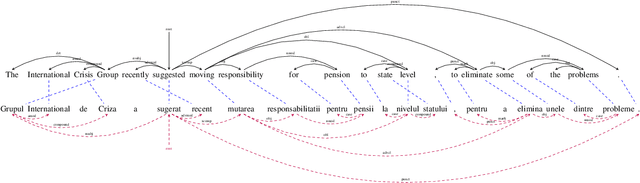
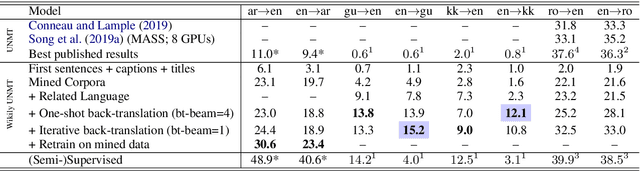
We present a simple but effective approach for leveraging Wikipedia for neural machine translation as well as cross-lingual tasks of image captioning and dependency parsing without using any direct supervision from external parallel data or supervised models in the target language. We show that first sentences and titles of linked Wikipedia pages, as well as cross-lingual image captions, are strong signals for a seed parallel data to extract bilingual dictionaries and cross-lingual word embeddings for mining parallel text from Wikipedia. Our final model achieves high BLEU scores that are close to or sometimes higher than strong supervised baselines in low-resource languages; e.g. supervised BLEU of 4.0 versus 12.1 from our model in English-to-Kazakh. Moreover, we tailor our wikily translation models to unsupervised image captioning and cross-lingual dependency parser transfer. In image captioning, we train a multi-tasking machine translation and image captioning pipeline for Arabic and English from which the Arabic training data is a wikily translation of the English captioning data. Our captioning results in Arabic are slightly better than that of its supervised model. In dependency parsing, we translate a large amount of monolingual text, and use it as an artificial training data in an annotation projection framework. We show that our model outperforms recent work on cross-lingual transfer of dependency parsers.
ParsiNLU: A Suite of Language Understanding Challenges for Persian
Dec 11, 2020
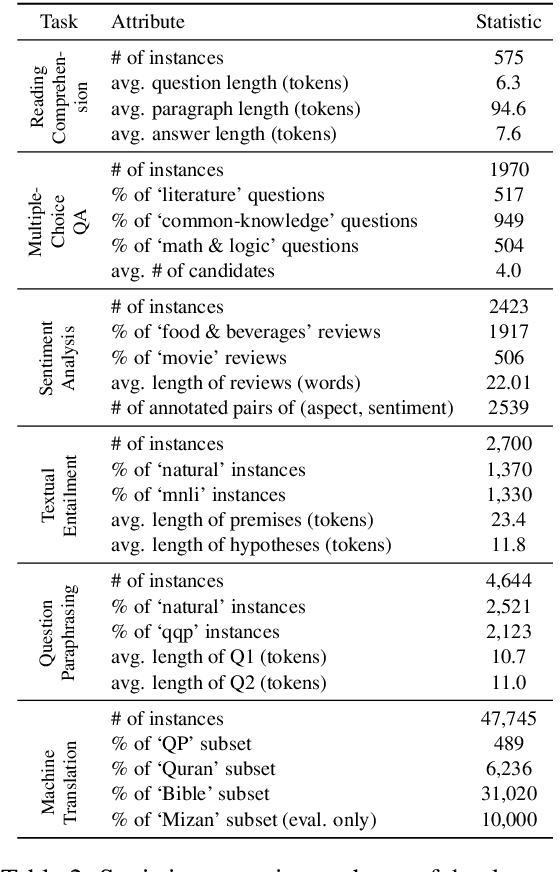
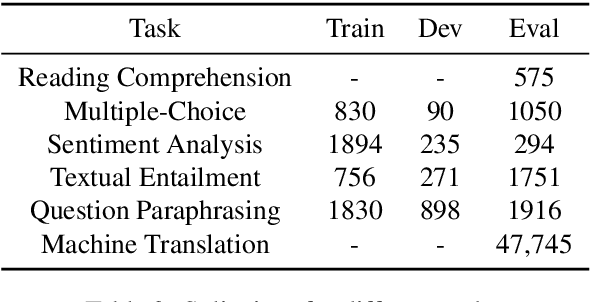
Despite the progress made in recent years in addressing natural language understanding (NLU) challenges, the majority of this progress remains to be concentrated on resource-rich languages like English. This work focuses on Persian language, one of the widely spoken languages in the world, and yet there are few NLU datasets available for this rich language. The availability of high-quality evaluation datasets is a necessity for reliable assessment of the progress on different NLU tasks and domains. We introduce ParsiNLU, the first benchmark in Persian language that includes a range of high-level tasks -- Reading Comprehension, Textual Entailment, etc. These datasets are collected in a multitude of ways, often involving manual annotations by native speakers. This results in over 14.5$k$ new instances across 6 distinct NLU tasks. Besides, we present the first results on state-of-the-art monolingual and multi-lingual pre-trained language-models on this benchmark and compare them with human performance, which provides valuable insights into our ability to tackle natural language understanding challenges in Persian. We hope ParsiNLU fosters further research and advances in Persian language understanding.
