 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Uncertainty Quantification
Jan 22, 2026Although AI agents have demonstrated impressive capabilities in long-horizon reasoning, their reliability is severely hampered by the ``Spiral of Hallucination,'' where early epistemic errors propagate irreversibly. Existing methods face a dilemma: uncertainty quantification (UQ) methods typically act as passive sensors, only diagnosing risks without addressing them, while self-reflection mechanisms suffer from continuous or aimless corrections. To bridge this gap, we propose a unified Dual-Process Agentic UQ (AUQ) framework that transforms verbalized uncertainty into active, bi-directional control signals. Our architecture comprises two complementary mechanisms: System 1 (Uncertainty-Aware Memory, UAM), which implicitly propagates verbalized confidence and semantic explanations to prevent blind decision-making; and System 2 (Uncertainty-Aware Reflection, UAR), which utilizes these explanations as rational cues to trigger targeted inference-time resolution only when necessary. This enables the agent to balance efficient execution and deep deliberation dynamically. Extensive experiments on closed-loop benchmarks and open-ended deep research tasks demonstrate that our training-free approach achieves superior performance and trajectory-level calibration. We believe this principled framework AUQ represents a significant step towards reliable agents.
CRMArena-Pro: Holistic Assessment of LLM Agents Across Diverse Business Scenarios and Interactions
May 24, 2025While AI agents hold transformative potential in business, effective performance benchmarking is hindered by the scarcity of public, realistic business data on widely used platforms. Existing benchmarks often lack fidelity in their environments, data, and agent-user interactions, with limited coverage of diverse business scenarios and industries. To address these gaps, we introduce CRMArena-Pro, a novel benchmark for holistic, realistic assessment of LLM agents in diverse professional settings. CRMArena-Pro expands on CRMArena with nineteen expert-validated tasks across sales, service, and 'configure, price, and quote' processes, for both Business-to-Business and Business-to-Customer scenarios. It distinctively incorporates multi-turn interactions guided by diverse personas and robust confidentiality awareness assessments. Experiments reveal leading LLM agents achieve only around 58% single-turn success on CRMArena-Pro, with performance dropping significantly to approximately 35% in multi-turn settings. While Workflow Execution proves more tractable for top agents (over 83% single-turn success), other evaluated business skills present greater challenges. Furthermore, agents exhibit near-zero inherent confidentiality awareness; though targeted prompting can improve this, it often compromises task performance. These findings highlight a substantial gap between current LLM capabilities and enterprise demands, underscoring the need for advancements in multi-turn reasoning, confidentiality adherence, and versatile skill acquisition.
Turning Conversations into Workflows: A Framework to Extract and Evaluate Dialog Workflows for Service AI Agents
Feb 24, 2025Automated service agents require well-structured workflows to provide consistent and accurate responses to customer queries. However, these workflows are often undocumented, and their automatic extraction from conversations remains unexplored. In this work, we present a novel framework for extracting and evaluating dialog workflows from historical interactions. Our extraction process consists of two key stages: (1) a retrieval step to select relevant conversations based on key procedural elements, and (2) a structured workflow generation process using a question-answer-based chain-of-thought (QA-CoT) prompting. To comprehensively assess the quality of extracted workflows, we introduce an automated agent and customer bots simulation framework that measures their effectiveness in resolving customer issues. Extensive experiments on the ABCD and SynthABCD datasets demonstrate that our QA-CoT technique improves workflow extraction by 12.16\% in average macro accuracy over the baseline. Moreover, our evaluation method closely aligns with human assessments, providing a reliable and scalable framework for future research.
Unanswerability Evaluation for Retreival Augmented Generation
Dec 16, 2024Existing evaluation frameworks for retrieval-augmented generation (RAG) systems focus on answerable queries, but they overlook the importance of appropriately rejecting unanswerable requests. In this paper, we introduce UAEval4RAG, a framework designed to evaluate whether RAG systems can handle unanswerable queries effectively. We define a taxonomy with six unanswerable categories, and UAEval4RAG automatically synthesizes diverse and challenging queries for any given knowledge base with unanswered ratio and acceptable ratio metrics. We conduct experiments with various RAG components, including retrieval models, rewriting methods, rerankers, language models, and prompting strategies, and reveal hidden trade-offs in performance of RAG systems. Our findings highlight the critical role of component selection and prompt design in optimizing RAG systems to balance the accuracy of answerable queries with high rejection rates of unanswerable ones. UAEval4RAG provides valuable insights and tools for developing more robust and reliable RAG systems.
