 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExternal Language Model Integration for Factorized Neural Transducers
May 26, 2023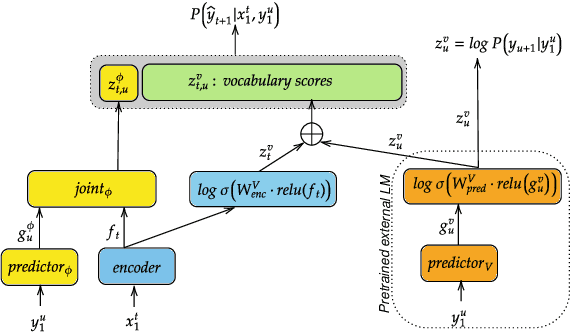
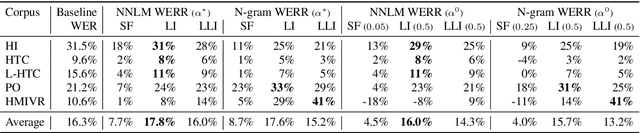
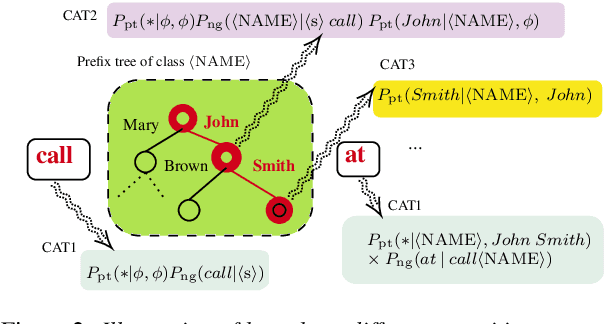

We propose an adaptation method for factorized neural transducers (FNT) with external language models. We demonstrate that both neural and n-gram external LMs add significantly more value when linearly interpolated with predictor output compared to shallow fusion, thus confirming that FNT forces the predictor to act like regular language models. Further, we propose a method to integrate class-based n-gram language models into FNT framework resulting in accuracy gains similar to a hybrid setup. We show average gains of 18% WERR with lexical adaptation across various scenarios and additive gains of up to 60% WERR in one entity-rich scenario through a combination of class-based n-gram and neural LMs.
Streaming Punctuation: A Novel Punctuation Technique Leveraging Bidirectional Context for Continuous Speech Recognition
Jan 10, 2023



While speech recognition Word Error Rate (WER) has reached human parity for English, continuous speech recognition scenarios such as voice typing and meeting transcriptions still suffer from segmentation and punctuation problems, resulting from irregular pausing patterns or slow speakers. Transformer sequence tagging models are effective at capturing long bi-directional context, which is crucial for automatic punctuation. Automatic Speech Recognition (ASR) production systems, however, are constrained by real-time requirements, making it hard to incorporate the right context when making punctuation decisions. Context within the segments produced by ASR decoders can be helpful but limiting in overall punctuation performance for a continuous speech session. In this paper, we propose a streaming approach for punctuation or re-punctuation of ASR output using dynamic decoding windows and measure its impact on punctuation and segmentation accuracy across scenarios. The new system tackles over-segmentation issues, improving segmentation F0.5-score by 13.9%. Streaming punctuation achieves an average BLEUscore improvement of 0.66 for the downstream task of Machine Translation (MT).
* arXiv admin note: substantial text overlap with arXiv:2210.05756
Smart Speech Segmentation using Acousto-Linguistic Features with look-ahead
Oct 27, 2022



