 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiVL: A Framework for Improved Vision-Language Alignment
Dec 19, 2024



Large Vision Language Models (LVLMs) have achieved significant progress in integrating visual and textual inputs for multimodal reasoning. However, a recurring challenge is ensuring these models utilize visual information as effectively as linguistic content when both modalities are necessary to formulate an accurate answer. We hypothesize that hallucinations arise due to the lack of effective visual grounding in current LVLMs. This issue extends to vision-language benchmarks, where it is difficult to make the image indispensable for accurate answer generation, particularly in vision question-answering tasks. In this work, we introduce FiVL, a novel method for constructing datasets designed to train LVLMs for enhanced visual grounding and to evaluate their effectiveness in achieving it. These datasets can be utilized for both training and assessing an LVLM's ability to use image content as substantive evidence rather than relying solely on linguistic priors, providing insights into the model's reliance on visual information. To demonstrate the utility of our dataset, we introduce an innovative training task that outperforms baselines alongside a validation method and application for explainability. The code is available at https://github.com/IntelLabs/fivl.
FastRM: An efficient and automatic explainability framework for multimodal generative models
Dec 02, 2024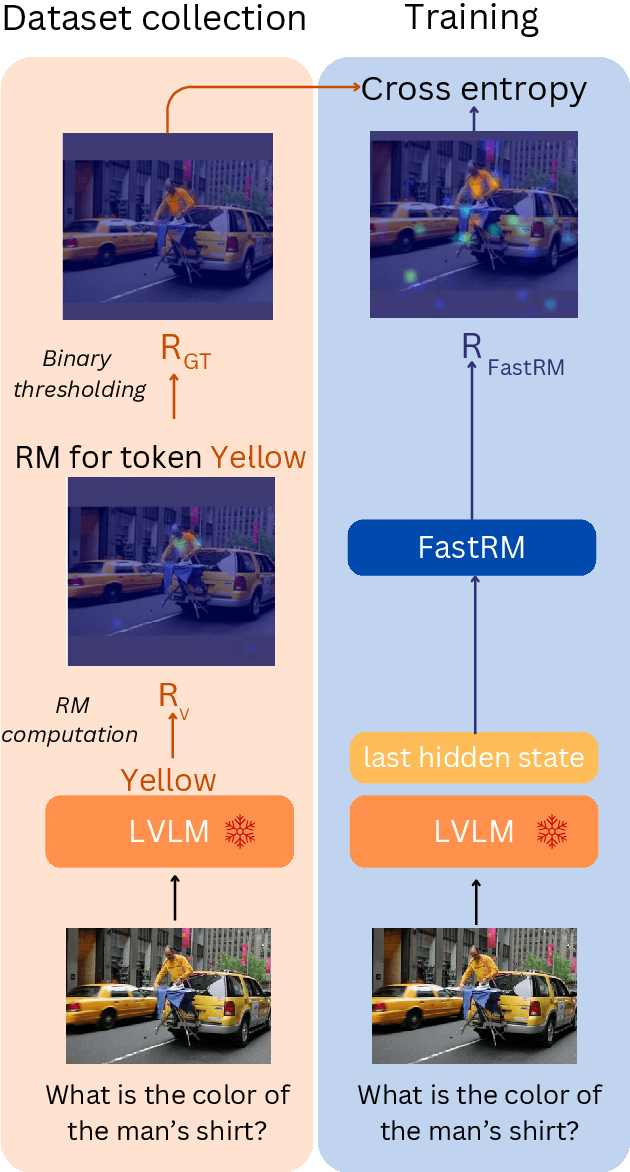
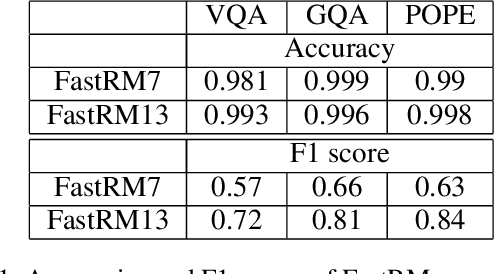
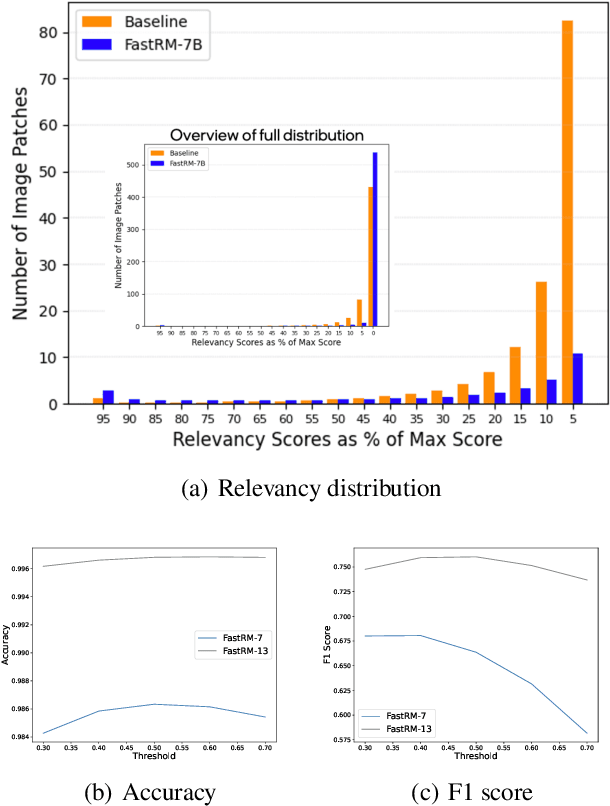
While Large Vision Language Models (LVLMs) have become masterly capable in reasoning over human prompts and visual inputs, they are still prone to producing responses that contain misinformation. Identifying incorrect responses that are not grounded in evidence has become a crucial task in building trustworthy AI. Explainability methods such as gradient-based relevancy maps on LVLM outputs can provide an insight on the decision process of models, however these methods are often computationally expensive and not suited for on-the-fly validation of