 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExternal Language Model Integration for Factorized Neural Transducers
May 26, 2023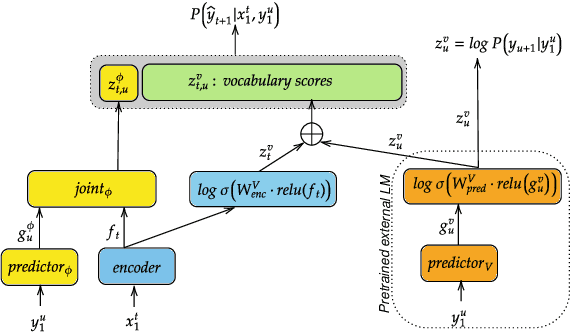
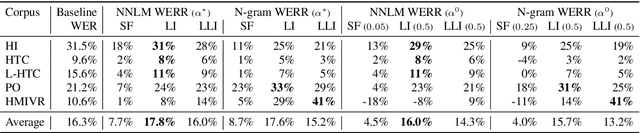
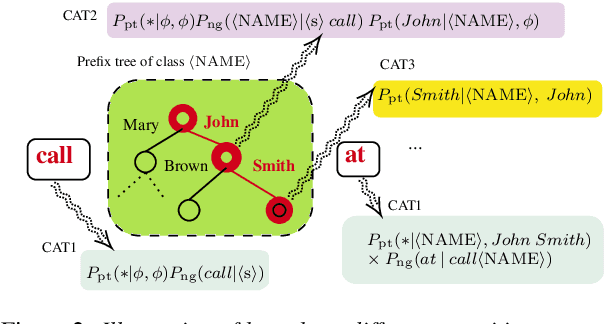

We propose an adaptation method for factorized neural transducers (FNT) with external language models. We demonstrate that both neural and n-gram external LMs add significantly more value when linearly interpolated with predictor output compared to shallow fusion, thus confirming that FNT forces the predictor to act like regular language models. Further, we propose a method to integrate class-based n-gram language models into FNT framework resulting in accuracy gains similar to a hybrid setup. We show average gains of 18% WERR with lexical adaptation across various scenarios and additive gains of up to 60% WERR in one entity-rich scenario through a combination of class-based n-gram and neural LMs.
Multilingual Transformer Language Model for Speech Recognition in Low-resource Languages
Sep 08, 2022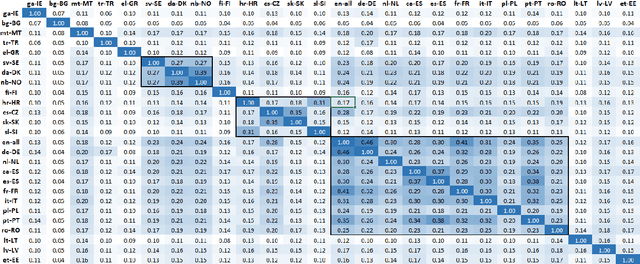

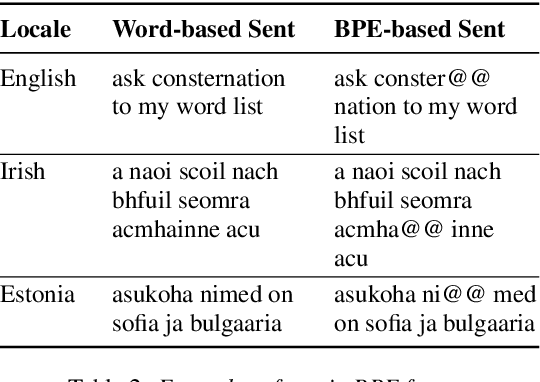
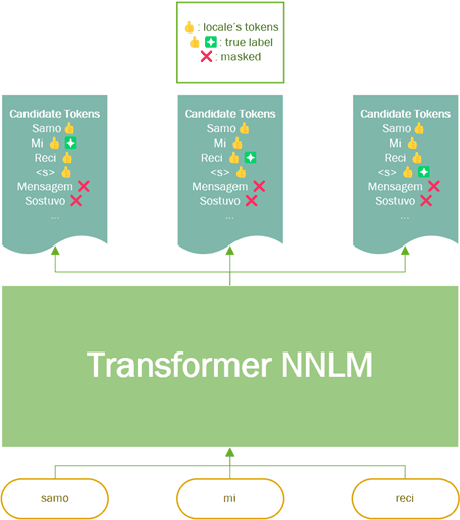
It is challenging to train and deploy Transformer LMs for hybrid speech recognition 2nd pass re-ranking in low-resource languages due to (1) data scarcity in low-resource languages, (2) expensive computing costs for training and refreshing 100+ monolingual models, and (3) hosting inefficiency considering sparse traffic. In this study, we present a new way to group multiple low-resource locales together and optimize the performance of Multilingual Transformer LMs in ASR. Our Locale-group Multilingual Transformer LMs outperform traditional multilingual LMs along with reducing maintenance costs and operating expenses. Further, for low-resource but high-traffic locales where deploying monolingual models is feasible, we show that fine-tuning our locale-group multilingual LMs produces better monolingual LM candidates than baseline monolingual LMs.