Segmentation for continuous Automatic Speech Recognition (ASR) has traditionally used silence timeouts or voice activity detectors (VADs), which are both limited to acoustic features. This segmentation is often overly aggressive, given that people naturally pause to think as they speak. Consequently, segmentation happens mid-sentence, hindering both punctuation and downstream tasks like machine translation for which high-quality segmentation is critical. Model-based segmentation methods that leverage acoustic features are powerful, but without an understanding of the language itself, these approaches are limited. We present a hybrid approach that leverages both acoustic and language information to improve segmentation. Furthermore, we show that including one word as a look-ahead boosts segmentation quality. On average, our models improve segmentation-F0.5 score by 9.8% over baseline. We show that this approach works for multiple languages. For the downstream task of machine translation, it improves the translation BLEU score by an average of 1.05 points.
TRScore: A Novel GPT-based Readability Scorer for ASR Segmentation and Punctuation model evaluation and selection
Oct 27, 2022
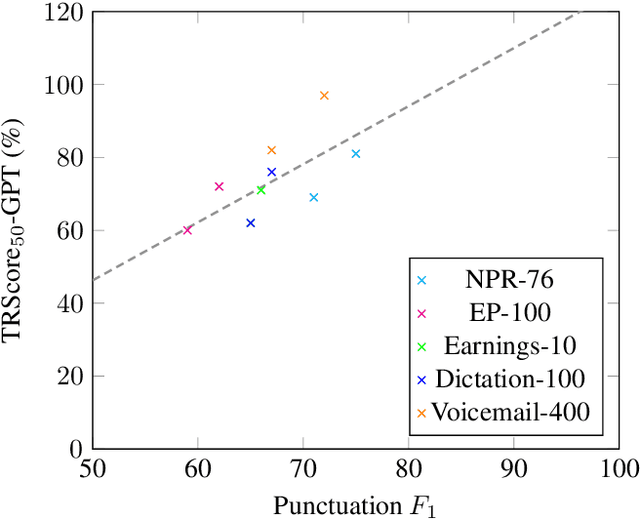
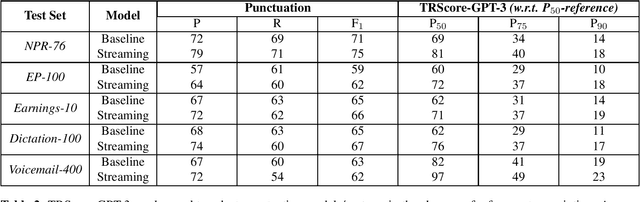
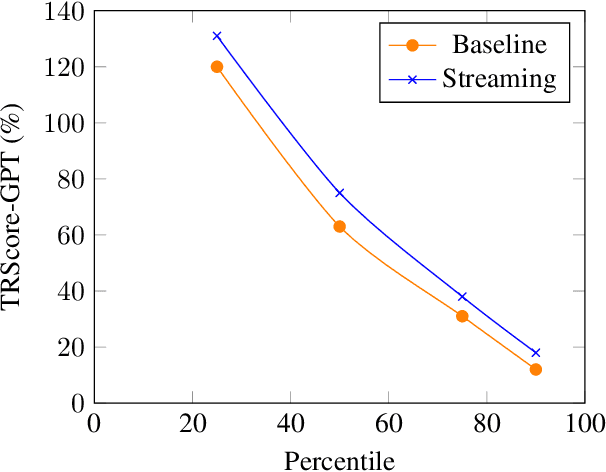
Punctuation and Segmentation are key to readability in Automatic Speech Recognition (ASR), often evaluated using F1 scores that require high-quality human transcripts and do not reflect readability well. Human evaluation is expensive, time-consuming, and suffers from large inter-observer variability, especially in conversational speech devoid of strict grammatical structures. Large pre-trained models capture a notion of grammatical structure. We present TRScore, a novel readability measure using the GPT model to evaluate different segmentation and punctuation systems. We validate our approach with human experts. Additionally, our approach enables quantitative assessment of text post-processing techniques such as capitalization, inverse text normalization (ITN), and disfluency on overall readability, which traditional word error rate (WER) and slot error rate (SER) metrics fail to capture. TRScore is strongly correlated to traditional F1 and human readability scores, with Pearson's correlation coefficients of 0.67 and 0.98, respectively. It also eliminates the need for human transcriptions for model selection.
Four-in-One: A Joint Approach to Inverse Text Normalization, Punctuation, Capitalization, and Disfluency for Automatic Speech Recognition
Oct 26, 2022



Features such as punctuation, capitalization, and formatting of entities are important for readability, understanding, and natural language processing tasks. However, Automatic Speech Recognition (ASR) systems produce spoken-form text devoid of formatting, and tagging approaches to formatting address just one or two features at a time. In this paper, we unify spoken-to-written text conversion via a two-stage process: First, we use a single transformer tagging model to jointly produce token-level tags for inverse text normalization (ITN), punctuation, capitalization, and disfluencies. Then, we apply the tags to generate written-form text and use weighted finite state transducer (WFST) grammars to format tagged ITN entity spans. Despite joining four models into one, our unified tagging approach matches or outperforms task-specific models across all four tasks on benchmark test sets across several domains.
Streaming Punctuation for Long-form Dictation with Transformers
Oct 11, 2022