outputs. In this work, we propose FastRM, an effective way for predicting the explainable Relevancy Maps of LVLM models. Experimental results show that employing FastRM leads to a 99.8% reduction in compute time for relevancy map generation and an 44.4% reduction in memory footprint for the evaluated LVLM, making explainable AI more efficient and practical, thereby facilitating its deployment in real-world applications.
Distill-SynthKG: Distilling Knowledge Graph Synthesis Workflow for Improved Coverage and Efficiency
Oct 22, 2024



Knowledge graphs (KGs) generated by large language models (LLMs) are becoming increasingly valuable for Retrieval-Augmented Generation (RAG) applications that require knowledge-intensive reasoning. However, existing KG extraction methods predominantly rely on prompt-based approaches, which are inefficient for processing large-scale corpora. These approaches often suffer from information loss, particularly with long documents, due to the lack of specialized design for KG construction. Additionally, there is a gap in evaluation datasets and methodologies for ontology-free KG construction. To overcome these limitations, we propose SynthKG, a multi-step, document-level ontology-free KG synthesis workflow based on LLMs. By fine-tuning a smaller LLM on the synthesized document-KG pairs, we streamline the multi-step process into a single-step KG generation approach called Distill-SynthKG, substantially reducing the number of LLM inference calls. Furthermore, we re-purpose existing question-answering datasets to establish KG evaluation datasets and introduce new evaluation metrics. Using KGs produced by Distill-SynthKG, we also design a novel graph-based retrieval framework for RAG. Experimental results demonstrate that Distill-SynthKG not only surpasses all baseline models in KG quality -- including models up to eight times larger -- but also consistently excels in retrieval and question-answering tasks. Our proposed graph retrieval framework also outperforms all KG-retrieval methods across multiple benchmark datasets. We release the SynthKG dataset and Distill-SynthKG model publicly to support further research and development.