Factorized Neural Transducer for Efficient Language Model Adaptation
Oct 18, 2021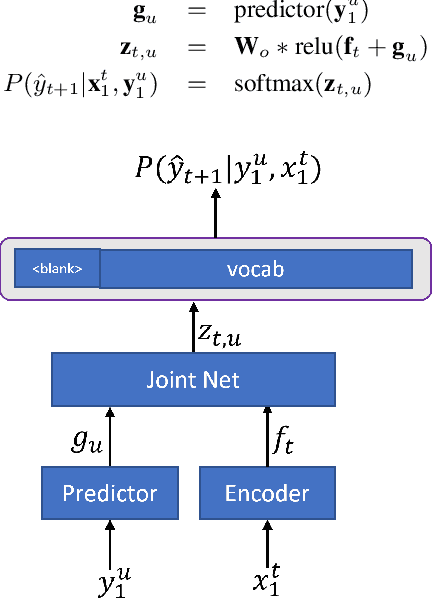

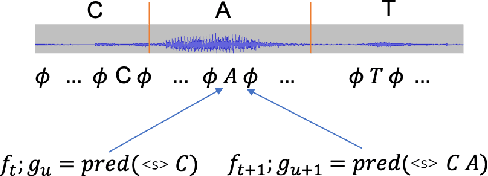
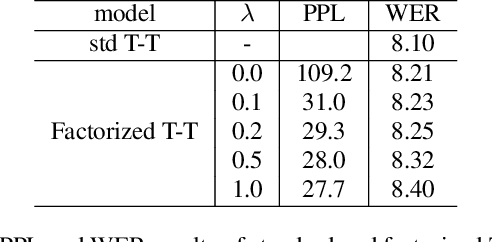
In recent years, end-to-end (E2E) based automatic speech recognition (ASR) systems have achieved great success due to their simplicity and promising performance. Neural Transducer based models are increasingly popular in streaming E2E based ASR systems and have been reported to outperform the traditional hybrid system in some scenarios. However, the joint optimization of acoustic model, lexicon and language model in neural Transducer also brings about challenges to utilize pure text for language model adaptation. This drawback might prevent their potential applications in practice. In order to address this issue, in this paper, we propose a novel model, factorized neural Transducer, by factorizing the blank and vocabulary prediction, and adopting a standalone language model for the vocabulary prediction. It is expected that this factorization can transfer the improvement of the standalone language model to the Transducer for speech recognition, which allows various language model adaptation techniques to be applied. We demonstrate that the proposed factorized neural Transducer yields 15% to 20% WER improvements when out-of-domain text data is used for language model adaptation, at the cost of a minor degradation in WER on a general test set.
Internal Language Model Training for Domain-Adaptive End-to-End Speech Recognition
Feb 02, 2021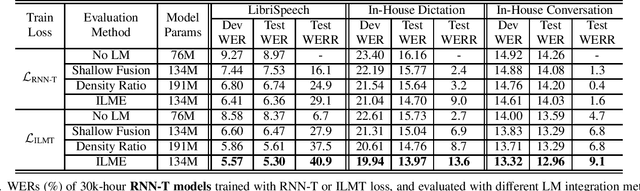
The efficacy of external language model (LM) integration with existing end-to-end (E2E) automatic speech recognition (ASR) systems can be improved significantly using the internal language model estimation (ILME) method. In this method, the internal LM score is subtracted from the score obtained by interpolating the E2E score with the external LM score, during inference. To improve the ILME-based inference, we propose an internal LM training (ILMT) method to minimize an additional internal LM loss by updating only the E2E model components that affect the internal LM estimation. ILMT encourages the E2E model to form a standalone LM inside its existing components, without sacrificing ASR accuracy. After ILMT, the more modular E2E model with matched training and inference criteria enables a more thorough elimination of the source-domain internal LM, and therefore leads to a more effective integration of the target-domain external LM. Experimented with 30K-hour trained recurrent neural network transducer and attention-based encoder-decoder models, ILMT with ILME-based inference achieves up to 31.5% and 11.4% relative word error rate reductions from standard E2E training with Shallow Fusion on out-of-domain LibriSpeech and in-domain Microsoft production test sets, respectively.
