 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernelFoundry: Hardware-aware evolutionary GPU kernel optimization
Mar 12, 2026Optimizing GPU kernels presents a significantly greater challenge for large language models (LLMs) than standard code generation tasks, as it requires understanding hardware architecture, parallel optimization strategies, and performance profiling outputs. Most existing LLM-based approaches to kernel generation rely on simple prompting and feedback loops, incorporating hardware awareness only indirectly through profiling feedback. We introduce KernelFoundry, an evolutionary framework that efficiently explores the GPU kernel design space through three key mechanisms: (1) MAP-Elites quality-diversity search with kernel-specific behavioral dimensions to sustain exploration across diverse optimization strategies; (2) meta-prompt evolution, which co-evolves prompts with kernels to uncover task-specific optimization strategies, and (3) template-based parameter optimization to tune kernels to inputs and hardware. We evaluate this framework on KernelBench, robust-kbench, and custom tasks, generating SYCL kernels as a cross-platform GPU programming model and CUDA kernels for comparison to prior work. Our approach consistently outperforms the baseline methods, achieving an average speedup of 2.3x on KernelBench for SYCL. Moreover, KernelFoundry is implemented as a distributed framework with remote access to diverse hardware, enabling rapid benchmarking and featuring a flexible user input layer that supports kernel generation for a wide range of real-world use cases beyond benchmarking.
Rapid Salient Object Detection with Difference Convolutional Neural Networks
Jul 01, 2025This paper addresses the challenge of deploying salient object detection (SOD) on resource-constrained devices with real-time performance. While recent advances in deep neural networks have improved SOD, existing top-leading models are computationally expensive. We propose an efficient network design that combines traditional wisdom on SOD and the representation power of modern CNNs. Like biologically-inspired classical SOD methods relying on computing contrast cues to determine saliency of image regions, our model leverages Pixel Difference Convolutions (PDCs) to encode the feature contrasts. Differently, PDCs are incorporated in a CNN architecture so that the valuable contrast cues are extracted from rich feature maps. For efficiency, we introduce a difference convolution reparameterization (DCR) strategy that embeds PDCs into standard convolutions, eliminating computation and parameters at inference. Additionally, we introduce SpatioTemporal Difference Convolution (STDC) for video SOD, enhancing the standard 3D convolution with spatiotemporal contrast capture. Our models, SDNet for image SOD and STDNet for video SOD, achieve significant improvements in efficiency-accuracy trade-offs. On a Jetson Orin device, our models with $<$ 1M parameters operate at 46 FPS and 150 FPS on streamed images and videos, surpassing the second-best lightweight models in our experiments by more than $2\times$ and $3\times$ in speed with superior accuracy. Code will be available at https://github.com/hellozhuo/stdnet.git.
L-MAGIC: Language Model Assisted Generation of Images with Coherence
Jun 03, 2024In the current era of generative AI breakthroughs, generating panoramic scenes from a single input image remains a key challenge. Most existing methods use diffusion-based iterative or simultaneous multi-view inpainting. However, the lack of global scene layout priors leads to subpar outputs with duplicated objects (e.g., multiple beds in a bedroom) or requires time-consuming human text inputs for each view. We propose L-MAGIC, a novel method leveraging large language models for guidance while diffusing multiple coherent views of 360 degree panoramic scenes. L-MAGIC harnesses pre-trained diffusion and language models without fine-tuning, ensuring zero-shot performance. The output quality is further enhanced by super-resolution and multi-view fusion techniques. Extensive experiments demonstrate that the resulting panoramic scenes feature better scene layouts and perspective view rendering quality compared to related works, with >70% preference in human evaluations. Combined with conditional diffusion models, L-MAGIC can accept various input modalities, including but not limited to text, depth maps, sketches, and colored scripts. Applying depth estimation further enables 3D point cloud generation and dynamic scene exploration with fluid camera motion. Code is available at https://github.com/IntelLabs/MMPano. The video presentation is available at https://youtu.be/XDMNEzH4-Ec?list=PLG9Zyvu7iBa0-a7ccNLO8LjcVRAoMn57s.
LDM3D-VR: Latent Diffusion Model for 3D VR
Nov 06, 2023


