 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Developing Real-time Streaming Transformer Transducer for Speech Recognition on Large-scale Dataset
Oct 22, 2020

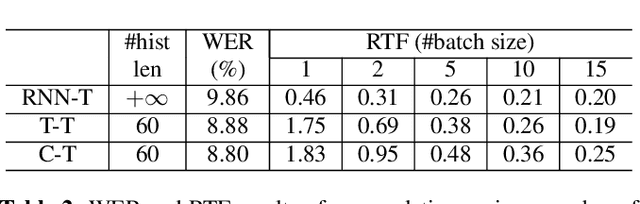

Recently, Transformer based end-to-end models have achieved great success in many areas including speech recognition. However, compared to LSTM models, the heavy computational cost of the Transformer during inference is a key issue to prevent their applications. In this work, we explored the potential of Transformer Transducer (T-T) models for the fist pass decoding with low latency and fast speed on a large-scale dataset. We combine the idea of Transformer-XL and chunk-wise streaming processing to design a streamable Transformer Transducer model. We demonstrate that T-T outperforms the hybrid model, RNN Transducer (RNN-T), and streamable Transformer attention-based encoder-decoder model in the streaming scenario. Furthermore, the runtime cost and latency can be optimized with a relatively small look-ahead.
Developing RNN-T Models Surpassing High-Performance Hybrid Models with Customization Capability
Jul 30, 2020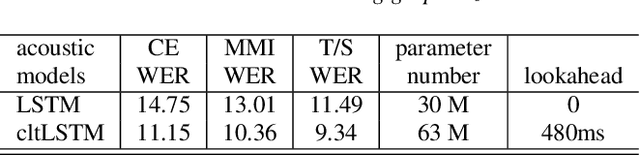
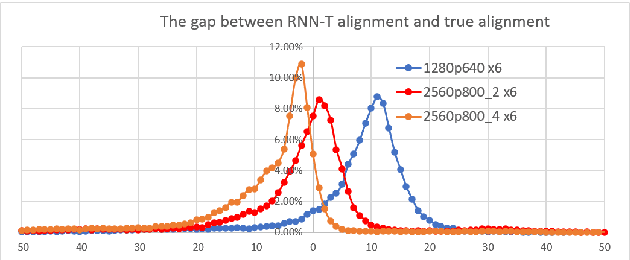
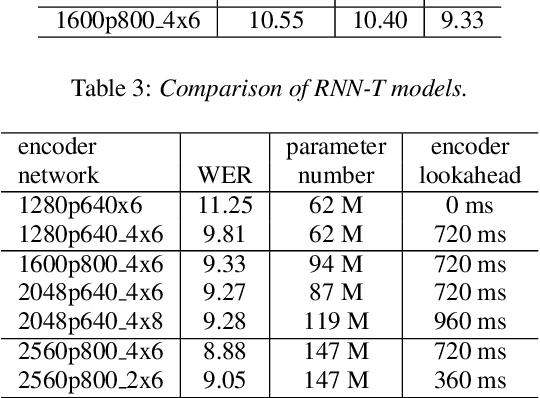
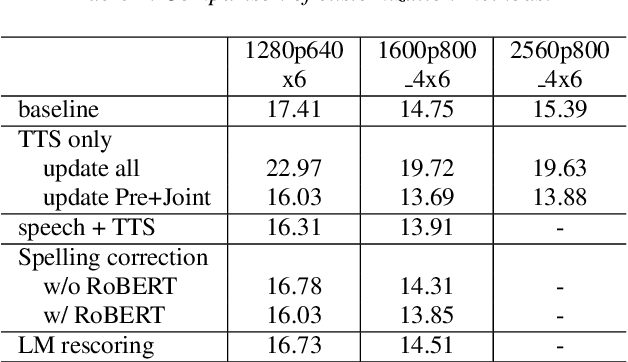
Because of its streaming nature, recurrent neural network transducer (RNN-T) is a very promising end-to-end (E2E) model that may replace the popular hybrid model for automatic speech recognition. In this paper, we describe our recent development of RNN-T models with reduced GPU memory consumption during training, better initialization strategy, and advanced encoder modeling with future lookahead. When trained with Microsoft's 65 thousand hours of anonymized training data, the developed RNN-T model surpasses a very well trained hybrid model with both better recognition accuracy and lower latency. We further study how to customize RNN-T models to a new domain, which is important for deploying E2E models to practical scenarios. By comparing several methods leveraging text-only data in the new domain, we found that updating RNN-T's prediction and joint networks using text-to-speech generated from domain-specific text is the most effective.
Advances in Online Audio-Visual Meeting Transcription
Dec 10, 2019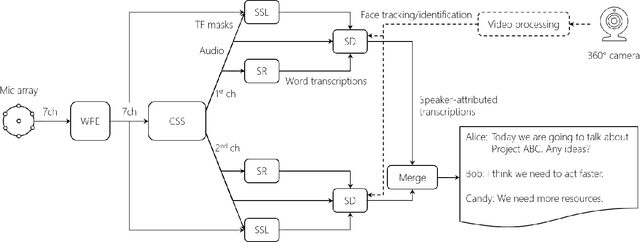

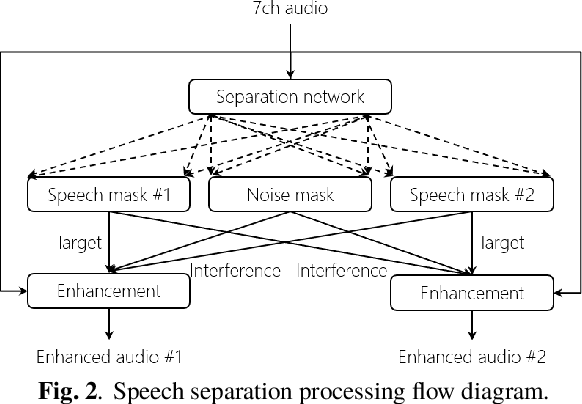
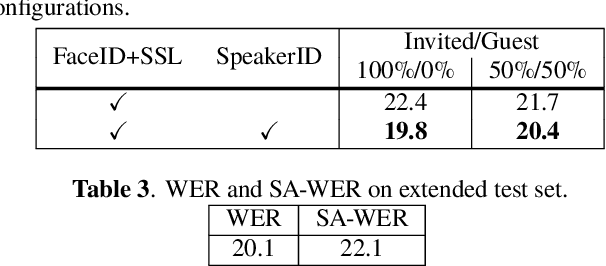
This paper describes a system that generates speaker-annotated transcripts of meetings by using a microphone array and a 360-degree camera. The hallmark of the system is its ability to handle overlapped speech, which has been an unsolved problem in realistic settings for over a decade. We show that this problem can be addressed by using a continuous speech separation approach. In addition, we describe an online audio-visual speaker diarization method that leverages face tracking and identification, sound source localization, speaker identification, and, if available, prior speaker information for robustness to various real world challenges. All components are integrated in a meeting transcription framework called SRD, which stands for "separate, recognize, and diarize". Experimental results using recordings of natural meetings involving up to 11 attendees are reported. The continuous speech separation improves a word error rate (WER) by 16.1% compared with a highly tuned beamformer. When a complete list of meeting attendees is available, the discrepancy between WER and speaker-attributed WER is only 1.0%, indicating accurate word-to-speaker association. This increases marginally to 1.6% when 50% of the attendees are unknown to the system.