 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Standardization of Colloquial Persian
Dec 10, 2020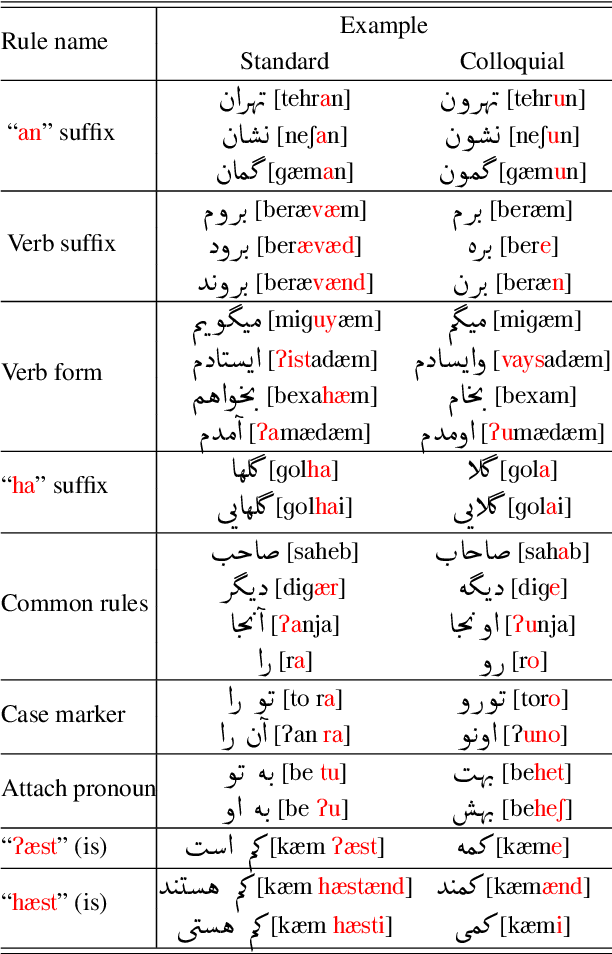

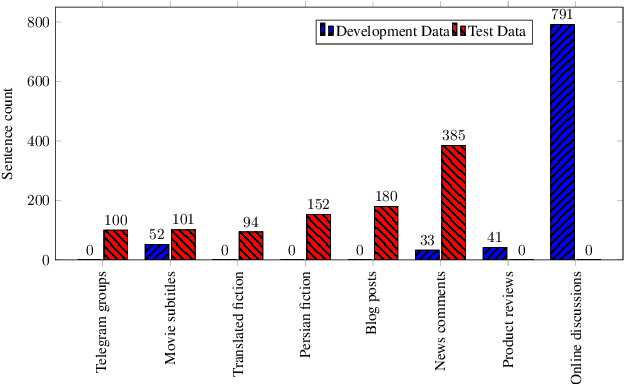

The Iranian Persian language has two varieties: standard and colloquial. Most natural language processing tools for Persian assume that the text is in standard form: this assumption is wrong in many real applications especially web content. This paper describes a simple and effective standardization approach based on sequence-to-sequence translation. We design an algorithm for generating artificial parallel colloquial-to-standard data for learning a sequence-to-sequence model. Moreover, we annotate a publicly available evaluation data consisting of 1912 sentences from a diverse set of domains. Our intrinsic evaluation shows a higher BLEU score of 62.8 versus 61.7 compared to an off-the-shelf rule-based standardization model in which the original text has a BLEU score of 46.4. We also show that our model improves English-to-Persian machine translation in scenarios for which the training data is from colloquial Persian with 1.4 absolute BLEU score difference in the development data, and 0.8 in the test data.