Automatic Standardization of Colloquial Persian
Dec 10, 2020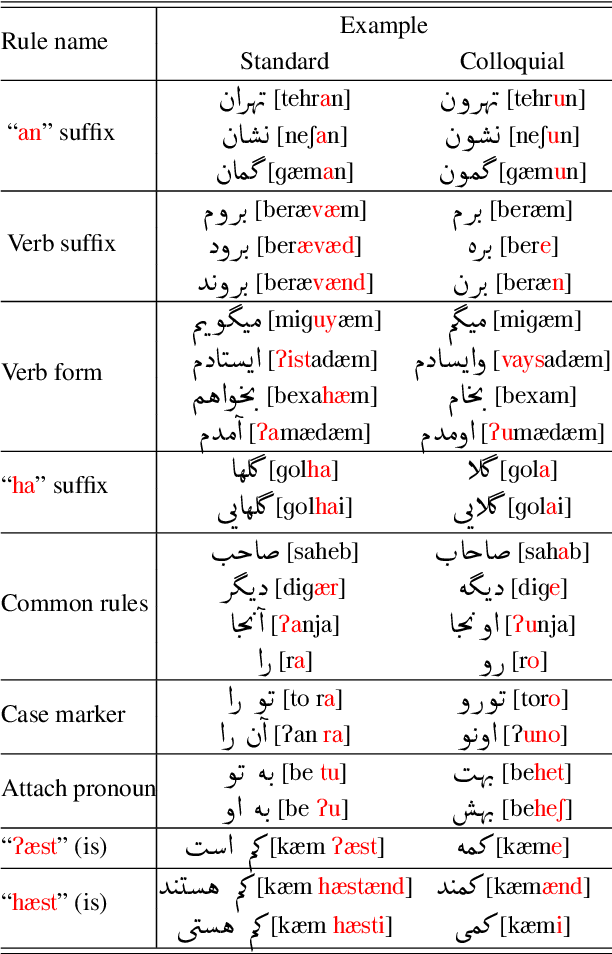

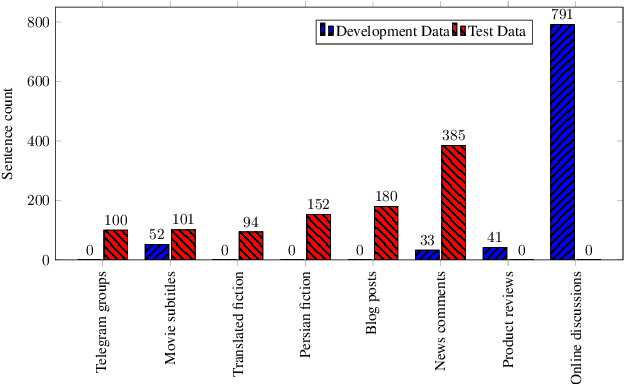

The Iranian Persian language has two varieties: standard and colloquial. Most natural language processing tools for Persian assume that the text is in standard form: this assumption is wrong in many real applications especially web content. This paper describes a simple and effective standardization approach based on sequence-to-sequence translation. We design an algorithm for generating artificial parallel colloquial-to-standard data for learning a sequence-to-sequence model. Moreover, we annotate a publicly available evaluation data consisting of 1912 sentences from a diverse set of domains. Our intrinsic evaluation shows a higher BLEU score of 62.8 versus 61.7 compared to an off-the-shelf rule-based standardization model in which the original text has a BLEU score of 46.4. We also show that our model improves English-to-Persian machine translation in scenarios for which the training data is from colloquial Persian with 1.4 absolute BLEU score difference in the development data, and 0.8 in the test data.