NeuroPrompts: An Adaptive Framework to Optimize Prompts for Text-to-Image Generation
Nov 20, 2023Despite impressive recent advances in text-to-image diffusion models, obtaining high-quality images often requires prompt engineering by humans who have developed expertise in using them. In this work, we present NeuroPrompts, an adaptive framework that automatically enhances a user's prompt to improve the quality of generations produced by text-to-image models. Our framework utilizes constrained text decoding with a pre-trained language model that has been adapted to generate prompts similar to those produced by human prompt engineers. This approach enables higher-quality text-to-image generations and provides user control over stylistic features via constraint set specification. We demonstrate the utility of our framework by creating an interactive application for prompt enhancement and image generation using Stable Diffusion. Additionally, we conduct experiments utilizing a large dataset of human-engineered prompts for text-to-image generation and show that our approach automatically produces enhanced prompts that result in superior image quality. We make our code, a screencast video demo and a live demo instance of NeuroPrompts publicly available.
ManagerTower: Aggregating the Insights of Uni-Modal Experts for Vision-Language Representation Learning
May 31, 2023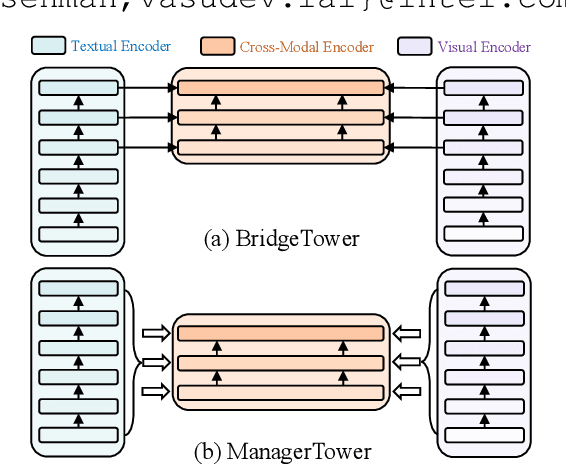
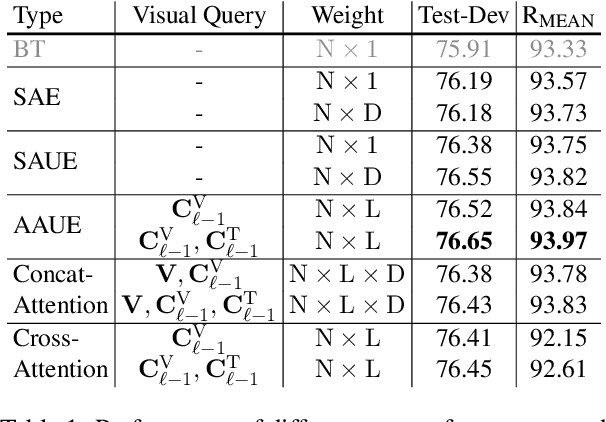
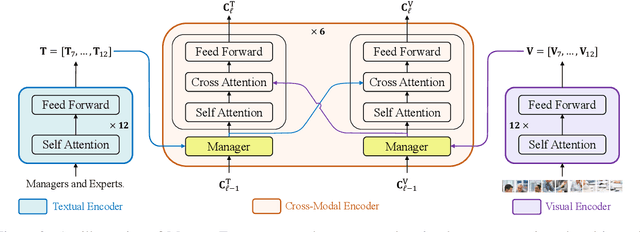
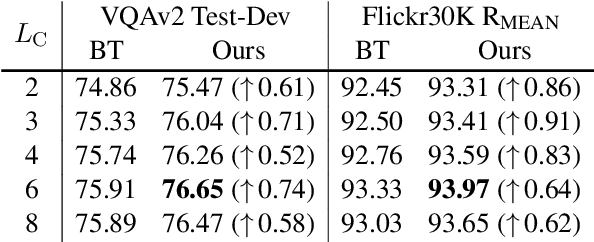
Two-Tower Vision-Language (VL) models have shown promising improvements on various downstream VL tasks. Although the most advanced work improves performance by building bridges between encoders, it suffers from ineffective layer-by-layer utilization of uni-modal representations and cannot flexibly exploit different levels of uni-modal semantic knowledge. In this work, we propose ManagerTower, a novel VL model architecture that gathers and combines the insights of pre-trained uni-modal experts at different levels. The managers introduced in each cross-modal layer can adaptively aggregate uni-modal semantic knowledge to facilitate more comprehensive cross-modal alignment and fusion. ManagerTower outperforms previous strong baselines both with and without Vision-Language Pre-training (VLP). With only 4M VLP data, ManagerTower achieves superior performances on various downstream VL tasks, especially 79.15% accuracy on VQAv2 Test-Std, 86.56% IR@1 and 95.64% TR@1 on Flickr30K. Code and checkpoints are available at https://github.com/LooperXX/ManagerTower.
