 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Reinforcement Learning for Quadrotors
Dec 17, 2024Reinforcement learning (RL) has shown great effectiveness in quadrotor control, enabling specialized policies to develop even human-champion-level performance in single-task scenarios. However, these specialized policies often struggle with novel tasks, requiring a complete retraining of the policy from scratch. To address this limitation, this paper presents a novel multi-task reinforcement learning (MTRL) framework tailored for quadrotor control, leveraging the shared physical dynamics of the platform to enhance sample efficiency and task performance. By employing a multi-critic architecture and shared task encoders, our framework facilitates knowledge transfer across tasks, enabling a single policy to execute diverse maneuvers, including high-speed stabilization, velocity tracking, and autonomous racing. Our experimental results, validated both in simulation and real-world scenarios, demonstrate that our framework outperforms baseline approaches in terms of sample efficiency and overall task performance.
Seeing Through Pixel Motion: Learning Obstacle Avoidance from Optical Flow with One Camera
Nov 07, 2024



Optical flow captures the motion of pixels in an image sequence over time, providing information about movement, depth, and environmental structure. Flying insects utilize this information to navigate and avoid obstacles, allowing them to execute highly agile maneuvers even in complex environments. Despite its potential, autonomous flying robots have yet to fully leverage this motion information to achieve comparable levels of agility and robustness. Challenges of control from optical flow include extracting accurate optical flow at high speeds, handling noisy estimation, and ensuring robust performance in complex environments. To address these challenges, we propose a novel end-to-end system for quadrotor obstacle avoidance using monocular optical flow. We develop an efficient differentiable simulator coupled with a simplified quadrotor model, allowing our policy to be trained directly through first-order gradient optimization. Additionally, we introduce a central flow attention mechanism and an action-guided active sensing strategy that enhances the policy's focus on task-relevant optical flow observations to enable more responsive decision-making during flight. Our system is validated both in simulation and the real world using an FPV racing drone. Despite being trained in a simple environment in simulation, our system is validated both in simulation and the real world using an FPV racing drone. Despite being trained in a simple environment in simulation, our system demonstrates agile and robust flight in various unknown, cluttered environments in the real world at speeds of up to 6m/s.
Learning Quadrotor Control From Visual Features Using Differentiable Simulation
Oct 21, 2024



The sample inefficiency of reinforcement learning (RL) remains a significant challenge in robotics. RL requires large-scale simulation and, still, can cause long training times, slowing down research and innovation. This issue is particularly pronounced in vision-based control tasks where reliable state estimates are not accessible. Differentiable simulation offers an alternative by enabling gradient back-propagation through the dynamics model, providing low-variance analytical policy gradients and, hence, higher sample efficiency. However, its usage for real-world robotic tasks has yet been limited. This work demonstrates the great potential of differentiable simulation for learning quadrotor control. We show that training in differentiable simulation significantly outperforms model-free RL in terms of both sample efficiency and training time, allowing a policy to learn to recover a quadrotor in seconds when providing vehicle state and in minutes when relying solely on visual features. The key to our success is two-fold. First, the use of a simple surrogate model for gradient computation greatly accelerates training without sacrificing control performance. Second, combining state representation learning with policy learning enhances convergence speed in tasks where only visual features are observable. These findings highlight the potential of differentiable simulation for real-world robotics and offer a compelling alternative to conventional RL approaches.
Residual Policy Learning for Perceptive Quadruped Control Using Differentiable Simulation
Oct 04, 2024



First-order Policy Gradient (FoPG) algorithms such as Backpropagation through Time and Analytical Policy Gradients leverage local simulation physics to accelerate policy search, significantly improving sample efficiency in robot control compared to standard model-free reinforcement learning. However, FoPG algorithms can exhibit poor learning dynamics in contact-rich tasks like locomotion. Previous approaches address this issue by alleviating contact dynamics via algorithmic or simulation innovations. In contrast, we propose guiding the policy search by learning a residual over a simple baseline policy. For quadruped locomotion, we find that the role of residual policy learning in FoPG-based training (FoPG RPL) is primarily to improve asymptotic rewards, compared to improving sample efficiency for model-free RL. Additionally, we provide insights on applying FoPG's to pixel-based local navigation, training a point-mass robot to convergence within seconds. Finally, we showcase the versatility of FoPG RPL by using it to train locomotion and perceptive navigation end-to-end on a quadruped in minutes.