The Persian Dependency Treebank Made Universal
Sep 23, 2020
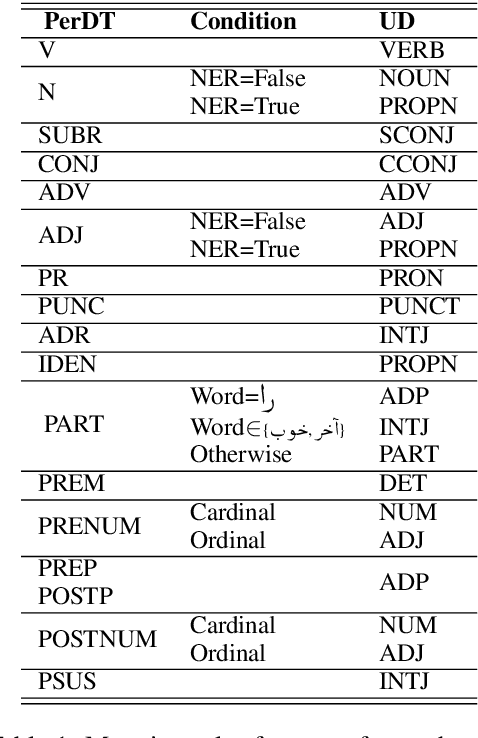

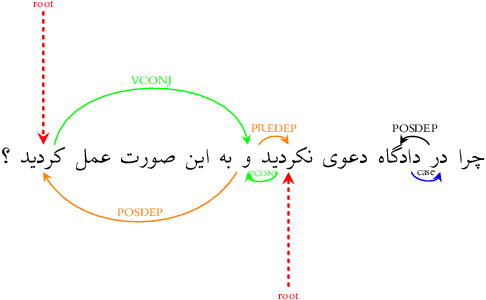
We describe an automatic method for converting the Persian Dependency Treebank (Rasooli et al, 2013) to Universal Dependencies. This treebank contains 29107 sentences. Our experiments along with manual linguistic analysis show that our data is more compatible with Universal Dependencies than the Uppsala Persian Universal Dependency Treebank (Seraji et al., 2016), and is larger in size and more diverse in vocabulary. Our data brings in a labeled attachment F-score of 85.2 in supervised parsing. Our delexicalized Persian-to-English parser transfer experiments show that a parsing model trained on our data is ~2% absolutely more accurate than that of Seraji et al. (2016) in terms of labeled attachment score.
Mutlitask Learning for Cross-Lingual Transfer of Semantic Dependencies
Apr 30, 2020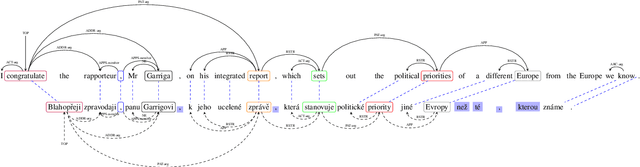
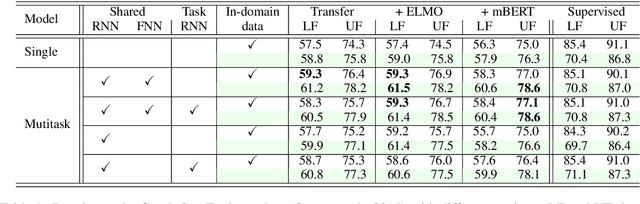
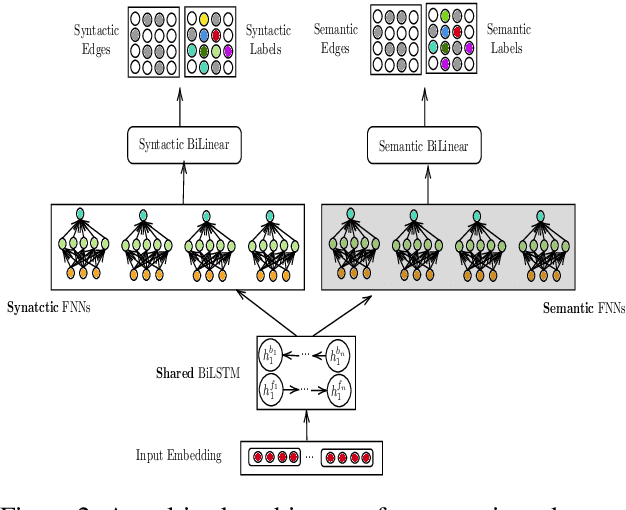
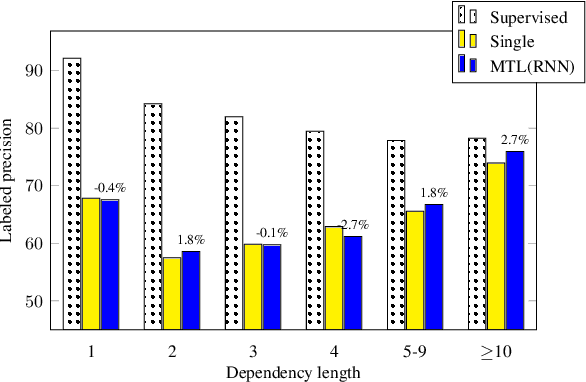
We describe a method for developing broad-coverage semantic dependency parsers for languages for which no semantically annotated resource is available. We leverage a multitask learning framework coupled with an annotation projection method. We transfer supervised semantic dependency parse annotations from a rich-resource language to a low-resource language through parallel data, and train a semantic parser