* 5 pages, ICASSP 2021
Internal Language Model Estimation for Domain-Adaptive End-to-End Speech Recognition
Nov 03, 2020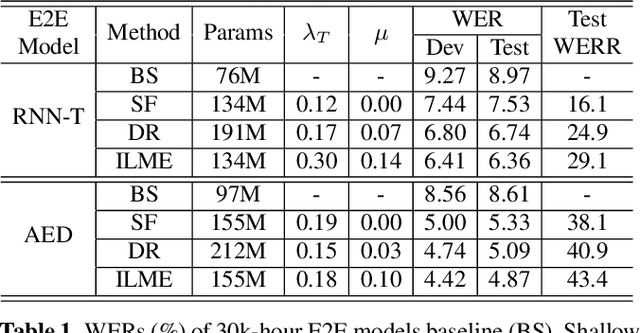
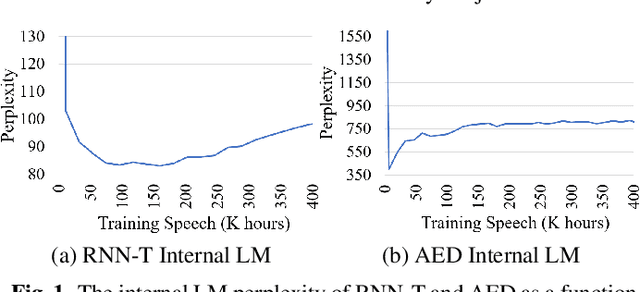
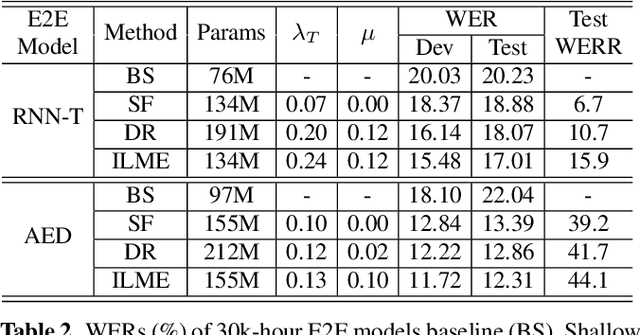
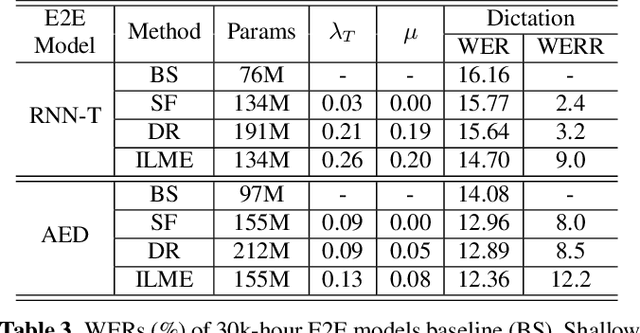
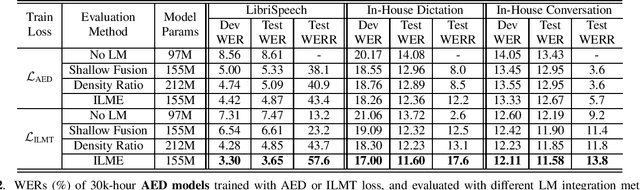
The external language models (LM) integration remains a challenging task for end-to-end (E2E) automatic speech recognition (ASR) which has no clear division between acoustic and language models. In this work, we propose an internal LM estimation (ILME) method to facilitate a more effective integration of the external LM with all pre-existing E2E models with no additional model training, including the most popular recurrent neural network transducer (RNN-T) and attention-based encoder-decoder (AED) models. Trained with audio-transcript pairs, an E2E model implicitly learns an internal LM that characterizes the training data in the source domain. With ILME, the internal LM scores of an E2E model are estimated and subtracted from the log-linear interpolation between the scores of the E2E model and the external LM. The internal LM scores are approximated as the output of an E2E model when eliminating its acoustic components. ILME can alleviate the domain mismatch between training and testing, or improve the multi-domain E2E ASR. Experimented with 30K-hour trained RNN-T and AED models, ILME achieves up to 15.5% and 6.8% relative word error rate reductions from Shallow Fusion on out-of-domain LibriSpeech and in-domain Microsoft production test sets, respectively.
