 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Punctuation: A Novel Punctuation Technique Leveraging Bidirectional Context for Continuous Speech Recognition
Jan 10, 2023



While speech recognition Word Error Rate (WER) has reached human parity for English, continuous speech recognition scenarios such as voice typing and meeting transcriptions still suffer from segmentation and punctuation problems, resulting from irregular pausing patterns or slow speakers. Transformer sequence tagging models are effective at capturing long bi-directional context, which is crucial for automatic punctuation. Automatic Speech Recognition (ASR) production systems, however, are constrained by real-time requirements, making it hard to incorporate the right context when making punctuation decisions. Context within the segments produced by ASR decoders can be helpful but limiting in overall punctuation performance for a continuous speech session. In this paper, we propose a streaming approach for punctuation or re-punctuation of ASR output using dynamic decoding windows and measure its impact on punctuation and segmentation accuracy across scenarios. The new system tackles over-segmentation issues, improving segmentation F0.5-score by 13.9%. Streaming punctuation achieves an average BLEUscore improvement of 0.66 for the downstream task of Machine Translation (MT).
* arXiv admin note: substantial text overlap with arXiv:2210.05756
Smart Speech Segmentation using Acousto-Linguistic Features with look-ahead
Oct 27, 2022



Segmentation for continuous Automatic Speech Recognition (ASR) has traditionally used silence timeouts or voice activity detectors (VADs), which are both limited to acoustic features. This segmentation is often overly aggressive, given that people naturally pause to think as they speak. Consequently, segmentation happens mid-sentence, hindering both punctuation and downstream tasks like machine translation for which high-quality segmentation is critical. Model-based segmentation methods that leverage acoustic features are powerful, but without an understanding of the language itself, these approaches are limited. We present a hybrid approach that leverages both acoustic and language information to improve segmentation. Furthermore, we show that including one word as a look-ahead boosts segmentation quality. On average, our models improve segmentation-F0.5 score by 9.8% over baseline. We show that this approach works for multiple languages. For the downstream task of machine translation, it improves the translation BLEU score by an average of 1.05 points.
TRScore: A Novel GPT-based Readability Scorer for ASR Segmentation and Punctuation model evaluation and selection
Oct 27, 2022
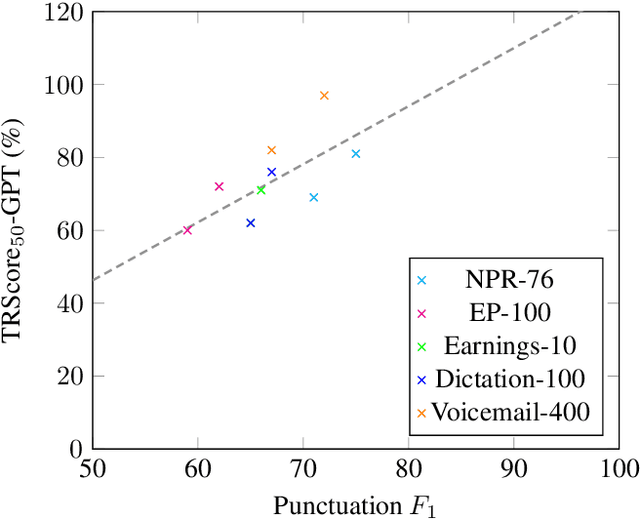
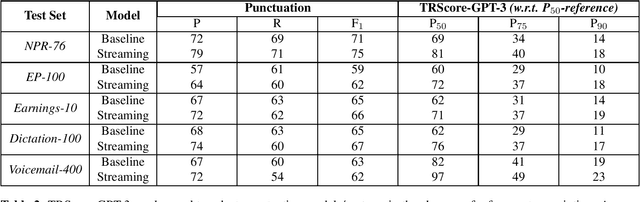
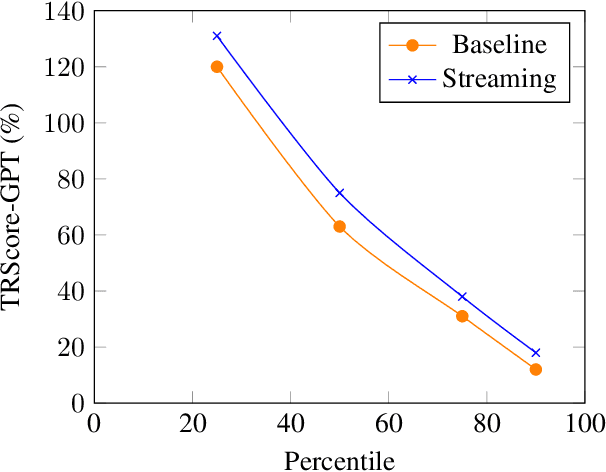
Punctuation and Segmentation are key to readability in Automatic Speech Recognition (ASR), often evaluated using F1 scores that require high-quality human transcripts and do not reflect readability well. Human evaluation is expensive, time-consuming, and suffers from large inter-observer variability, especially in conversational speech devoid of strict grammatical structures. Large pre-trained models capture a notion of grammatical structure. We present TRScore, a novel readability measure using the GPT model to evaluate different segmentation and punctuation systems. We validate our approach with human experts. Additionally, our approach enables quantitative assessment of text post-processing techniques such as capitalization, inverse text normalization (ITN), and disfluency on overall readability, which traditional word error rate (WER) and slot error rate (SER) metrics fail to capture. TRScore is strongly correlated to traditional F1 and human readability scores, with Pearson's correlation coefficients of 0.67 and 0.98, respectively. It also eliminates the need for human transcriptions for model selection.
Four-in-One: A Joint Approach to Inverse Text Normalization, Punctuation, Capitalization, and Disfluency for Automatic Speech Recognition
Oct 26, 2022



Features such as punctuation, capitalization, and formatting of entities are important for readability, understanding, and natural language processing tasks. However, Automatic Speech Recognition (ASR) systems produce spoken-form text devoid of formatting, and tagging approaches to formatting address just one or two features at a time. In this paper, we unify spoken-to-written text conversion via a two-stage process: First, we use a single transformer tagging model to jointly produce token-level tags for inverse text normalization (ITN), punctuation, capitalization, and disfluencies. Then, we apply the tags to generate written-form text and use weighted finite state transducer (WFST) grammars to format tagged ITN entity spans. Despite joining four models into one, our unified tagging approach matches or outperforms task-specific models across all four tasks on benchmark test sets across several domains.
Streaming Punctuation for Long-form Dictation with Transformers
Oct 11, 2022



While speech recognition Word Error Rate (WER) has reached human parity for English, long-form dictation scenarios still suffer from segmentation and punctuation problems resulting from irregular pausing patterns or slow speakers. Transformer sequence tagging models are effective at capturing long bi-directional context, which is crucial for automatic punctuation. A typical Automatic Speech Recognition (ASR) production system, however, is constrained by real-time requirements, making it hard to incorporate the right context when making punctuation decisions. In this paper, we propose a streaming approach for punctuation or re-punctuation of ASR output using dynamic decoding windows and measure its impact on punctuation and segmentation accuracy in a variety of scenarios. The new system tackles over-segmentation issues, improving segmentation F0.5-score by 13.9%. Streaming punctuation achieves an average BLEU-score gain of 0.66 for the downstream task of Machine Translation (MT).