 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Speech Segmentation using Acousto-Linguistic Features with look-ahead
Oct 27, 2022



Segmentation for continuous Automatic Speech Recognition (ASR) has traditionally used silence timeouts or voice activity detectors (VADs), which are both limited to acoustic features. This segmentation is often overly aggressive, given that people naturally pause to think as they speak. Consequently, segmentation happens mid-sentence, hindering both punctuation and downstream tasks like machine translation for which high-quality segmentation is critical. Model-based segmentation methods that leverage acoustic features are powerful, but without an understanding of the language itself, these approaches are limited. We present a hybrid approach that leverages both acoustic and language information to improve segmentation. Furthermore, we show that including one word as a look-ahead boosts segmentation quality. On average, our models improve segmentation-F0.5 score by 9.8% over baseline. We show that this approach works for multiple languages. For the downstream task of machine translation, it improves the translation BLEU score by an average of 1.05 points.
In Plain Sight: Media Bias Through the Lens of Factual Reporting
Sep 05, 2019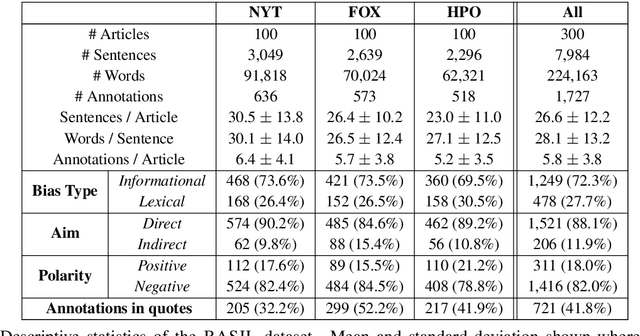
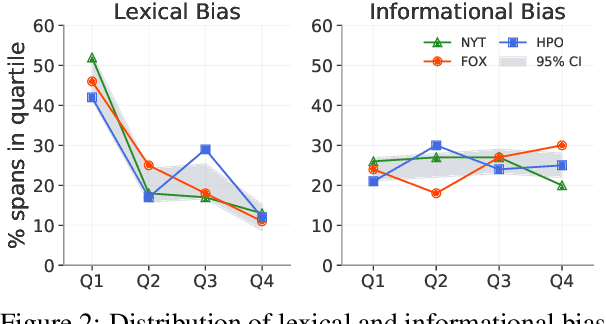
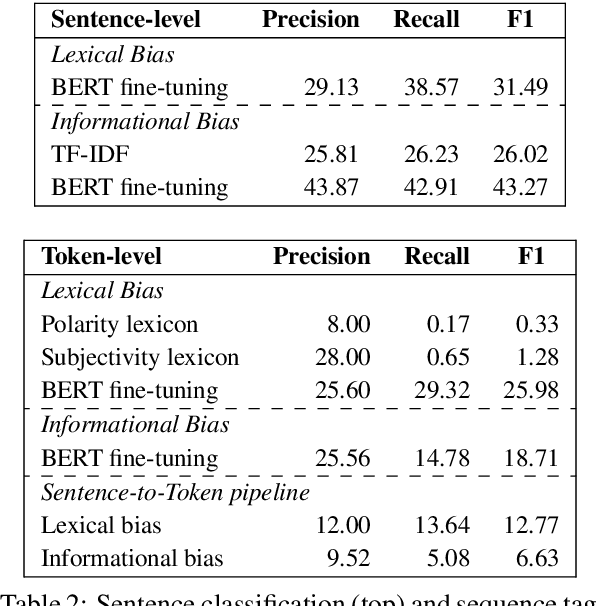
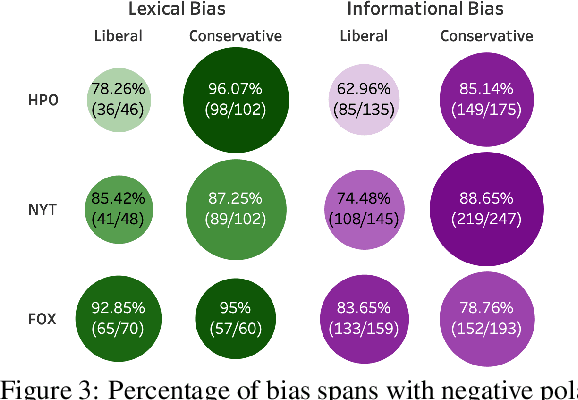
The increasing prevalence of political bias in news media calls for greater public awareness of it, as well as robust methods for its detection. While prior work in NLP has primarily focused on the lexical bias captured by linguistic attributes such as word choice and syntax, other types of bias stem from the actual content selected for inclusion in the text. In this work, we investigate the effects of informational bias: factual content that can nevertheless be deployed to sway reader opinion. We first produce a new dataset, BASIL, of 300 news articles annotated with 1,727 bias spans and find evidence that informational bias appears in news articles more frequently than lexical bias. We further study our annotations to observe how informational bias surfaces in news articles by different media outlets. Lastly, a baseline model for informational bias prediction is presented by fine-tuning BERT on our labeled data, indicating the challenges of the task and future directions.
