 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastRM: An efficient and automatic explainability framework for multimodal generative models
Dec 02, 2024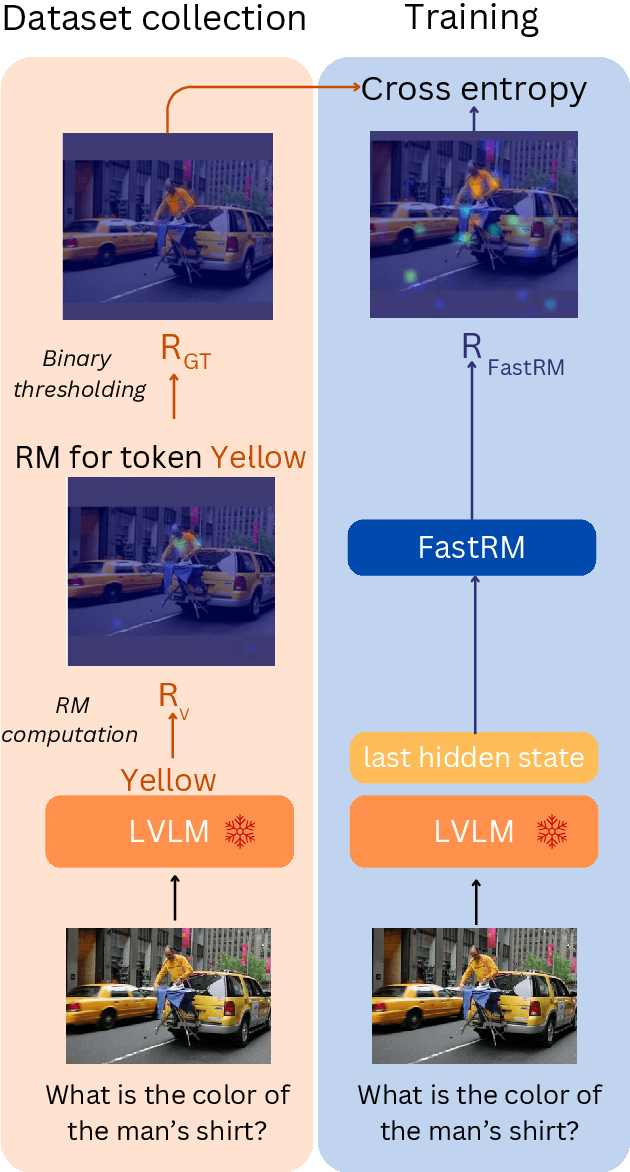
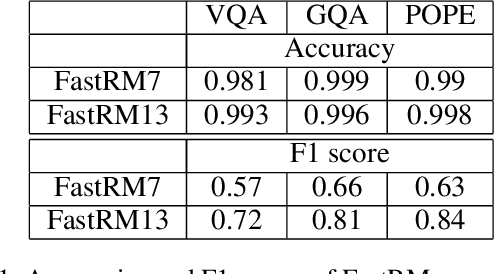
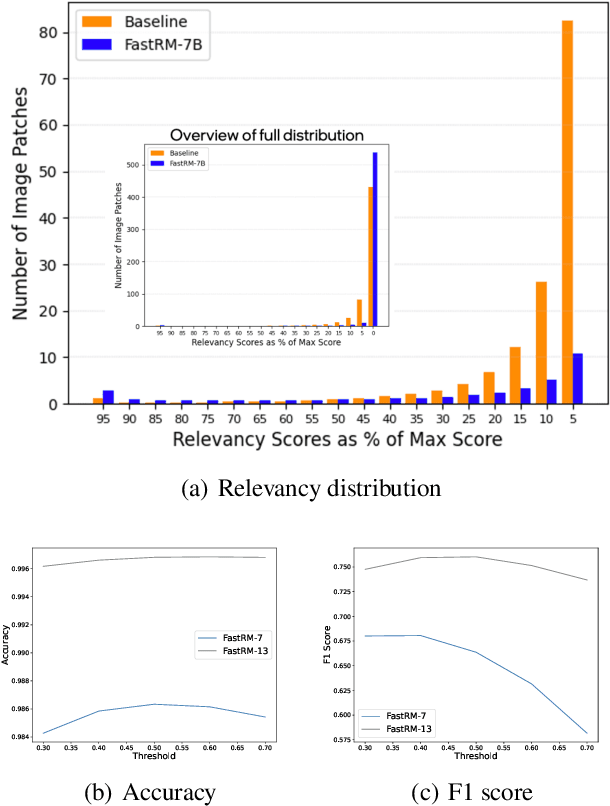
While Large Vision Language Models (LVLMs) have become masterly capable in reasoning over human prompts and visual inputs, they are still prone to producing responses that contain misinformation. Identifying incorrect responses that are not grounded in evidence has become a crucial task in building trustworthy AI. Explainability methods such as gradient-based relevancy maps on LVLM outputs can provide an insight on the decision process of models, however these methods are often computationally expensive and not suited for on-the-fly validation of outputs. In this work, we propose FastRM, an effective way for predicting the explainable Relevancy Maps of LVLM models. Experimental results show that employing FastRM leads to a 99.8% reduction in compute time for relevancy map generation and an 44.4% reduction in memory footprint for the evaluated LVLM, making explainable AI more efficient and practical, thereby facilitating its deployment in real-world applications.
L-MAGIC: Language Model Assisted Generation of Images with Coherence
Jun 03, 2024In the current era of generative AI breakthroughs, generating panoramic scenes from a single input image remains a key challenge. Most existing methods use diffusion-based iterative or simultaneous multi-view inpainting. However, the lack of global scene layout priors leads to subpar outputs with duplicated objects (e.g., multiple beds in a bedroom) or requires time-consuming human text inputs for each view. We propose L-MAGIC, a novel method leveraging large language models for guidance while diffusing multiple coherent views of 360 degree panoramic scenes. L-MAGIC harnesses pre-trained diffusion and language models without fine-tuning, ensuring zero-shot performance. The output quality is further enhanced by super-resolution and multi-view fusion techniques. Extensive experiments demonstrate that the resulting panoramic scenes feature better scene layouts and perspective view rendering quality compared to related works, with >70% preference in human evaluations. Combined with conditional diffusion models, L-MAGIC can accept various input modalities, including but not limited to text, depth maps, sketches, and colored scripts. Applying depth estimation further enables 3D point cloud generation and dynamic scene exploration with fluid camera motion. Code is available at https://github.com/IntelLabs/MMPano. The video presentation is available at https://youtu.be/XDMNEzH4-Ec?list=PLG9Zyvu7iBa0-a7ccNLO8LjcVRAoMn57s.