SiReRAG: Indexing Similar and Related Information for Multihop Reasoning
Dec 09, 2024



Indexing is an important step towards strong performance in retrieval-augmented generation (RAG) systems. However, existing methods organize data based on either semantic similarity (similarity) or related information (relatedness), but do not cover both perspectives comprehensively. Our analysis reveals that modeling only one perspective results in insufficient knowledge synthesis, leading to suboptimal performance on complex tasks requiring multihop reasoning. In this paper, we propose SiReRAG, a novel RAG indexing approach that explicitly considers both similar and related information. On the similarity side, we follow existing work and explore some variances to construct a similarity tree based on recursive summarization. On the relatedness side, SiReRAG extracts propositions and entities from texts, groups propositions via shared entities, and generates recursive summaries to construct a relatedness tree. We index and flatten both similarity and relatedness trees into a unified retrieval pool. Our experiments demonstrate that SiReRAG consistently outperforms state-of-the-art indexing methods on three multihop datasets (MuSiQue, 2WikiMultiHopQA, and HotpotQA), with an average 1.9% improvement in F1 scores. As a reasonably efficient solution, SiReRAG enhances existing reranking methods significantly, with up to 7.8% improvement in average F1 scores.
Distill-SynthKG: Distilling Knowledge Graph Synthesis Workflow for Improved Coverage and Efficiency
Oct 22, 2024



Knowledge graphs (KGs) generated by large language models (LLMs) are becoming increasingly valuable for Retrieval-Augmented Generation (RAG) applications that require knowledge-intensive reasoning. However, existing KG extraction methods predominantly rely on prompt-based approaches, which are inefficient for processing large-scale corpora. These approaches often suffer from information loss, particularly with long documents, due to the lack of specialized design for KG construction. Additionally, there is a gap in evaluation datasets and methodologies for ontology-free KG construction. To overcome these limitations, we propose SynthKG, a multi-step, document-level ontology-free KG synthesis workflow based on LLMs. By fine-tuning a smaller LLM on the synthesized document-KG pairs, we streamline the multi-step process into a single-step KG generation approach called Distill-SynthKG, substantially reducing the number of LLM inference calls. Furthermore, we re-purpose existing question-answering datasets to establish KG evaluation datasets and introduce new evaluation metrics. Using KGs produced by Distill-SynthKG, we also design a novel graph-based retrieval framework for RAG. Experimental results demonstrate that Distill-SynthKG not only surpasses all baseline models in KG quality -- including models up to eight times larger -- but also consistently excels in retrieval and question-answering tasks. Our proposed graph retrieval framework also outperforms all KG-retrieval methods across multiple benchmark datasets. We release the SynthKG dataset and Distill-SynthKG model publicly to support further research and development.
Do RAG Systems Cover What Matters? Evaluating and Optimizing Responses with Sub-Question Coverage
Oct 20, 2024



Evaluating retrieval-augmented generation (RAG) systems remains challenging, particularly for open-ended questions that lack definitive answers and require coverage of multiple sub-topics. In this paper, we introduce a novel evaluation framework based on sub-question coverage, which measures how well a RAG system addresses different facets of a question. We propose decomposing questions into sub-questions and classifying them into three types -- core, background, and follow-up -- to reflect their roles and importance. Using this categorization, we introduce a fine-grained evaluation protocol that provides insights into the retrieval and generation characteristics of RAG systems, including three commercial generative answer engines: You.com, Perplexity AI, and Bing Chat. Interestingly, we find that while all answer engines cover core sub-questions more often than background or follow-up ones, they still miss around 50% of core sub-questions, revealing clear opportunities for improvement. Further, sub-question coverage metrics prove effective for ranking responses, achieving 82% accuracy compared to human preference annotations. Lastly, we also demonstrate that leveraging core sub-questions enhances both retrieval and answer generation in a RAG system, resulting in a 74% win rate over the baseline that lacks sub-questions.