While speech recognition Word Error Rate (WER) has reached human parity for English, long-form dictation scenarios still suffer from segmentation and punctuation problems resulting from irregular pausing patterns or slow speakers. Transformer sequence tagging models are effective at capturing long bi-directional context, which is crucial for automatic punctuation. A typical Automatic Speech Recognition (ASR) production system, however, is constrained by real-time requirements, making it hard to incorporate the right context when making punctuation decisions. In this paper, we propose a streaming approach for punctuation or re-punctuation of ASR output using dynamic decoding windows and measure its impact on punctuation and segmentation accuracy in a variety of scenarios. The new system tackles over-segmentation issues, improving segmentation F0.5-score by 13.9%. Streaming punctuation achieves an average BLEU-score gain of 0.66 for the downstream task of Machine Translation (MT).
Multilingual Transformer Language Model for Speech Recognition in Low-resource Languages
Sep 08, 2022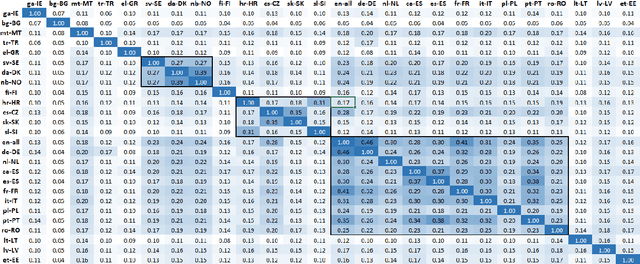

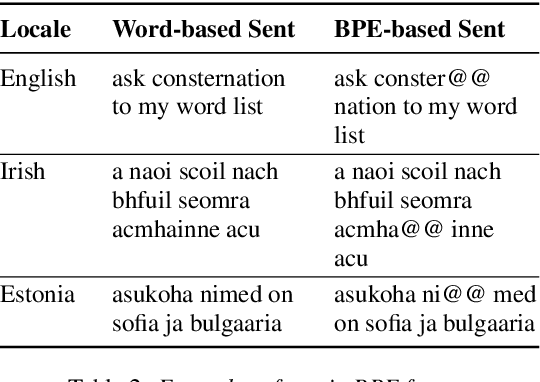
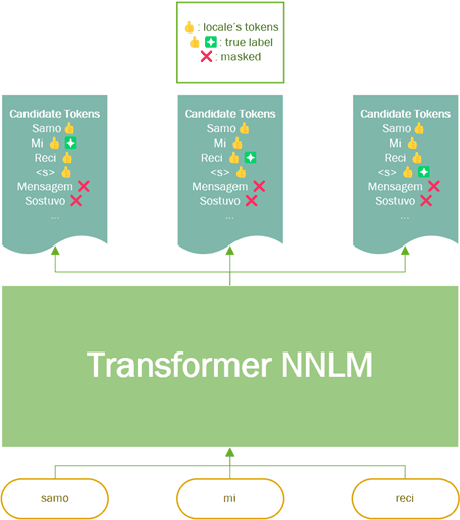
It is challenging to train and deploy Transformer LMs for hybrid speech recognition 2nd pass re-ranking in low-resource languages due to (1) data scarcity in low-resource languages, (2) expensive computing costs for training and refreshing 100+ monolingual models, and (3) hosting inefficiency considering sparse traffic. In this study, we present a new way to group multiple low-resource locales together and optimize the performance of Multilingual Transformer LMs in ASR. Our Locale-group Multilingual Transformer LMs outperform traditional multilingual LMs along with reducing maintenance costs and operating expenses. Further, for low-resource but high-traffic locales where deploying monolingual models is feasible, we show that fine-tuning our locale-group multilingual LMs produces better monolingual LM candidates than baseline monolingual LMs.
LSTM-LM with Long-Term History for First-Pass Decoding in Conversational Speech Recognition
Oct 21, 2020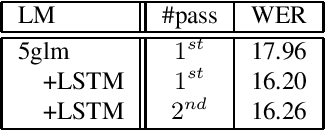
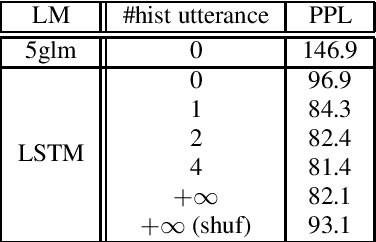
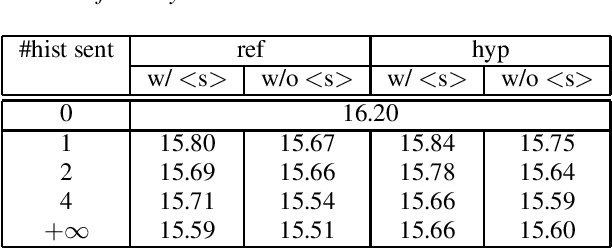

