 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Speech Segmentation using Acousto-Linguistic Features with look-ahead
Oct 27, 2022



Segmentation for continuous Automatic Speech Recognition (ASR) has traditionally used silence timeouts or voice activity detectors (VADs), which are both limited to acoustic features. This segmentation is often overly aggressive, given that people naturally pause to think as they speak. Consequently, segmentation happens mid-sentence, hindering both punctuation and downstream tasks like machine translation for which high-quality segmentation is critical. Model-based segmentation methods that leverage acoustic features are powerful, but without an understanding of the language itself, these approaches are limited. We present a hybrid approach that leverages both acoustic and language information to improve segmentation. Furthermore, we show that including one word as a look-ahead boosts segmentation quality. On average, our models improve segmentation-F0.5 score by 9.8% over baseline. We show that this approach works for multiple languages. For the downstream task of machine translation, it improves the translation BLEU score by an average of 1.05 points.
Towards Contextual Spelling Correction for Customization of End-to-end Speech Recognition Systems
Mar 02, 2022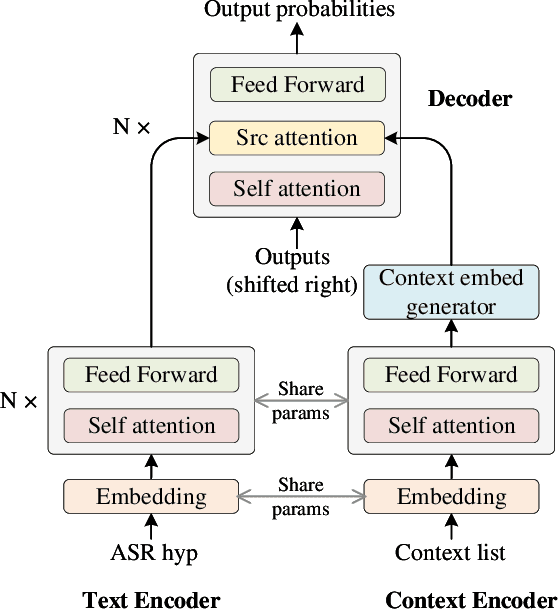
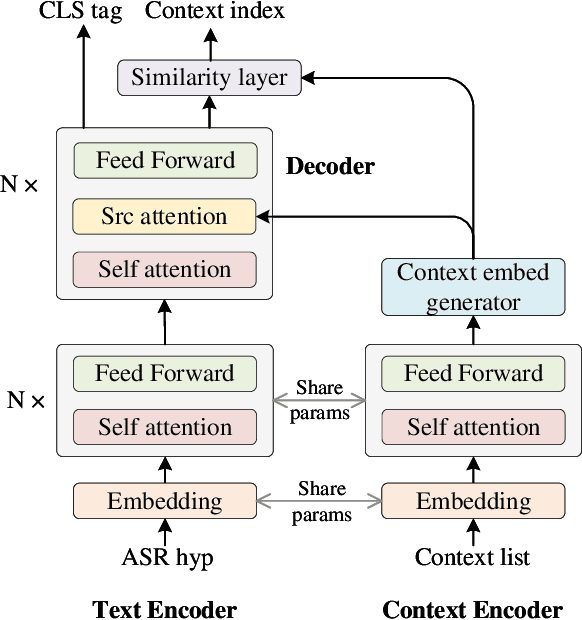
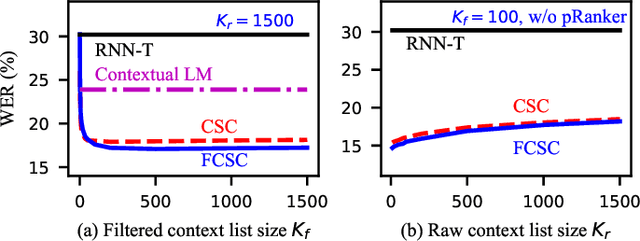
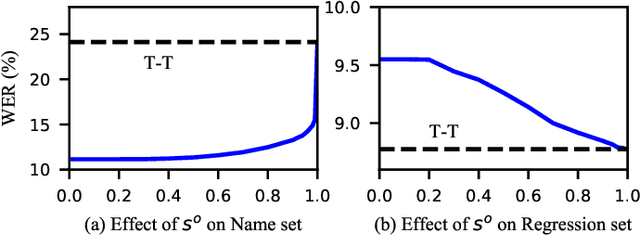
Contextual biasing is an important and challenging task for end-to-end automatic speech recognition (ASR) systems, which aims to achieve better recognition performance by biasing the ASR system to particular context phrases such as person names, music list, proper nouns, etc. Existing methods mainly include contextual LM biasing and adding bias encoder into end-to-end ASR models. In this work, we introduce a novel approach to do contextual biasing by adding a contextual spelling correction model on top of the end-to-end ASR system. We incorporate contextual information into a sequence-to-sequence spelling correction model with a shared context encoder. Our proposed model includes two different mechanisms: autoregressive (AR) and non-autoregressive (NAR). We propose filtering algorithms to handle large-size context lists, and performance balancing mechanisms to control the biasing degree of the model. We demonstrate the proposed model is a general biasing solution which is domain-insensitive and can be adopted in different scenarios. Experiments show that the proposed method achieves as much as 51% relative word error rate (WER) reduction over ASR system and outperforms traditional biasing methods. Compared to the AR solution, the proposed NAR model reduces model size by 43.2% and speeds up inference by 2.1 times.