 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized Neural Transducer for Efficient Language Model Adaptation
Paper and Code
Oct 18, 2021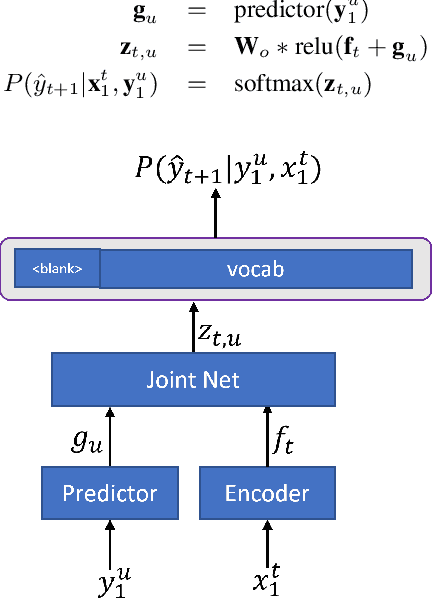

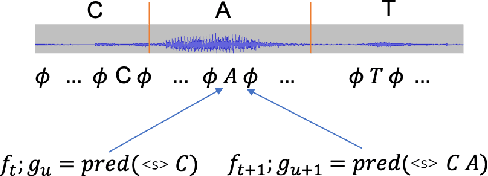
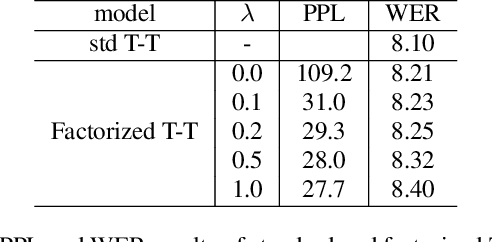
In recent years, end-to-end (E2E) based automatic speech recognition (ASR) systems have achieved great success due to their simplicity and promising performance. Neural Transducer based models are increasingly popular in streaming E2E based ASR systems and have been reported to outperform the traditional hybrid system in some scenarios. However, the joint optimization of acoustic model, lexicon and language model in neural Transducer also brings about challenges to utilize pure text for language model adaptation. This drawback might prevent their potential applications in practice. In order to address this issue, in this paper, we propose a novel model, factorized neural Transducer, by factorizing the blank and vocabulary prediction, and adopting a standalone language model for the vocabulary prediction. It is expected that this factorization can transfer the improvement of the standalone language model to the Transducer for speech recognition, which allows various language model adaptation techniques to be applied. We demonstrate that the proposed factorized neural Transducer yields 15% to 20% WER improvements when out-of-domain text data is used for language model adaptation, at the cost of a minor degradation in WER on a general test set.