 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL-MAGIC: Language Model Assisted Generation of Images with Coherence
Jun 03, 2024In the current era of generative AI breakthroughs, generating panoramic scenes from a single input image remains a key challenge. Most existing methods use diffusion-based iterative or simultaneous multi-view inpainting. However, the lack of global scene layout priors leads to subpar outputs with duplicated objects (e.g., multiple beds in a bedroom) or requires time-consuming human text inputs for each view. We propose L-MAGIC, a novel method leveraging large language models for guidance while diffusing multiple coherent views of 360 degree panoramic scenes. L-MAGIC harnesses pre-trained diffusion and language models without fine-tuning, ensuring zero-shot performance. The output quality is further enhanced by super-resolution and multi-view fusion techniques. Extensive experiments demonstrate that the resulting panoramic scenes feature better scene layouts and perspective view rendering quality compared to related works, with >70% preference in human evaluations. Combined with conditional diffusion models, L-MAGIC can accept various input modalities, including but not limited to text, depth maps, sketches, and colored scripts. Applying depth estimation further enables 3D point cloud generation and dynamic scene exploration with fluid camera motion. Code is available at https://github.com/IntelLabs/MMPano. The video presentation is available at https://youtu.be/XDMNEzH4-Ec?list=PLG9Zyvu7iBa0-a7ccNLO8LjcVRAoMn57s.
Reaching the Limit in Autonomous Racing: Optimal Control versus Reinforcement Learning
Oct 18, 2023A central question in robotics is how to design a control system for an agile mobile robot. This paper studies this question systematically, focusing on a challenging setting: autonomous drone racing. We show that a neural network controller trained with reinforcement learning (RL) outperformed optimal control (OC) methods in this setting. We then investigated which fundamental factors have contributed to the success of RL or have limited OC. Our study indicates that the fundamental advantage of RL over OC is not that it optimizes its objective better but that it optimizes a better objective. OC decomposes the problem into planning and control with an explicit intermediate representation, such as a trajectory, that serves as an interface. This decomposition limits the range of behaviors that can be expressed by the controller, leading to inferior control performance when facing unmodeled effects. In contrast, RL can directly optimize a task-level objective and can leverage domain randomization to cope with model uncertainty, allowing the discovery of more robust control responses. Our findings allowed us to push an agile drone to its maximum performance, achieving a peak acceleration greater than 12 times the gravitational acceleration and a peak velocity of 108 kilometers per hour. Our policy achieved superhuman control within minutes of training on a standard workstation. This work presents a milestone in agile robotics and sheds light on the role of RL and OC in robot control.
CLNeRF: Continual Learning Meets NeRF
Aug 28, 2023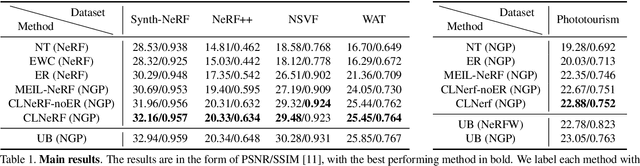
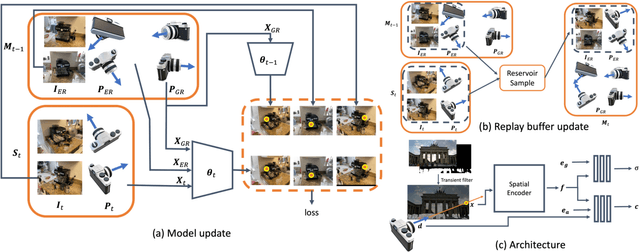
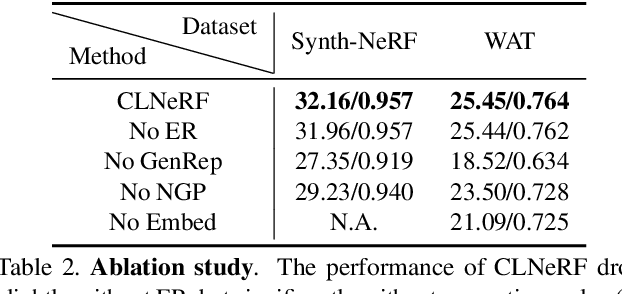

Novel view synthesis aims to render unseen views given a set of calibrated images. In practical applications, the coverage, appearance or geometry of the scene may change over time, with new images continuously being captured. Efficiently incorporating such continuous change is an open challenge. Standard NeRF benchmarks only involve scene coverage expansion. To study other practical scene changes, we propose a new dataset, World Across Time (WAT), consisting of scenes that change in appearance and geometry over time. We also propose a simple yet effective method, CLNeRF, which introduces continual learning (CL) to Neural Radiance Fields (NeRFs). CLNeRF combines generative replay and the Instant Neural Graphics Primitives (NGP) architecture to effectively prevent catastrophic forgetting and efficiently update the model when new data arrives. We also add trainable appearance and geometry embeddings to NGP, allowing a single compact model to handle complex scene changes. Without the need to store historical images, CLNeRF trained sequentially over multiple scans of a changing scene performs on-par with the upper bound model trained on all scans at once. Compared to other CL baselines CLNeRF performs much better across standard benchmarks and WAT. The source code, and the WAT dataset are available at https://github.com/IntelLabs/CLNeRF. Video presentation is available at: https://youtu.be/nLRt6OoDGq0?si=8yD6k-8MMBJInQPs