Latent diffusion models have proven to be state-of-the-art in the creation and manipulation of visual outputs. However, as far as we know, the generation of depth maps jointly with RGB is still limited. We introduce LDM3D-VR, a suite of diffusion models targeting virtual reality development that includes LDM3D-pano and LDM3D-SR. These models enable the generation of panoramic RGBD based on textual prompts and the upscaling of low-resolution inputs to high-resolution RGBD, respectively. Our models are fine-tuned from existing pretrained models on datasets containing panoramic/high-resolution RGB images, depth maps and captions. Both models are evaluated in comparison to existing related methods.
MiDaS v3.1 -- A Model Zoo for Robust Monocular Relative Depth Estimation
Jul 26, 2023



We release MiDaS v3.1 for monocular depth estimation, offering a variety of new models based on different encoder backbones. This release is motivated by the success of transformers in computer vision, with a large variety of pretrained vision transformers now available. We explore how using the most promising vision transformers as image encoders impacts depth estimation quality and runtime of the MiDaS architecture. Our investigation also includes recent convolutional approaches that achieve comparable quality to vision transformers in image classification tasks. While the previous release MiDaS v3.0 solely leverages the vanilla vision transformer ViT, MiDaS v3.1 offers additional models based on BEiT, Swin, SwinV2, Next-ViT and LeViT. These models offer different performance-runtime tradeoffs. The best model improves the depth estimation quality by 28% while efficient models enable downstream tasks requiring high frame rates. We also describe the general process for integrating new backbones. A video summarizing the work can be found at https://youtu.be/UjaeNNFf9sE and the code is available at https://github.com/isl-org/MiDaS.
LDM3D: Latent Diffusion Model for 3D
May 21, 2023



This research paper proposes a Latent Diffusion Model for 3D (LDM3D) that generates both image and depth map data from a given text prompt, allowing users to generate RGBD images from text prompts. The LDM3D model is fine-tuned on a dataset of tuples containing an RGB image, depth map and caption, and validated through extensive experiments. We also develop an application called DepthFusion, which uses the generated RGB images and depth maps to create immersive and interactive 360-degree-view experiences using TouchDesigner. This technology has the potential to transform a wide range of industries, from entertainment and gaming to architecture and design. Overall, this paper presents a significant contribution to the field of generative AI and computer vision, and showcases the potential of LDM3D and DepthFusion to revolutionize content creation and digital experiences. A short video summarizing the approach can be found at https://t.ly/tdi2.
Monocular Visual-Inertial Depth Estimation
Mar 21, 2023



We present a visual-inertial depth estimation pipeline that integrates monocular depth estimation and visual-inertial odometry to produce dense depth estimates with metric scale. Our approach performs global scale and shift alignment against sparse metric depth, followed by learning-based dense alignment. We evaluate on the TartanAir and VOID datasets, observing up to 30% reduction in inverse RMSE with dense scale alignment relative to performing just global alignment alone. Our approach is especially competitive at low density; with just 150 sparse metric depth points, our dense-to-dense depth alignment method achieves over 50% lower iRMSE over sparse-to-dense depth completion by KBNet, currently the state of the art on VOID. We demonstrate successful zero-shot transfer from synthetic TartanAir to real-world VOID data and perform generalization tests on NYUv2 and VCU-RVI. Our approach is modular and is compatible with a variety of monocular depth estimation models. Video: https://youtu.be/IMwiKwSpshQ Code: https://github.com/isl-org/VI-Depth
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Feb 23, 2023