An Entity-Driven Framework for Abstractive Summarization
Sep 04, 2019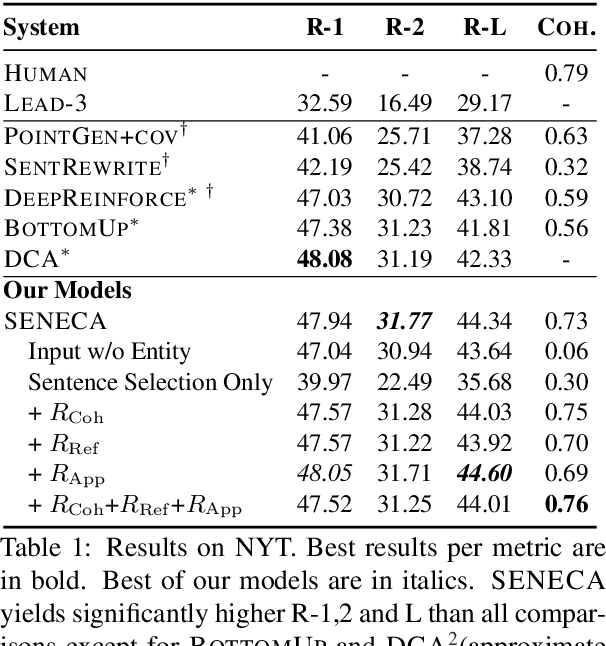
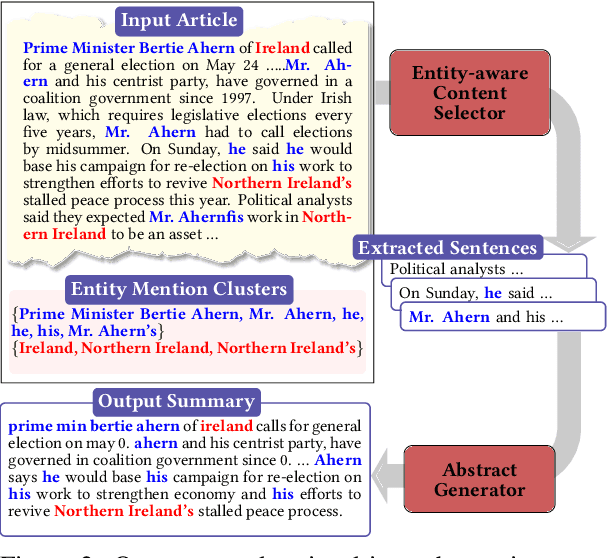
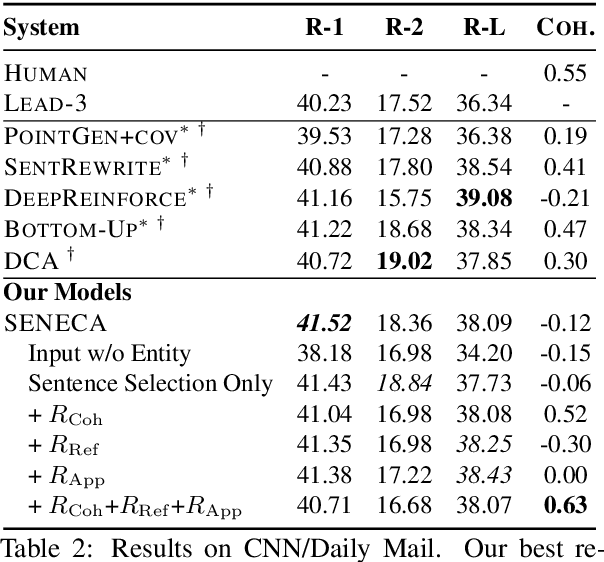

Abstractive summarization systems aim to produce more coherent and concise summaries than their extractive counterparts. Popular neural models have achieved impressive results for single-document summarization, yet their outputs are often incoherent and unfaithful to the input. In this paper, we introduce SENECA, a novel System for ENtity-drivEn Coherent Abstractive summarization framework that leverages entity information to generate informative and coherent abstracts. Our framework takes a two-step approach: (1) an entity-aware content selection module first identifies salient sentences from the input, then (2) an abstract generation module conducts cross-sentence information compression and abstraction to generate the final summary, which is trained with rewards to promote coherence, conciseness, and clarity. The two components are further connected using reinforcement learning. Automatic evaluation shows that our model significantly outperforms previous state-of-the-art on ROUGE and our proposed coherence measures on New York Times and CNN/Daily Mail datasets. Human judges further rate our system summaries as more informative and coherent than those by popular summarization models.
