 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Voice Authentication
Apr 25, 2020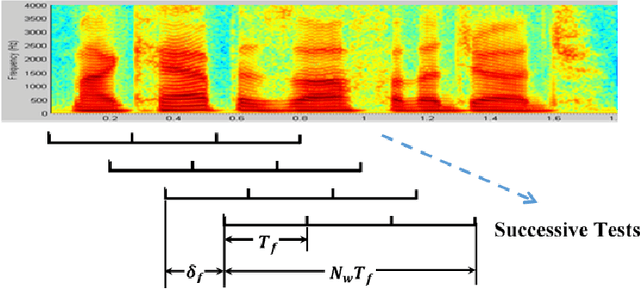
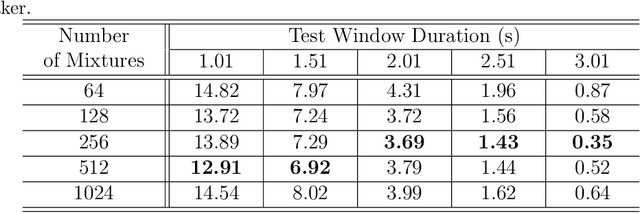
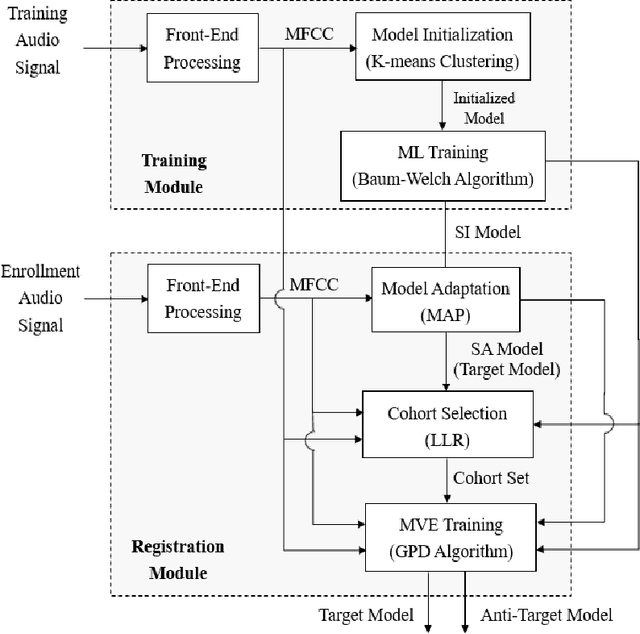
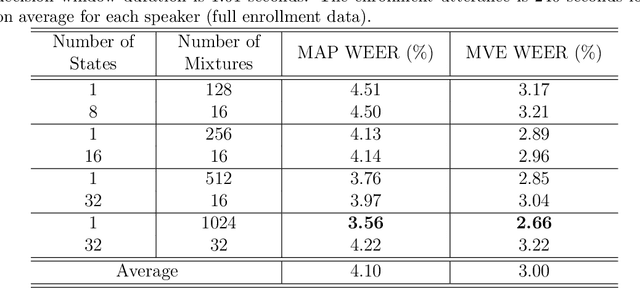
Active authentication refers to a new mode of identity verification in which biometric indicators are continuously tested to provide real-time or near real-time monitoring of an authorized access to a service or use of a device. This is in contrast to the conventional authentication systems where a single test in form of a verification token such as a password is performed. In active voice authentication (AVA), voice is the biometric modality. This paper describes an ensemble of techniques that make reliable speaker verification possible using unconventionally short voice test signals. These techniques include model adaptation and minimum verification error (MVE) training that are tailored for the extremely short training and testing requirements. A database of 25 speakers is recorded for developing this system. In our off-line evaluation on this dataset, the system achieves an average windowed-based equal error rates of 3-4% depending on the model configuration, which is remarkable considering that only 1 second of voice data is used to make every single authentication decision. On the NIST SRE 2001 Dataset, the system provides a 3.88% absolute gain over i-vector when the duration of test segment is 1 second. A real-time demonstration system has been implemented on Microsoft Surface Pro.