Back to Newton's Laws: Learning Vision-based Agile Flight via Differentiable Physics
Jul 16, 2024
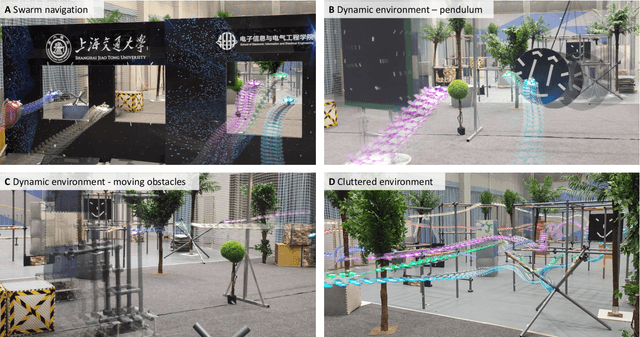
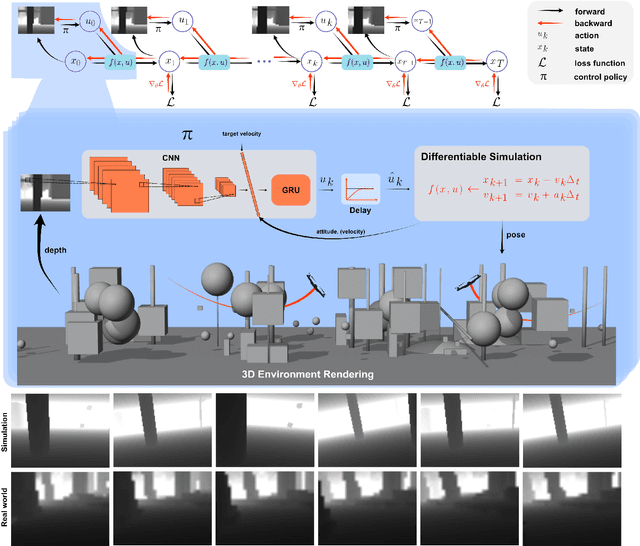
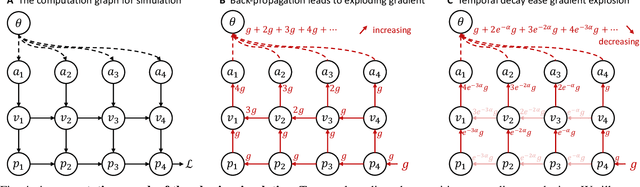
Swarm navigation in cluttered environments is a grand challenge in robotics. This work combines deep learning with first-principle physics through differentiable simulation to enable autonomous navigation of multiple aerial robots through complex environments at high speed. Our approach optimizes a neural network control policy directly by backpropagating loss gradients through the robot simulation using a simple point-mass physics model and a depth rendering engine. Despite this simplicity, our method excels in challenging tasks for both multi-agent and single-agent applications with zero-shot sim-to-real transfer. In multi-agent scenarios, our system demonstrates self-organized behavior, enabling autonomous coordination without communication or centralized planning - an achievement not seen in existing traditional or learning-based methods. In single-agent scenarios, our system achieves a 90% success rate in navigating through complex environments, significantly surpassing the 60% success rate of the previous state-of-the-art approach. Our system can operate without state estimation and adapt to dynamic obstacles. In real-world forest environments, it navigates at speeds up to 20 m/s, doubling the speed of previous imitation learning-based solutions. Notably, all these capabilities are deployed on a budget-friendly $21 computer, costing less than 5% of a GPU-equipped board used in existing systems. Video demonstrations are available at https://youtu.be/LKg9hJqc2cc.
