 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailing Forward: Improving Generative Error Correction for ASR with Synthetic Data and Retrieval Augmentation
Oct 17, 2024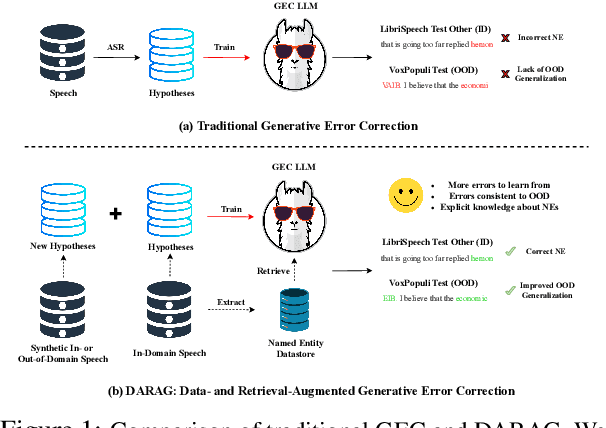
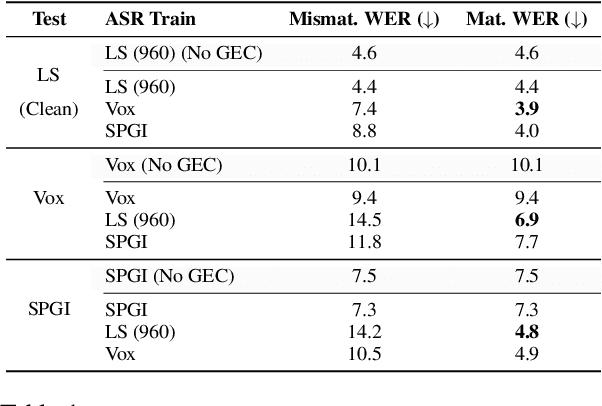
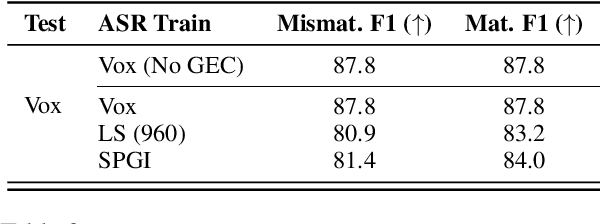
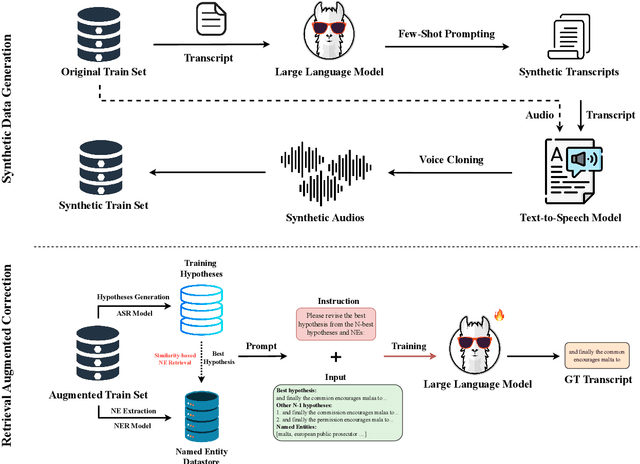
Generative Error Correction (GEC) has emerged as a powerful post-processing method to enhance the performance of Automatic Speech Recognition (ASR) systems. However, we show that GEC models struggle to generalize beyond the specific types of errors encountered during training, limiting their ability to correct new, unseen errors at test time, particularly in out-of-domain (OOD) scenarios. This phenomenon amplifies with named entities (NEs), where, in addition to insufficient contextual information or knowledge about the NEs, novel NEs keep emerging. To address these issues, we propose DARAG (Data- and Retrieval-Augmented Generative Error Correction), a novel approach designed to improve GEC for ASR in in-domain (ID) and OOD scenarios. We augment the GEC training dataset with synthetic data generated by prompting LLMs and text-to-speech models, thereby simulating additional errors from which the model can learn. For OOD scenarios, we simulate test-time errors from new domains similarly and in an unsupervised fashion. Additionally, to better handle named entities, we introduce retrieval-augmented correction by augmenting the input with entities retrieved from a database. Our approach is simple, scalable, and both domain- and language-agnostic. We experiment on multiple datasets and settings, showing that DARAG outperforms all our baselines, achieving 8\% -- 30\% relative WER improvements in ID and 10\% -- 33\% improvements in OOD settings.
External Language Model Integration for Factorized Neural Transducers
May 26, 2023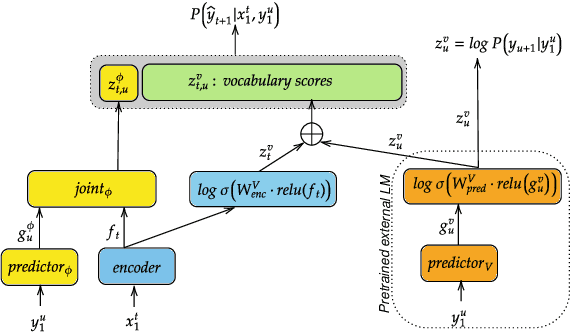
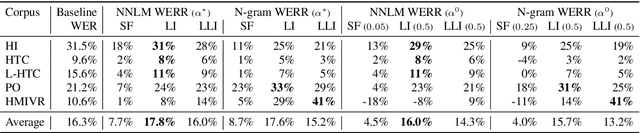
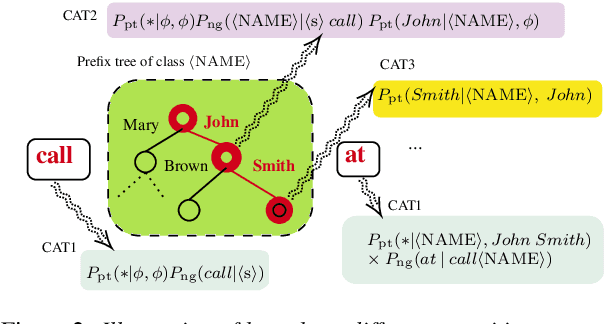

We propose an adaptation method for factorized neural transducers (FNT) with external language models. We demonstrate that both neural and n-gram external LMs add significantly more value when linearly interpolated with predictor output compared to shallow fusion, thus confirming that FNT forces the predictor to act like regular language models. Further, we propose a method to integrate class-based n-gram language models into FNT framework resulting in accuracy gains similar to a hybrid setup. We show average gains of 18% WERR with lexical adaptation across various scenarios and additive gains of up to 60% WERR in one entity-rich scenario through a combination of class-based n-gram and neural LMs.