LSTM language models (LSTM-LMs) have been proven to be powerful and yielded significant performance improvements over count based n-gram LMs in modern speech recognition systems. Due to its infinite history states and computational load, most previous studies focus on applying LSTM-LMs in the second-pass for rescoring purpose. Recent work shows that it is feasible and computationally affordable to adopt the LSTM-LMs in the first-pass decoding within a dynamic (or tree based) decoder framework. In this work, the LSTM-LM is composed with a WFST decoder on-the-fly for the first-pass decoding. Furthermore, motivated by the long-term history nature of LSTM-LMs, the use of context beyond the current utterance is explored for the first-pass decoding in conversational speech recognition. The context information is captured by the hidden states of LSTM-LMs across utterance and can be used to guide the first-pass search effectively. The experimental results in our internal meeting transcription system show that significant performance improvements can be obtained by incorporating the contextual information with LSTM-LMs in the first-pass decoding, compared to applying the contextual information in the second-pass rescoring.
Long-span language modeling for speech recognition
Nov 11, 2019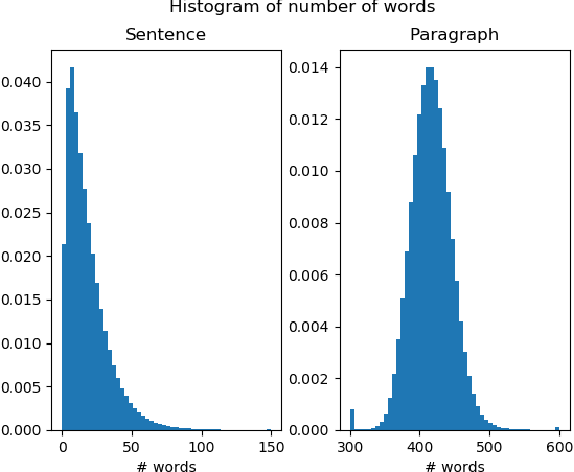
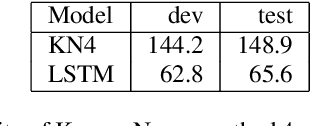
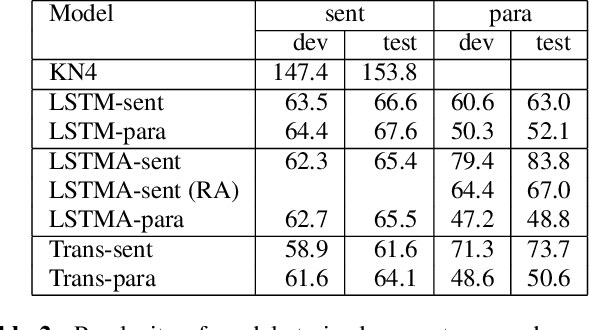
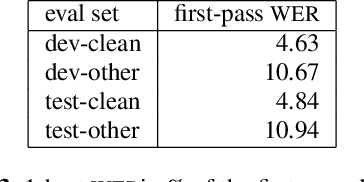
We explore neural language modeling for speech recognition where the context spans multiple sentences. Rather than encode history beyond the current sentence using a cache of words or document-level features, we focus our study on the ability of LSTM and Transformer language models to implicitly learn to carry over context across sentence boundaries. We introduce a new architecture that incorporates an attention mechanism into LSTM to combine the benefits of recurrent and attention architectures. We conduct language modeling and speech recognition experiments on the publicly available LibriSpeech corpus. We show that conventional training on a paragraph-level corpus results in significant reductions in perplexity compared to training on a sentence-level corpus. We also describe speech recognition experiments using long-span language models in second-pass re-ranking, and provide insights into the ability of such models to take advantage of context beyond the current sentence.