Bridge-Tower: Building Bridges Between Encoders in Vision-Language Representation Learning
Jun 17, 2022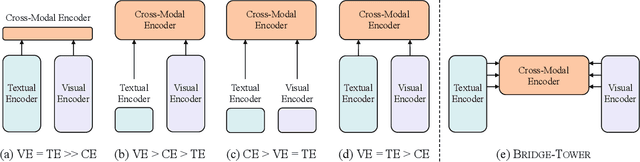


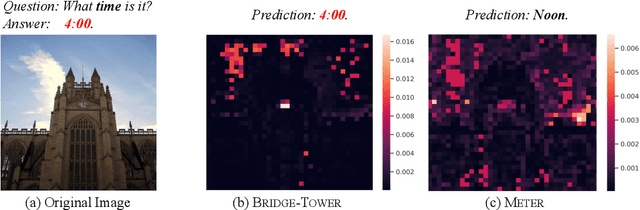
Vision-Language (VL) models with the Two-Tower architecture have dominated visual-language representation learning in recent years. Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a cross-modal encoder, or feed the last-layer uni-modal features directly into the top cross-modal encoder, ignoring the semantic information at the different levels in the deep uni-modal encoders. Both approaches possibly restrict vision-language representation learning and limit model performance. In this paper, we introduce multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the cross-modal encoder. This enables comprehensive bottom-up interactions between visual and textual representations at different semantic levels, resulting in more effective cross-modal alignment and fusion. Our proposed Bridge-Tower, pre-trained with only $4$M images, achieves state-of-the-art performance on various downstream vision-language tasks. On the VQAv2 test-std set, Bridge-Tower achieves an accuracy of $78.73\%$, outperforming the previous state-of-the-art METER model by $1.09\%$ with the same pre-training data and almost no additional parameters and computational cost. Notably, when further scaling the model, Bridge-Tower achieves an accuracy of $81.15\%$, surpassing models that are pre-trained on orders-of-magnitude larger datasets. Code is available at https://github.com/microsoft/BridgeTower.
Relation Extraction as Two-way Span-Prediction
Oct 09, 2020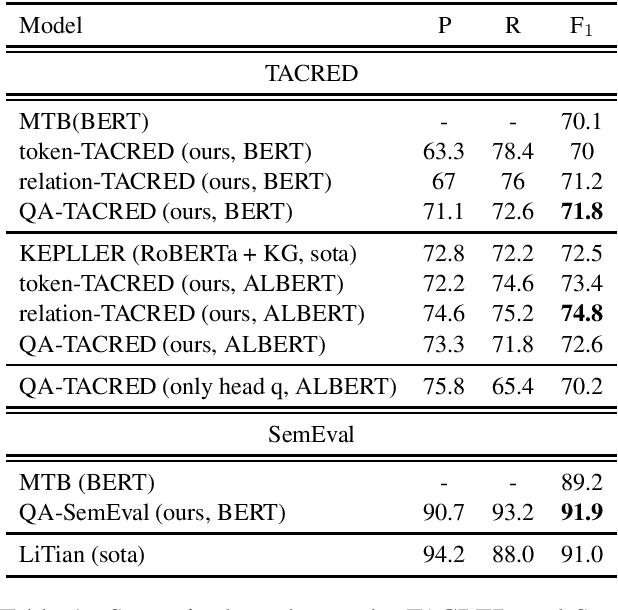
