 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Have best of both worlds: two-pass hybrid and E2E cascading framework for speech recognition
Oct 10, 2021
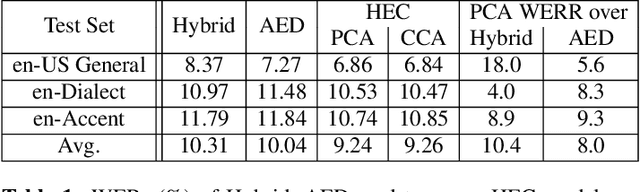
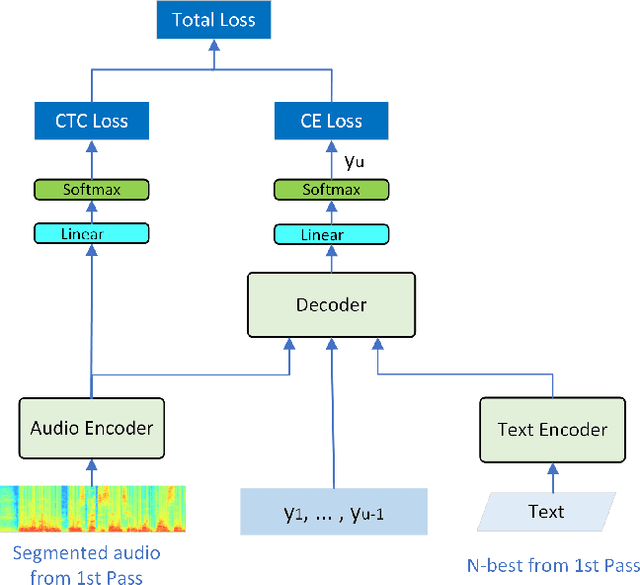
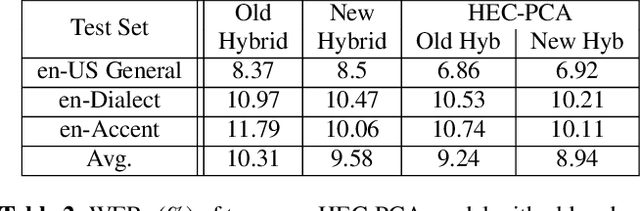
Hybrid and end-to-end (E2E) systems have their individual advantages, with different error patterns in the speech recognition results. By jointly modeling audio and text, the E2E model performs better in matched scenarios and scales well with a large amount of paired audio-text training data. The modularized hybrid model is easier for customization, and better to make use of a massive amount of unpaired text data. This paper proposes a two-pass hybrid and E2E cascading (HEC) framework to combine the hybrid and E2E model in order to take advantage of both sides, with hybrid in the first pass and E2E in the second pass. We show that the proposed system achieves 8-10% relative word error rate reduction with respect to each individual system. More importantly, compared with the pure E2E system, we show the proposed system has the potential to keep the advantages of hybrid system, e.g., customization and segmentation capabilities. We also show the second pass E2E model in HEC is robust with respect to the change in the first pass hybrid model.
Developing RNN-T Models Surpassing High-Performance Hybrid Models with Customization Capability
Jul 30, 2020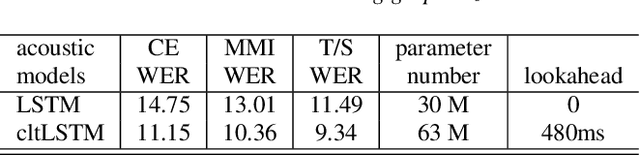
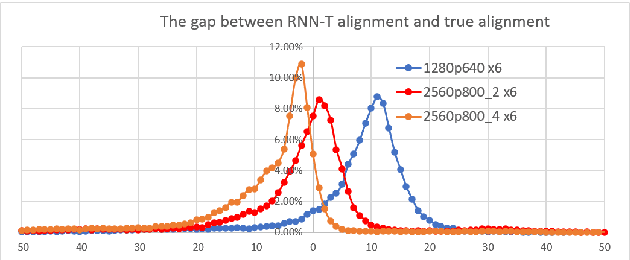
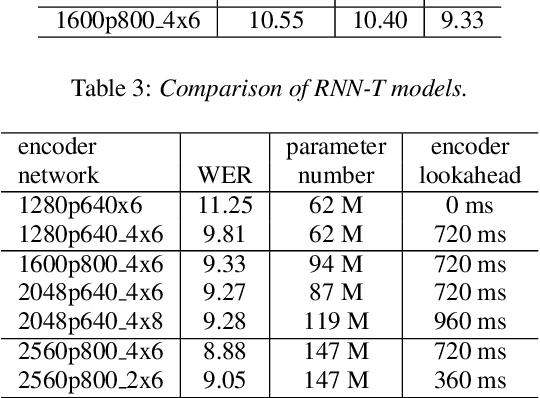
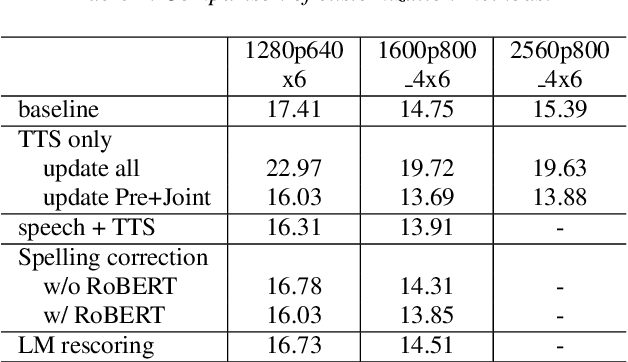
Because of its streaming nature, recurrent neural network transducer (RNN-T) is a very promising end-to-end (E2E) model that may replace the popular hybrid model for automatic speech recognition. In this paper, we describe our recent development of RNN-T models with reduced GPU memory consumption during training, better initialization strategy, and