 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming, fast and accurate on-device Inverse Text Normalization for Automatic Speech Recognition
Nov 07, 2022
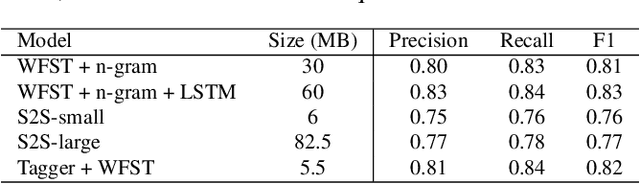
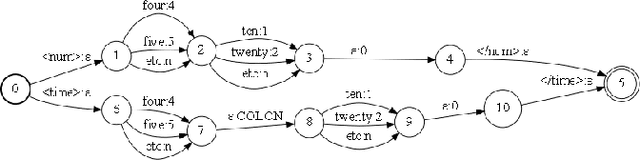
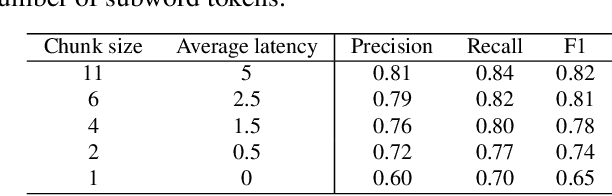
Automatic Speech Recognition (ASR) systems typically yield output in lexical form. However, humans prefer a written form output. To bridge this gap, ASR systems usually employ Inverse Text Normalization (ITN). In previous works, Weighted Finite State Transducers (WFST) have been employed to do ITN. WFSTs are nicely suited to this task but their size and run-time costs can make deployment on embedded applications challenging. In this paper, we describe the development of an on-device ITN system that is streaming, lightweight & accurate. At the core of our system is a streaming transformer tagger, that tags lexical tokens from ASR. The tag informs which ITN category might be applied, if at all. Following that, we apply an ITN-category-specific WFST, only on the tagged text, to reliably perform the ITN conversion. We show that the proposed ITN solution performs equivalent to strong baselines, while being significantly smaller in size and retaining customization capabilities.
Four-in-One: A Joint Approach to Inverse Text Normalization, Punctuation, Capitalization, and Disfluency for Automatic Speech Recognition
Oct 26, 2022



Features such as punctuation, capitalization, and formatting of entities are important for readability, understanding, and natural language processing tasks. However, Automatic Speech Recognition (ASR) systems produce spoken-form text devoid of formatting, and tagging approaches to formatting address just one or two features at a time. In this paper, we unify spoken-to-written text conversion via a two-stage process: First, we use a single transformer tagging model to jointly produce token-level tags for inverse text normalization (ITN), punctuation, capitalization, and disfluencies. Then, we apply the tags to generate written-form text and use weighted finite state transducer (WFST) grammars to format tagged ITN entity spans. Despite joining four models into one, our unified tagging approach matches or outperforms task-specific models across all four tasks on benchmark test sets across several domains.