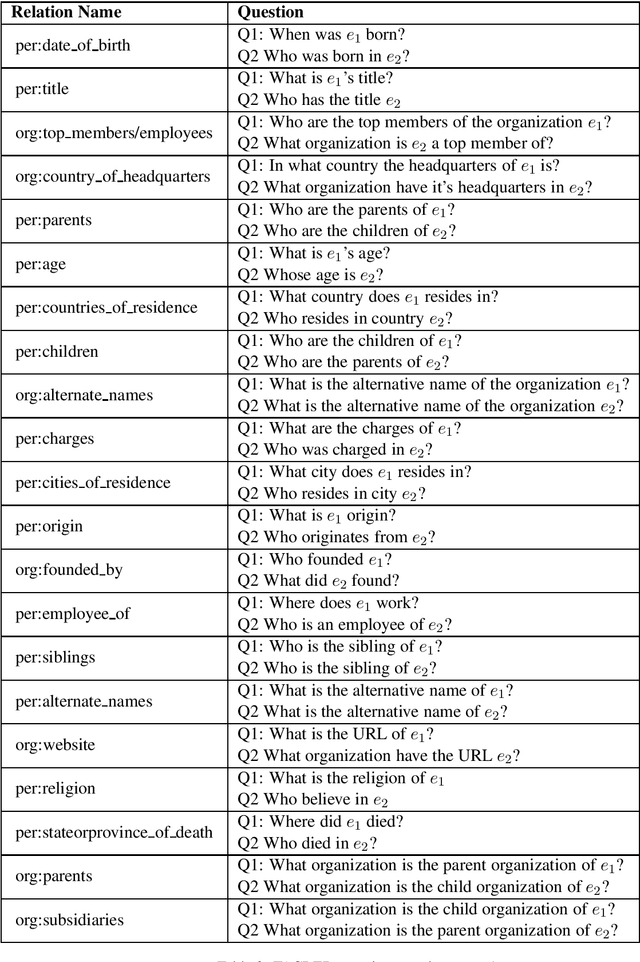

The current supervised relation classification (RC) task uses a single embedding to represent the relation between a pair of entities. We argue that a better approach is to treat the RC task as a Question answering (QA) like span prediction problem. We present a span-prediction based system for RC and evaluate its performance compared to the embedding based system. We achieve state-of-the-art results on the TACRED and SemEval task 8 datasets.
Exposing Shallow Heuristics of Relation Extraction Models with Challenge Data
Oct 07, 2020
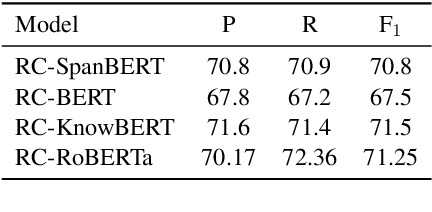

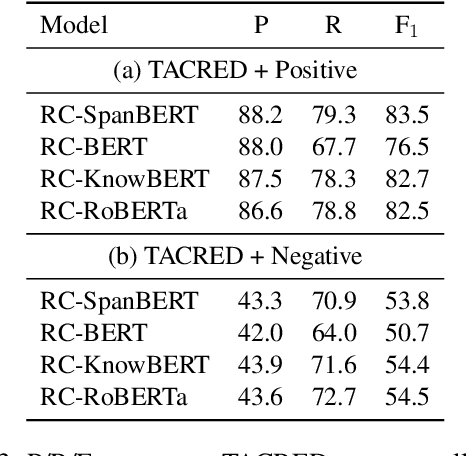
The process of collecting and annotating training data may introduce distribution artifacts which may limit the ability of models to learn correct generalization behavior. We identify failure modes of SOTA relation extraction (RE) models trained on TACRED, which we attribute to limitations in the data annotation process. We collect and annotate a challenge-set we call Challenging RE (CRE), based on naturally occurring corpus examples, to benchmark this behavior. Our experiments with four state-of-the-art RE models show that they have indeed adopted shallow heuristics that do not generalize to the challenge-set data. Further, we find that alternative question answering modeling performs significantly better than the SOTA models on the challenge-set, despite worse overall TACRED performance. By adding some of the challenge data as training examples, the performance of the model improves. Finally, we provide concrete suggestion on how to improve RE data collection to alleviate this behavior.