* 39 pages, 4 figures
Speaker-Invariant Training via Adversarial Learning
Oct 16, 2018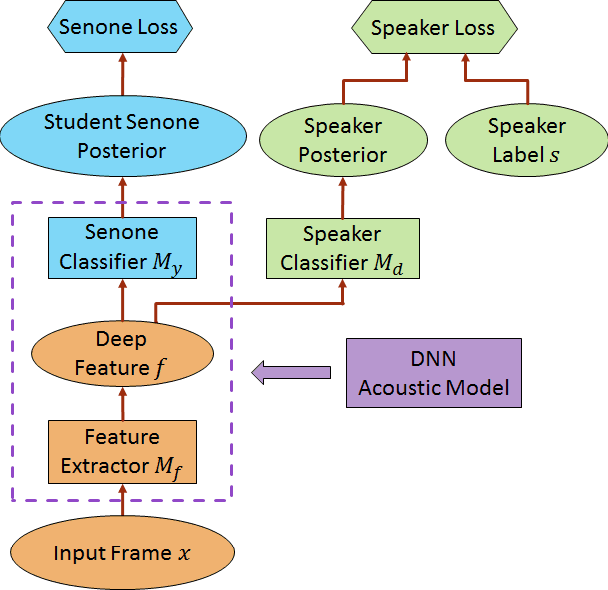
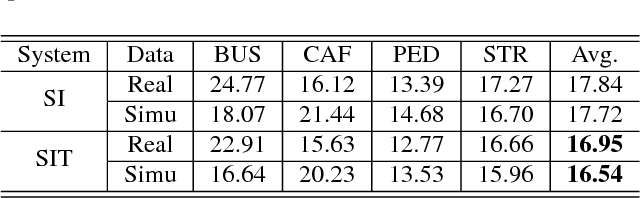
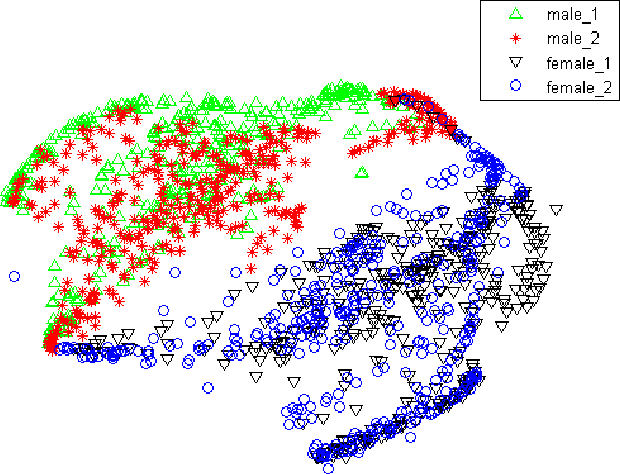
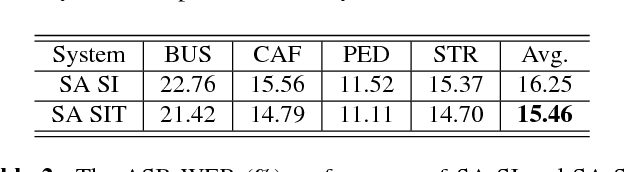
We propose a novel adversarial multi-task learning scheme, aiming at actively curtailing the inter-talker feature variability while maximizing its senone discriminability so as to enhance the performance of a deep neural network (DNN) based ASR system. We call the scheme speaker-invariant training (SIT). In SIT, a DNN acoustic model and a speaker classifier network are jointly optimized to minimize the senone (tied triphone state) classification loss, and simultaneously mini-maximize the speaker classification loss. A speaker-invariant and senone-discriminative deep feature is learned through this adversarial multi-task learning. With SIT, a canonical DNN acoustic model with significantly reduced variance in its output probabilities is learned with no explicit speaker-independent (SI) transformations or speaker-specific representations used in training or testing. Evaluated on the CHiME-3 dataset, the SIT achieves 4.99% relative word error rate (WER) improvement over the conventional SI acoustic model. With additional unsupervised speaker adaptation, the speaker-adapted (SA) SIT model achieves 4.86% relative WER gain over the SA SI acoustic model.
