 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Feature-Mapping for Speech Enhancement
Paper and Code
Sep 06, 2018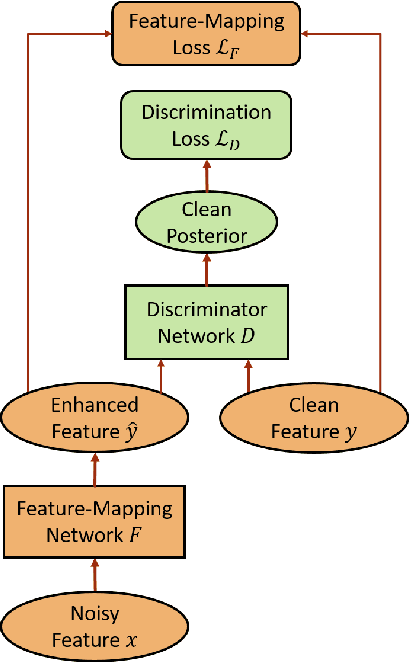
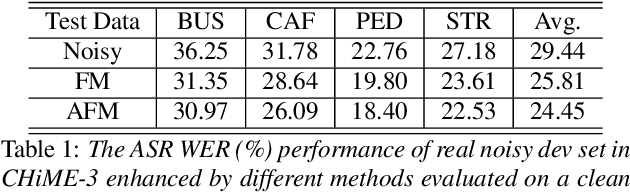
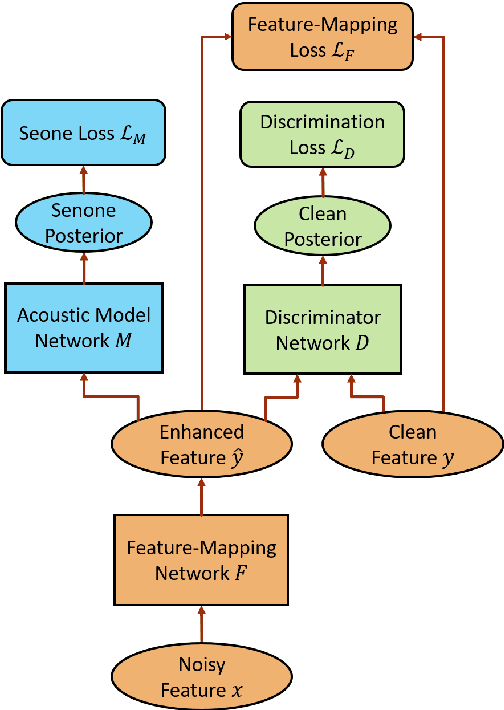
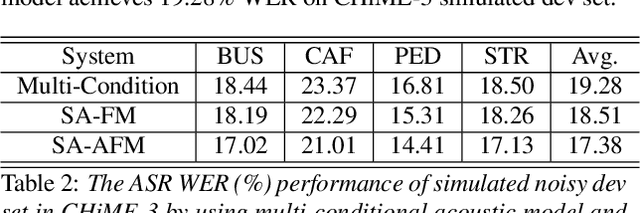
Feature-mapping with deep neural networks is commonly used for single-channel speech enhancement, in which a feature-mapping network directly transforms the noisy features to the corresponding enhanced ones and is trained to minimize the mean square errors between the enhanced and clean features. In this paper, we propose an adversarial feature-mapping (AFM) method for speech enhancement which advances the feature-mapping approach with adversarial learning. An additional discriminator network is introduced to distinguish the enhanced features from the real clean ones. The two networks are jointly optimized to minimize the feature-mapping loss and simultaneously mini-maximize the discrimination loss. The distribution of the enhanced features is further pushed towards that of the clean features through this adversarial multi-task training. To achieve better performance on ASR task, senone-aware (SA) AFM is further proposed in which an acoustic model network is jointly trained with the feature-mapping and discriminator networks to optimize the senone classification loss in addition to the AFM losses. Evaluated on the CHiME-3 dataset, the proposed AFM achieves 16.95% and 5.27% relative word error rate (WER) improvements over the real noisy data and the feature-mapping baseline respectively and the SA-AFM achieves 9.85% relative WER improvement over the multi-conditional acoustic model.