advanced encoder modeling with future lookahead. When trained with Microsoft's 65 thousand hours of anonymized training data, the developed RNN-T model surpasses a very well trained hybrid model with both better recognition accuracy and lower latency. We further study how to customize RNN-T models to a new domain, which is important for deploying E2E models to practical scenarios. By comparing several methods leveraging text-only data in the new domain, we found that updating RNN-T's prediction and joint networks using text-to-speech generated from domain-specific text is the most effective.
Speaker-Invariant Training via Adversarial Learning
Oct 16, 2018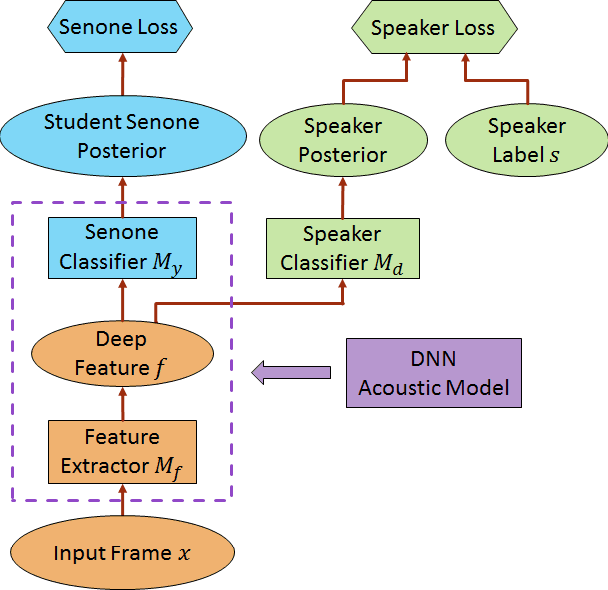
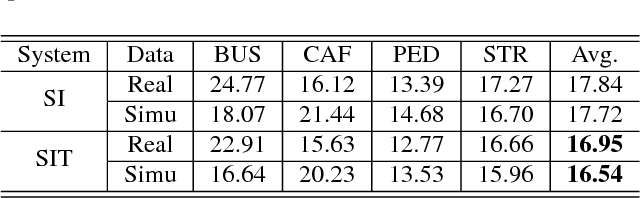
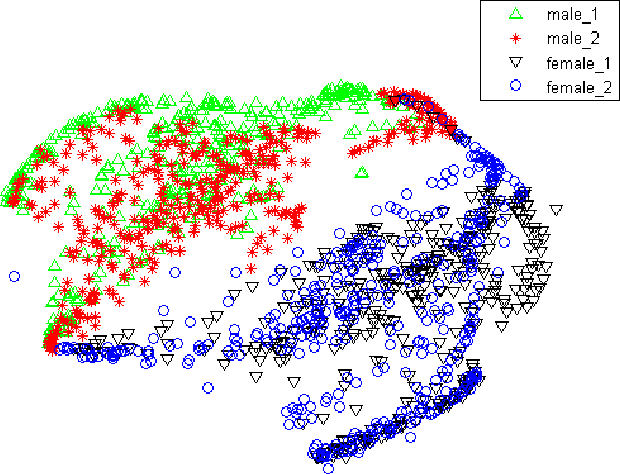
We propose a novel adversarial multi-task learning scheme, aiming at actively curtailing the inter-talker feature variability while maximizing its senone discriminability so as to enhance the performance of a deep neural network (DNN) based ASR system. We call the scheme speaker-invariant training (SIT). In SIT, a DNN acoustic model and a speaker classifier network are jointly optimized to minimize the senone (tied triphone state) classification loss, and simultaneously mini-maximize the speaker classification loss. A speaker-invariant and senone-discriminative deep feature is learned through this adversarial multi-task learning. With SIT, a canonical DNN acoustic model with significantly reduced variance in its output probabilities is learned with no explicit speaker-independent (SI) transformations or speaker-specific representations used in training or testing. Evaluated on the CHiME-3 dataset, the SIT achieves 4.99% relative word error rate (WER) improvement over the conventional SI acoustic model. With additional unsupervised speaker adaptation, the speaker-adapted (SA) SIT model achieves 4.86% relative WER gain over the SA SI acoustic model.