* 8 pages, 2 figures, SLT 2021
LSTM-LM with Long-Term History for First-Pass Decoding in Conversational Speech Recognition
Oct 21, 2020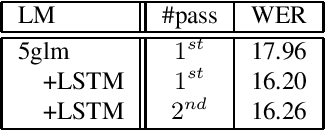
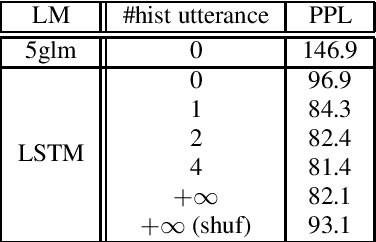
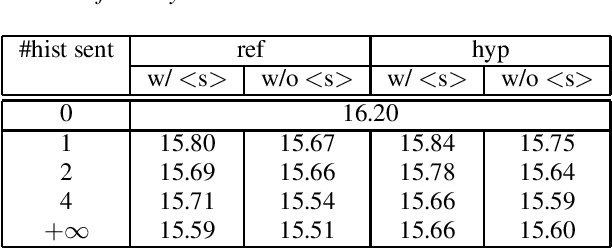

LSTM language models (LSTM-LMs) have been proven to be powerful and yielded significant performance improvements over count based n-gram LMs in modern speech recognition systems. Due to its infinite history states and computational load, most previous studies focus on applying LSTM-LMs in the second-pass for rescoring purpose. Recent work shows that it is feasible and computationally affordable to adopt the LSTM-LMs in the first-pass decoding within a dynamic (or tree based) decoder framework. In this work, the LSTM-LM is composed with a WFST decoder on-the-fly for the first-pass decoding. Furthermore, motivated by the long-term history nature of LSTM-LMs, the use of context beyond the current utterance is explored for the first-pass decoding in conversational speech recognition. The context information is captured by the hidden states of LSTM-LMs across utterance and can be used to guide the first-pass search effectively. The experimental results in our internal meeting transcription system show that significant performance improvements can be obtained by incorporating the contextual information with LSTM-LMs in the first-pass decoding, compared to applying the contextual information in the second-pass rescoring.
Developing RNN-T Models Surpassing High-Performance Hybrid Models with Customization Capability
Jul 30, 2020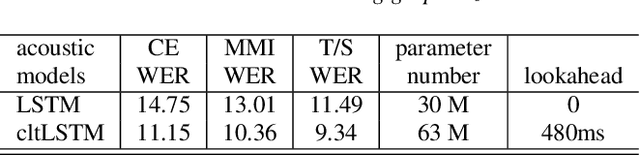
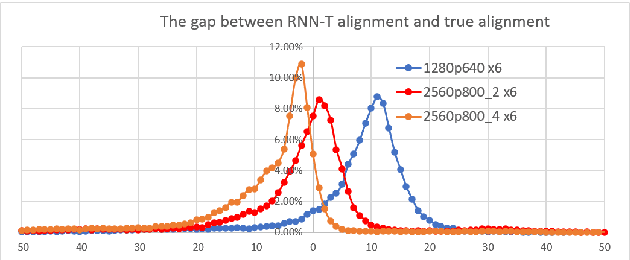
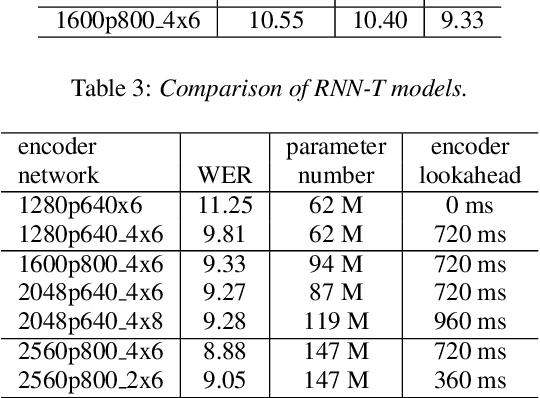
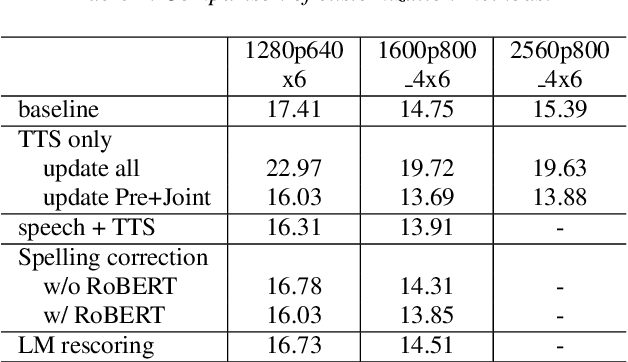
Because of its streaming nature, recurrent neural network transducer (RNN-T) is a very promising end-to-end (E2E) model that may replace the popular hybrid model for automatic speech recognition. In this paper, we describe our recent development of RNN-T models with reduced GPU memory consumption during training, better initialization strategy, and advanced encoder modeling with future lookahead. When trained with Microsoft's 65 thousand hours of anonymized training data, the developed RNN-T model surpasses a very well trained hybrid model with both better recognition accuracy and lower latency. We further study how to customize RNN-T models to a new domain, which is important for deploying E2E models to practical scenarios. By comparing several methods leveraging text-only data in the new domain, we found that updating RNN-T's prediction and joint networks using text-to-speech generated from domain-specific text is the most effective.
