 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutlitask Learning for Cross-Lingual Transfer of Semantic Dependencies
Apr 30, 2020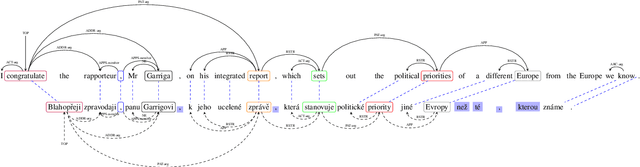
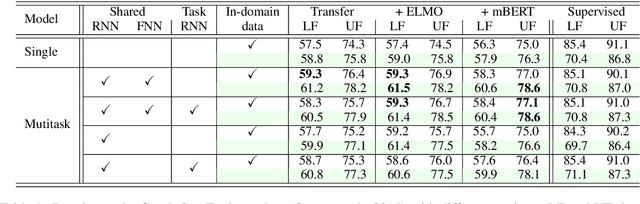
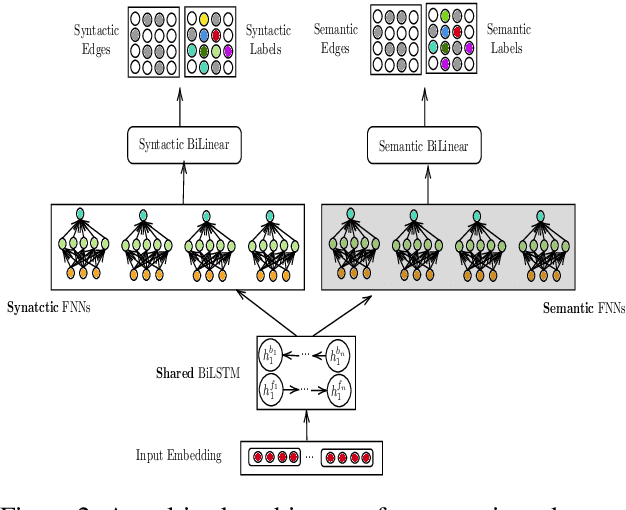
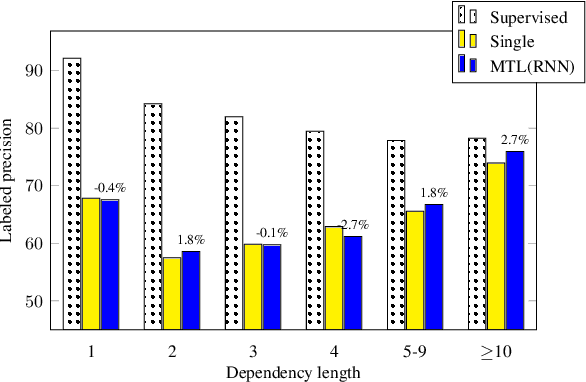
We describe a method for developing broad-coverage semantic dependency parsers for languages for which no semantically annotated resource is available. We leverage a multitask learning framework coupled with an annotation projection method. We transfer supervised semantic dependency parse annotations from a rich-resource language to a low-resource language through parallel data, and train a semantic parser on projected data. We make use of supervised syntactic parsing as an auxiliary task in a multitask learning framework, and show that with different multitask learning settings, we consistently improve over the single-task baseline. In the setting in which English is the source, and Czech is the target language, our best multitask model improves the labeled F1 score over the single-task baseline by 1.8 in the in-domain SemEval data (Oepen et al., 2015), as well as 2.5 in the out-of-domain test set. Moreover, we observe that syntactic and semantic dependency direction match is an important factor in improving the results.
Cross-Lingual Transfer of Semantic Roles: From Raw Text to Semantic Roles
Apr 05, 2019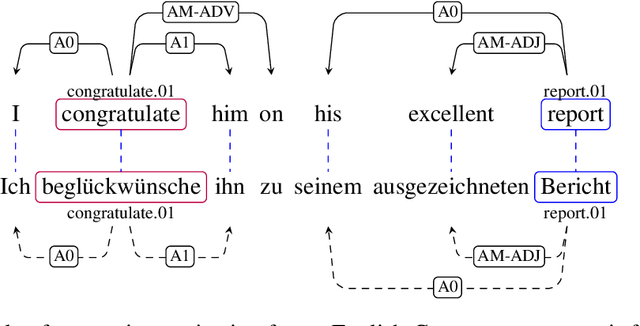
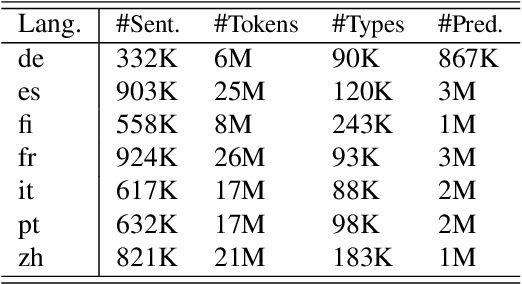
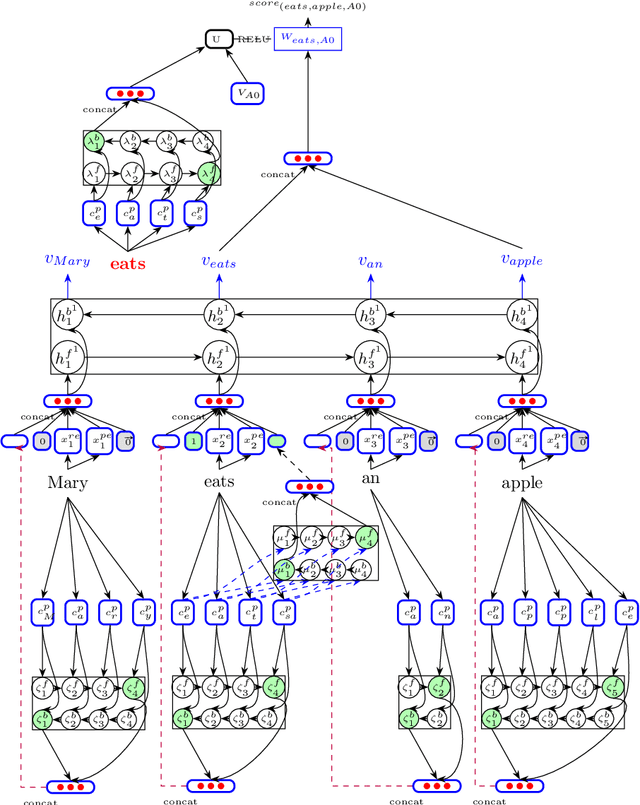

We describe a transfer method based on annotation projection to develop a dependency-based semantic role labeling system for languages for which no supervised linguistic information other than parallel data is available. Unlike previous work that presumes the availability of supervised features such as lemmas, part-of-speech tags, and dependency parse trees, we only make use of word and character features. Our deep model considers using character-based representations as well as unsupervised stem embeddings to alleviate the need for supervised features. Our experiments outperform a state-of-the-art method that uses supervised lexico-syntactic features on 6 out of 7 languages in the Universal Proposition Bank.
Transferring Semantic Roles Using Translation and Syntactic Information
Oct 03, 2017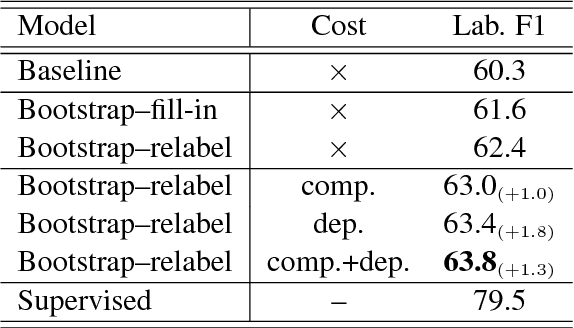
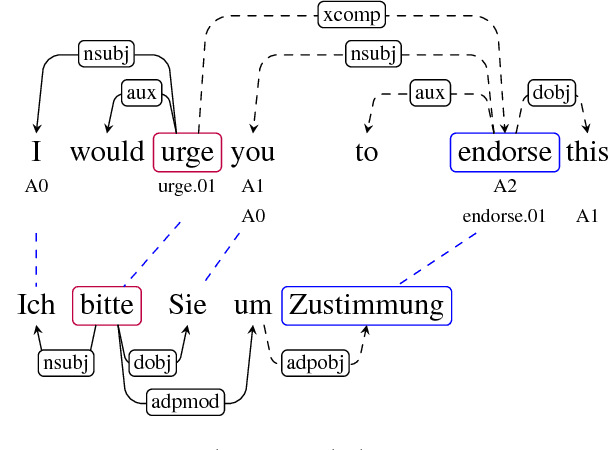
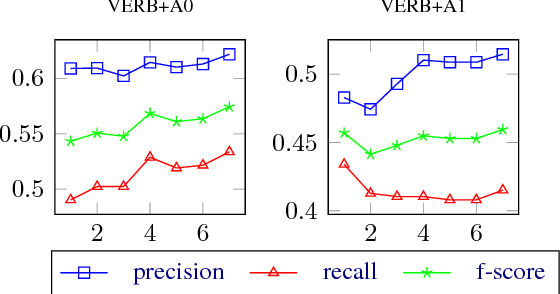
Our paper addresses the problem of annotation projection for semantic role labeling for resource-poor languages using supervised annotations from a resource-rich language through parallel data. We propose a transfer method that employs information from source and target syntactic dependencies as well as word alignment density to improve the quality of an iterative bootstrapping method. Our experiments yield a $3.5$ absolute labeled F-score improvement over a standard annotation projection method.