* 5 pages, 3 figures, 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Unsupervised Adaptation with Domain Separation Networks for Robust Speech Recognition
Nov 21, 2017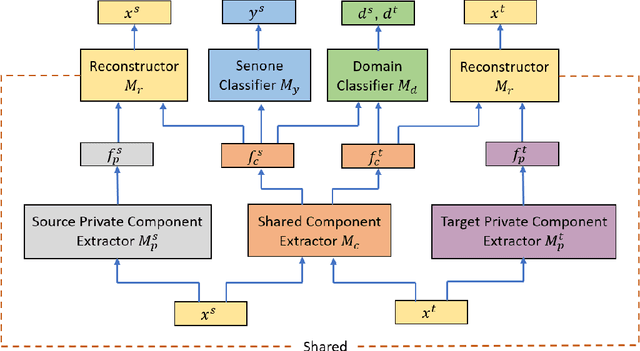
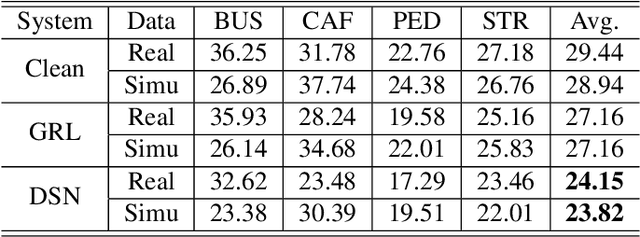
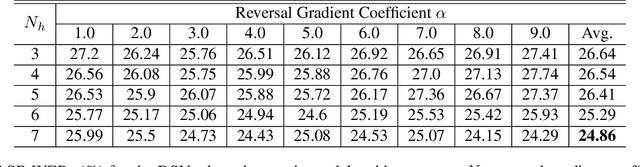
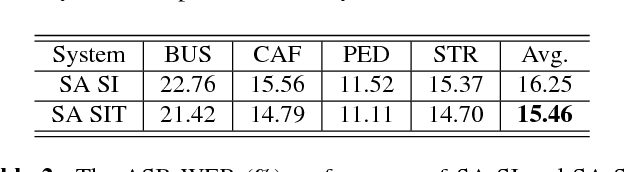
Unsupervised domain adaptation of speech signal aims at adapting a well-trained source-domain acoustic model to the unlabeled data from target domain. This can be achieved by adversarial training of deep neural network (DNN) acoustic models to learn an intermediate deep representation that is both senone-discriminative and domain-invariant. Specifically, the DNN is trained to jointly optimize the primary task of senone classification and the secondary task of domain classification with adversarial objective functions. In this work, instead of only focusing on learning a domain-invariant feature (i.e. the shared component between domains), we also characterize the difference between the source and target domain distributions by explicitly modeling the private component of each domain through a private component extractor DNN. The private component is trained to be orthogonal with the shared component and thus implicitly increases the degree of domain-invariance of the shared component. A reconstructor DNN is used to reconstruct the original speech feature from the private and shared components as a regularization. This domain separation framework is applied to the unsupervised environment adaptation task and achieved 11.08% relative WER reduction from the gradient reversal layer training, a representative adversarial training method, for automatic speech recognition on CHiME-3 dataset.
* in 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU)