 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHave best of both worlds: two-pass hybrid and E2E cascading framework for speech recognition
Paper and Code
Oct 10, 2021
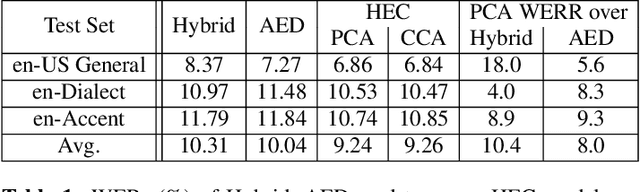
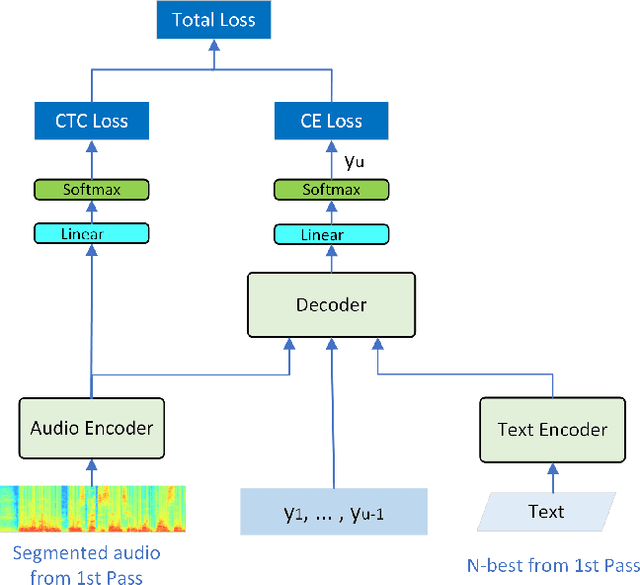
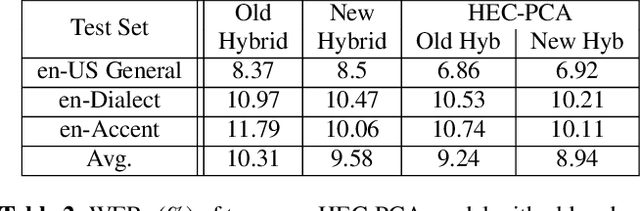
Hybrid and end-to-end (E2E) systems have their individual advantages, with different error patterns in the speech recognition results. By jointly modeling audio and text, the E2E model performs better in matched scenarios and scales well with a large amount of paired audio-text training data. The modularized hybrid model is easier for customization, and better to make use of a massive amount of unpaired text data. This paper proposes a two-pass hybrid and E2E cascading (HEC) framework to combine the hybrid and E2E model in order to take advantage of both sides, with hybrid in the first pass and E2E in the second pass. We show that the proposed system achieves 8-10% relative word error rate reduction with respect to each individual system. More importantly, compared with the pure E2E system, we show the proposed system has the potential to keep the advantages of hybrid system, e.g., customization and segmentation capabilities. We also show the second pass E2E model in HEC is robust with respect to the change in the first pass hybrid model.