* 5 pages, 3 figures, 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Cycle-Consistent Speech Enhancement
Sep 06, 2018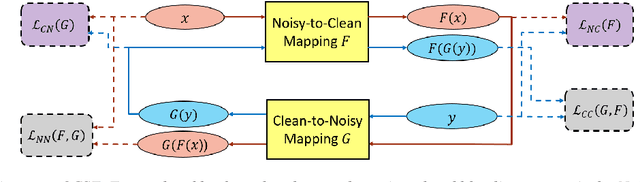


Feature mapping using deep neural networks is an effective approach for single-channel speech enhancement. Noisy features are transformed to the enhanced ones through a mapping network and the mean square errors between the enhanced and clean features are minimized. In this paper, we propose a cycle-consistent speech enhancement (CSE) in which an additional inverse mapping network is introduced to reconstruct the noisy features from the enhanced ones. A cycle-consistent constraint is enforced to minimize the reconstruction loss. Similarly, a backward cycle of mappings is performed in the opposite direction with the same networks and losses. With cycle-consistency, the speech structure is well preserved in the enhanced features while noise is effectively reduced such that the feature-mapping network generalizes better to unseen data. In cases where only unparalleled noisy and clean data is available for training, two discriminator networks are used to distinguish the enhanced and noised features from the clean and noisy ones. The discrimination losses are jointly optimized with reconstruction losses through adversarial multi-task learning. Evaluated on the CHiME-3 dataset, the proposed CSE achieves 19.60% and 6.69% relative word error rate improvements respectively when using or without using parallel clean and noisy speech data.
* 5 pages, 2 figures. arXiv admin note: text overlap with arXiv:1809.02251
Adversarial Feature-Mapping for Speech Enhancement
Sep 06, 2018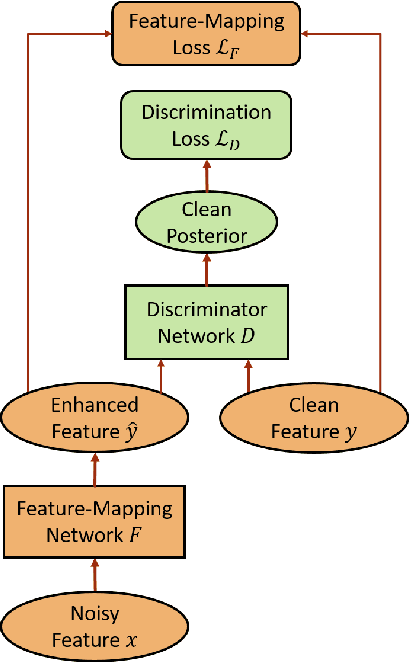
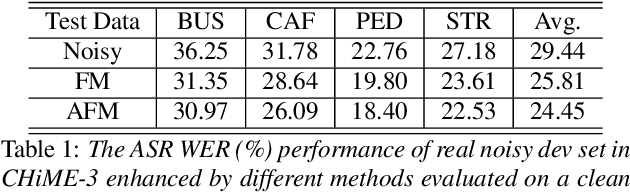
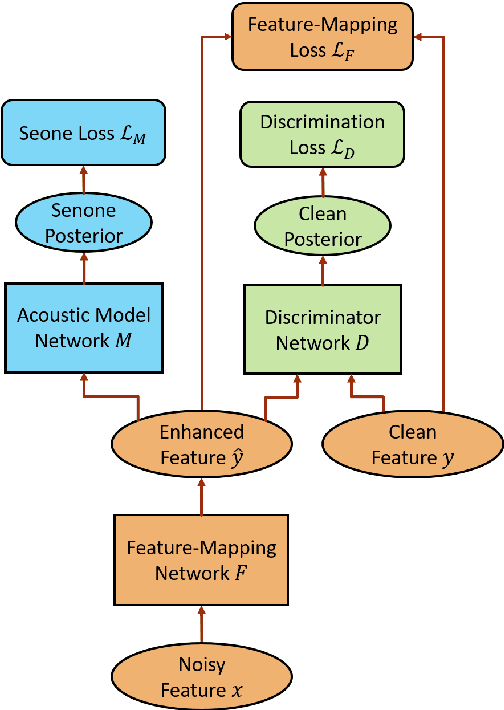
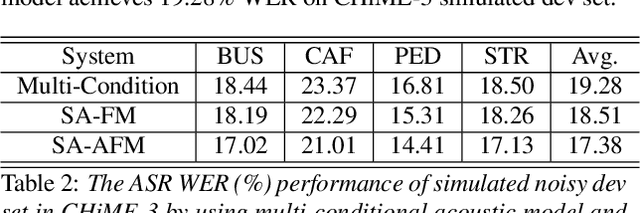
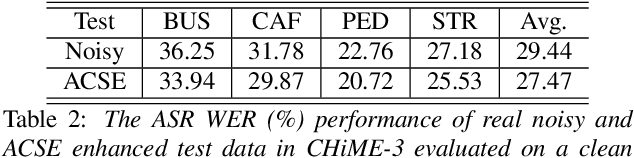
Feature-mapping with deep neural networks is commonly used for single-channel speech enhancement, in which a feature-mapping network directly transforms the noisy features to the corresponding enhanced ones and is trained to minimize the mean square errors between the enhanced and clean features. In this paper, we propose an adversarial feature-mapping (AFM) method for speech enhancement which advances the feature-mapping approach with adversarial learning. An additional discriminator network is introduced to distinguish the enhanced features from the real clean ones. The two networks are jointly optimized