Lexical Repetitions Lead to Rote Learning: Unveiling the Impact of Lexical Overlap in Train and Test Reference Summaries
Nov 15, 2023
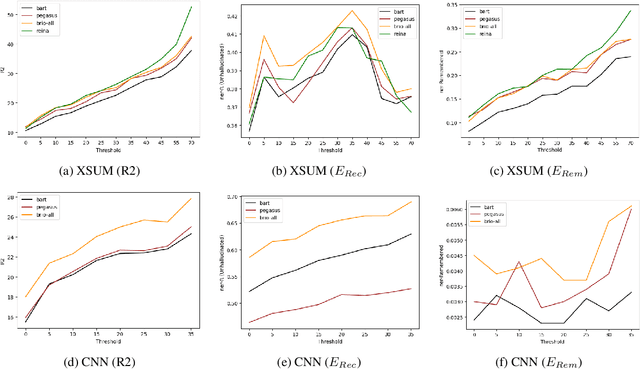
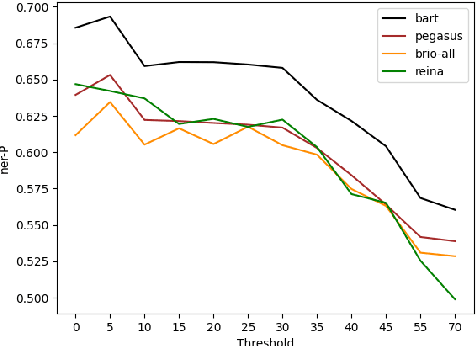
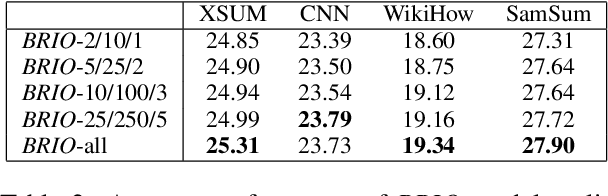
Ideal summarization models should generalize to novel summary-worthy content without remembering reference training summaries by rote. However, a single average performance score on the entire test set is inadequate in determining such model competencies. We propose a fine-grained evaluation protocol by partitioning a test set based on the lexical similarity of reference test summaries with training summaries. We observe up to a 5x (1.2x) difference in ROUGE-2 (entity recall) scores between the subsets with the lowest and highest similarity. Next, we show that such training repetitions also make a model vulnerable to rote learning, reproducing data artifacts such as factual errors, especially when reference test summaries are lexically close to training summaries. Consequently, we propose to limit lexical repetitions in training summaries during both supervised fine-tuning and likelihood calibration stages to improve the performance on novel test cases while retaining average performance. Our automatic and human evaluations on novel test subsets and recent news articles show that limiting lexical repetitions in training summaries can prevent rote learning and improve generalization.
Embrace Divergence for Richer Insights: A Multi-document Summarization Benchmark and a Case Study on Summarizing Diverse Information from News Articles
Sep 17, 2023Previous research in multi-document news summarization has typically concentrated on collating information that all sources agree upon. However, to our knowledge, the summarization of diverse information dispersed across multiple articles about an event has not been previously investigated. The latter imposes a different set of challenges for a summarization model. In this paper, we propose a new task of summarizing diverse information encountered in multiple news articles encompassing the same event. To facilitate this task, we outlined a data collection schema for identifying diverse information and curated a dataset named DiverseSumm. The dataset includes 245 news stories, with each story comprising 10 news articles and paired with a human-validated reference. Moreover, we conducted a comprehensive analysis to pinpoint the position and verbosity biases when utilizing Large Language Model (LLM)-based metrics for evaluating the coverage and faithfulness of the summaries, as well as their correlation with human assessments. We applied our findings to study how LLMs summarize multiple news articles by analyzing which type of diverse information LLMs are capable of identifying. Our analyses suggest that despite the extraordinary capabilities of LLMs in single-document summarization, the proposed task remains a complex challenge for them mainly due to their limited coverage, with GPT-4 only able to cover less than 40% of the diverse information on average.
XGen-7B Technical Report
Sep 07, 2023Large Language Models (LLMs) have become ubiquitous across various domains, transforming the way we interact with information and conduct research. However, most high-performing LLMs remain confined behind proprietary walls, hindering scientific progress. Most open-source LLMs, on the other hand, are limited in their ability to support longer sequence lengths, which is a key requirement for many tasks that require inference over an input context. To address this, we have trained XGen, a series of 7B parameter models on up to 8K sequence length for up to 1.5T tokens. We have also finetuned the XGen models on public-domain instructional data, creating their instruction-tuned counterparts (XGen-Inst). We open-source our models for both research advancements and commercial applications. Our evaluation on standard benchmarks shows that XGen models achieve comparable or better results when compared with state-of-the-art open-source LLMs. Our targeted evaluation on long sequence modeling tasks shows the benefits of our 8K-sequence models over 2K-sequence open-source LLMs.