Long-span language modeling for speech recognition
Nov 11, 2019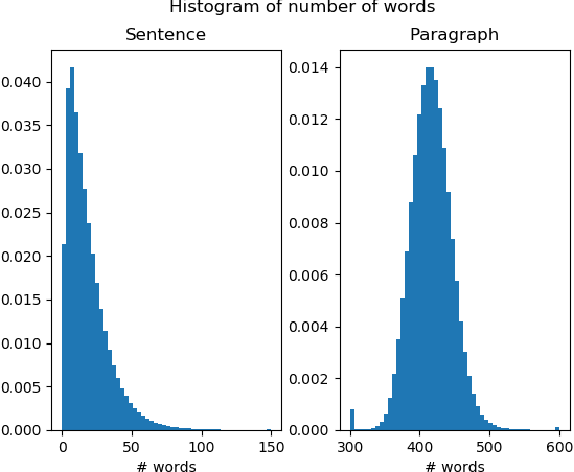
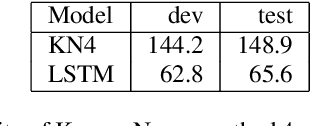
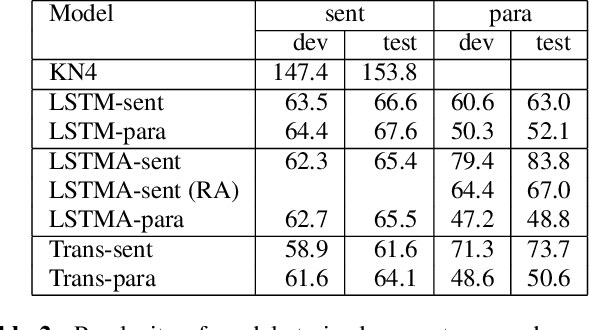
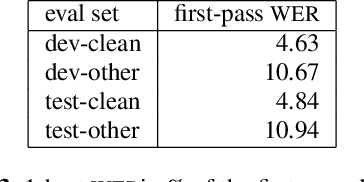
We explore neural language modeling for speech recognition where the context spans multiple sentences. Rather than encode history beyond the current sentence using a cache of words or document-level features, we focus our study on the ability of LSTM and Transformer language models to implicitly learn to carry over context across sentence boundaries. We introduce a new architecture that incorporates an attention mechanism into LSTM to combine the benefits of recurrent and attention architectures. We conduct language modeling and speech recognition experiments on the publicly available LibriSpeech corpus. We show that conventional training on a paragraph-level corpus results in significant reductions in perplexity compared to training on a sentence-level corpus. We also describe speech recognition experiments using long-span language models in second-pass re-ranking, and provide insights into the ability of such models to take advantage of context beyond the current sentence.
Entity-Aware Language Model as an Unsupervised Reranker
Jun 18, 2018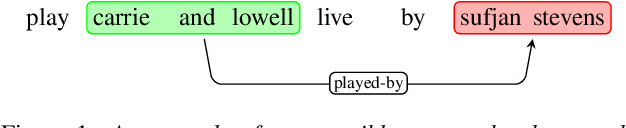

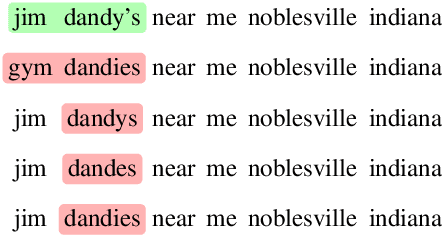

In language modeling, it is difficult to incorporate entity relationships from a knowledge-base. One solution is to use a reranker trained with global features, in which global features are derived from n-best lists. However, training such a reranker requires manually annotated n-best lists, which is expensive to obtain. We propose a method based on the contrastive estimation method that alleviates the need for such data. Experiments in the music domain demonstrate that global features, as well as features extracted from an external knowledge-base, can be incorporated into our reranker. Our final model, a simple ensemble of a language model and reranker, achieves a 0.44\% absolute word error rate improvement over an LSTM language model on the blind test data.