This paper tackles the problem of depth estimation from a single image. Existing work either focuses on generalization performance disregarding metric scale, i.e. relative depth estimation, or state-of-the-art results on specific datasets, i.e. metric depth estimation. We propose the first approach that combines both worlds, leading to a model with excellent generalization performance while maintaining metric scale. Our flagship model, ZoeD-M12-NK, is pre-trained on 12 datasets using relative depth and fine-tuned on two datasets using metric depth. We use a lightweight head with a novel bin adjustment design called metric bins module for each domain. During inference, each input image is automatically routed to the appropriate head using a latent classifier. Our framework admits multiple configurations depending on the datasets used for relative depth pre-training and metric fine-tuning. Without pre-training, we can already significantly improve the state of the art (SOTA) on the NYU Depth v2 indoor dataset. Pre-training on twelve datasets and fine-tuning on the NYU Depth v2 indoor dataset, we can further improve SOTA for a total of 21% in terms of relative absolute error (REL). Finally, ZoeD-M12-NK is the first model that can jointly train on multiple datasets (NYU Depth v2 and KITTI) without a significant drop in performance and achieve unprecedented zero-shot generalization performance to eight unseen datasets from both indoor and outdoor domains. The code and pre-trained models are publicly available at https://github.com/isl-org/ZoeDepth .
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
Mar 08, 2019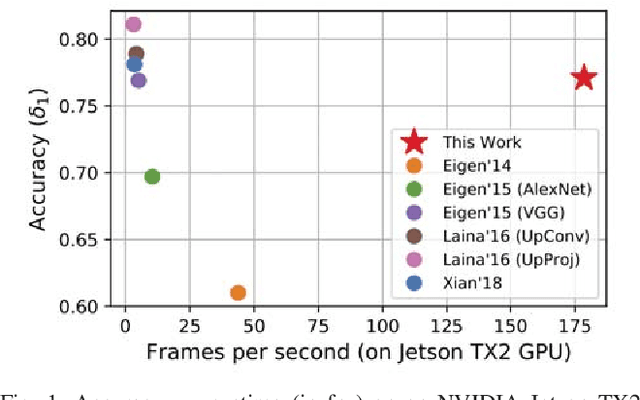

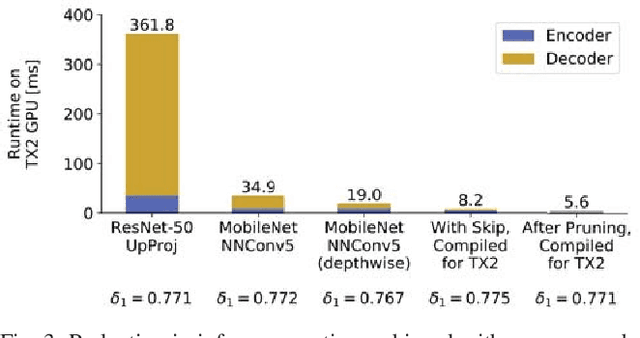

Depth sensing is a critical function for robotic tasks such as localization, mapping and obstacle detection. There has been a significant and growing interest in depth estimation from a single RGB image, due to the relatively low cost and size of monocular cameras. However, state-of-the-art single-view depth estimation algorithms are based on fairly complex deep neural networks that are too slow for real-time inference on an embedded platform, for instance, mounted on a micro aerial vehicle. In this paper, we address the problem of fast depth estimation on embedded systems. We propose an efficient and lightweight encoder-decoder network architecture and apply network pruning to further reduce computational complexity and latency. In particular, we focus on the design of a low-latency decoder. Our methodology demonstrates that it is possible to achieve similar accuracy as prior work on depth estimation, but at inference speeds that are an order of magnitude faster. Our proposed network, FastDepth, runs at 178 fps on an NVIDIA Jetson TX2 GPU and at 27 fps when using only the TX2 CPU, with active power consumption under 10 W. FastDepth achieves close to state-of-the-art accuracy on the NYU Depth v2 dataset. To the best of the authors' knowledge, this paper demonstrates real-time monocular depth estimation using a deep neural network with the lowest latency and highest throughput on an embedded platform that can be carried by a micro aerial vehicle.