on projected data. We make use of supervised syntactic parsing as an auxiliary task in a multitask learning framework, and show that with different multitask learning settings, we consistently improve over the single-task baseline. In the setting in which English is the source, and Czech is the target language, our best multitask model improves the labeled F1 score over the single-task baseline by 1.8 in the in-domain SemEval data (Oepen et al., 2015), as well as 2.5 in the out-of-domain test set. Moreover, we observe that syntactic and semantic dependency direction match is an important factor in improving the results.
Cross-Lingual Transfer of Semantic Roles: From Raw Text to Semantic Roles
Apr 05, 2019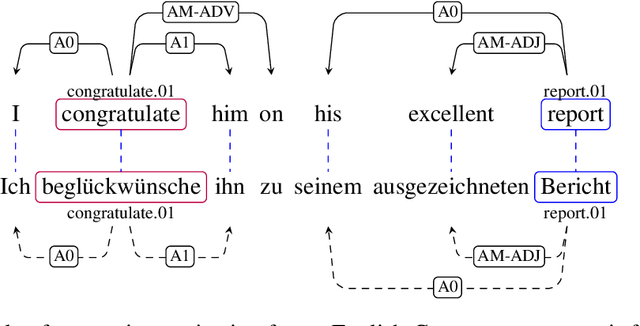
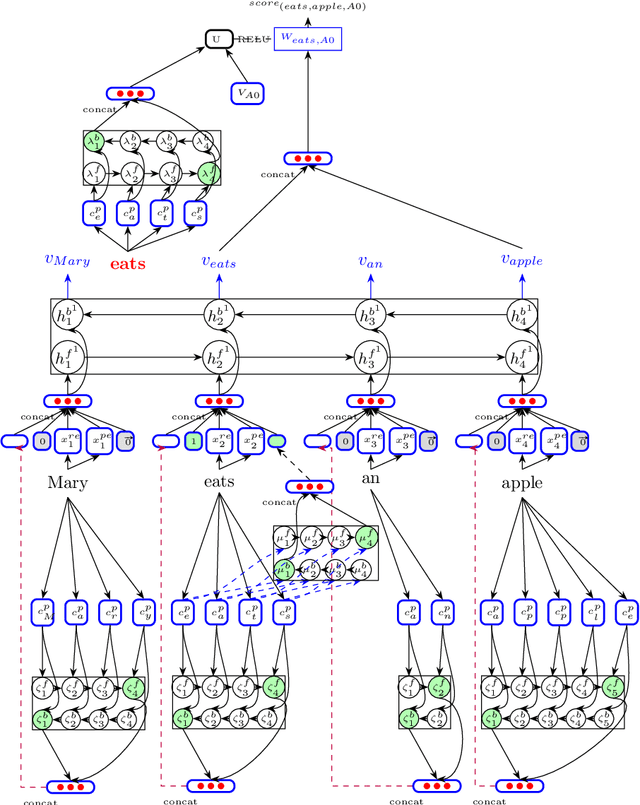

We describe a transfer method based on annotation projection to develop a dependency-based semantic role labeling system for languages for which no supervised linguistic information other than parallel data is available. Unlike previous work that presumes the availability of supervised features such as lemmas, part-of-speech tags, and dependency parse trees, we only make use of word and character features. Our deep model considers using character-based representations as well as unsupervised stem embeddings to alleviate the need for supervised features. Our experiments outperform a state-of-the-art method that uses supervised lexico-syntactic features on 6 out of 7 languages in the Universal Proposition Bank.