BIGPATENT: A Large-Scale Dataset for Abstractive and Coherent Summarization
Jun 10, 2019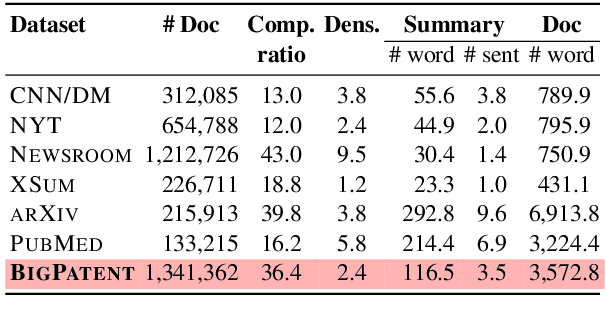

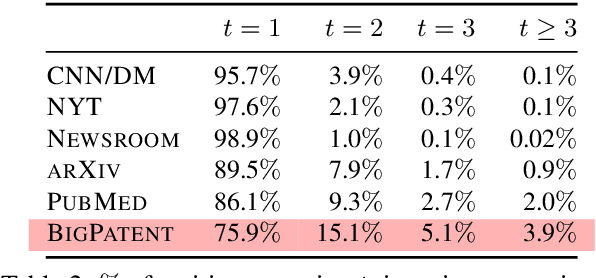
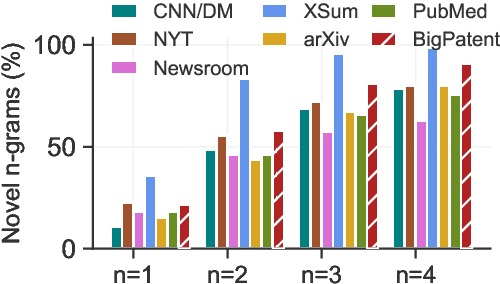
Most existing text summarization datasets are compiled from the news domain, where summaries have a flattened discourse structure. In such datasets, summary-worthy content often appears in the beginning of input articles. Moreover, large segments from input articles are present verbatim in their respective summaries. These issues impede the learning and evaluation of systems that can understand an article's global content structure as well as produce abstractive summaries with high compression ratio. In this work, we present a novel dataset, BIGPATENT, consisting of 1.3 million records of U.S. patent documents along with human written abstractive summaries. Compared to existing summarization datasets, BIGPATENT has the following properties: i) summaries contain a richer discourse structure with more recurring entities, ii) salient content is evenly distributed in the input, and iii) lesser and shorter extractive fragments are present in the summaries. Finally, we train and evaluate baselines and popular learning models on BIGPATENT to shed light on new challenges and motivate future directions for summarization research.