to minimize the feature-mapping loss and simultaneously mini-maximize the discrimination loss. The distribution of the enhanced features is further pushed towards that of the clean features through this adversarial multi-task training. To achieve better performance on ASR task, senone-aware (SA) AFM is further proposed in which an acoustic model network is jointly trained with the feature-mapping and discriminator networks to optimize the senone classification loss in addition to the AFM losses. Evaluated on the CHiME-3 dataset, the proposed AFM achieves 16.95% and 5.27% relative word error rate (WER) improvements over the real noisy data and the feature-mapping baseline respectively and the SA-AFM achieves 9.85% relative WER improvement over the multi-conditional acoustic model.
* 5 pages, 2 figures
Adversarial Teacher-Student Learning for Unsupervised Domain Adaptation
Apr 02, 2018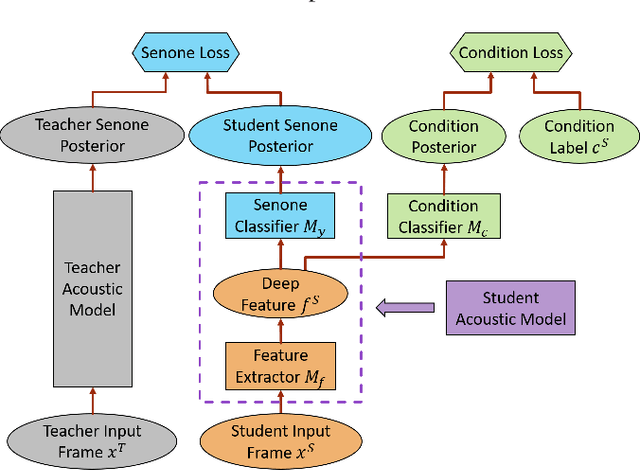

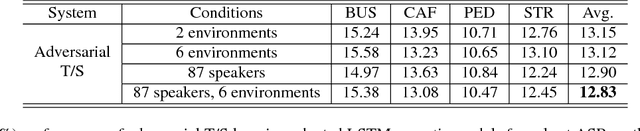
The teacher-student (T/S) learning has been shown effective in unsupervised domain adaptation [1]. It is a form of transfer learning, not in terms of the transfer of recognition decisions, but the knowledge of posteriori probabilities in the source domain as evaluated by the teacher model. It learns to handle the speaker and environment variability inherent in and restricted to the speech signal in the target domain without proactively addressing the robustness to other likely conditions. Performance degradation may thus ensue. In this work, we advance T/S learning by proposing adversarial T/S learning to explicitly achieve condition-robust unsupervised domain adaptation. In this method, a student acoustic model and a condition classifier are jointly optimized to minimize the Kullback-Leibler divergence between the output distributions of the teacher and student models, and simultaneously, to min-maximize the condition classification loss. A condition-invariant deep feature is learned in the adapted student model through this procedure. We further propose multi-factorial adversarial T/S learning which suppresses condition variabilities caused by multiple factors simultaneously. Evaluated with the noisy CHiME-3 test set, the proposed methods achieve relative word error rate improvements of 44.60% and 5.38%, respectively, over a clean source model and a strong T/S learning baseline model.
* 5 pages, 1 figure, 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, Canada, 2018