 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbrace Divergence for Richer Insights: A Multi-document Summarization Benchmark and a Case Study on Summarizing Diverse Information from News Articles
Paper and Code
Sep 17, 2023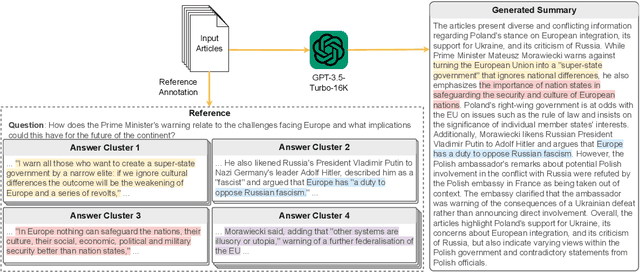



Previous research in multi-document news summarization has typically concentrated on collating information that all sources agree upon. However, to our knowledge, the summarization of diverse information dispersed across multiple articles about an event has not been previously investigated. The latter imposes a different set of challenges for a summarization model. In this paper, we propose a new task of summarizing diverse information encountered in multiple news articles encompassing the same event. To facilitate this task, we outlined a data collection schema for identifying diverse information and curated a dataset named DiverseSumm. The dataset includes 245 news stories, with each story comprising 10 news articles and paired with a human-validated reference. Moreover, we conducted a comprehensive analysis to pinpoint the position and verbosity biases when utilizing Large Language Model (LLM)-based metrics for evaluating the coverage and faithfulness of the summaries, as well as their correlation with human assessments. We applied our findings to study how LLMs summarize multiple news articles by analyzing which type of diverse information LLMs are capable of identifying. Our analyses suggest that despite the extraordinary capabilities of LLMs in single-document summarization, the proposed task remains a complex challenge for them mainly due to their limited coverage, with GPT-4 only able to cover less than 40% of the diverse information on average.