Learning Quadruped Locomotion Using Differentiable Simulation
Mar 27, 2024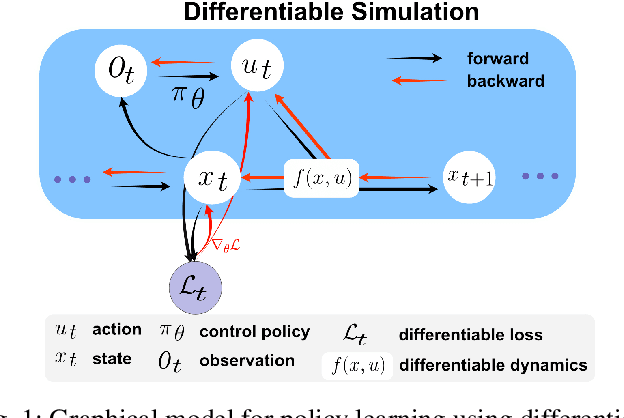
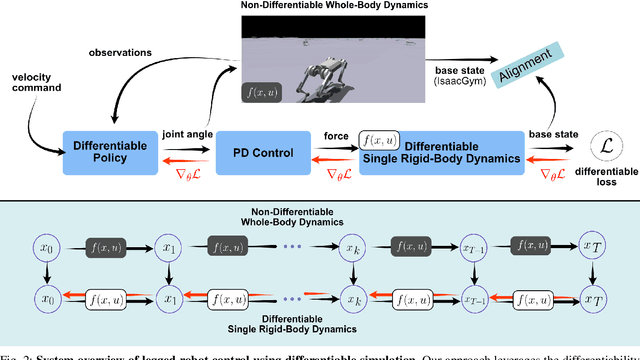
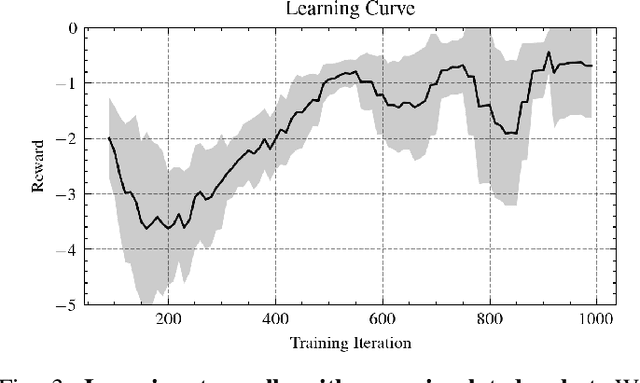
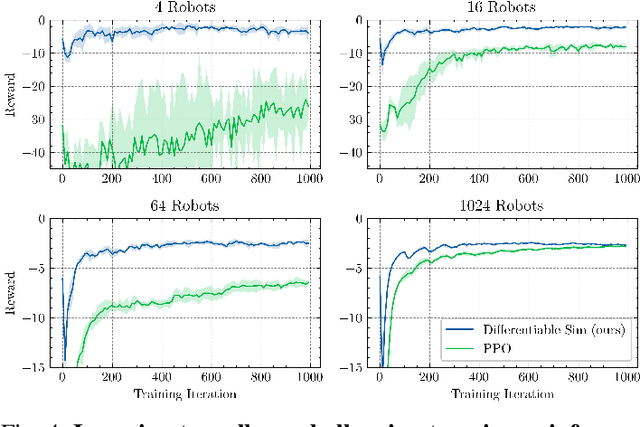
While most recent advancements in legged robot control have been driven by model-free reinforcement learning, we explore the potential of differentiable simulation. Differentiable simulation promises faster convergence and more stable training by computing low-variant first-order gradients using the robot model, but so far, its use for legged robot control has remained limited to simulation. The main challenge with differentiable simulation lies in the complex optimization landscape of robotic tasks due to discontinuities in contact-rich environments, e.g., quadruped locomotion. This work proposes a new, differentiable simulation framework to overcome these challenges. The key idea involves decoupling the complex whole-body simulation, which may exhibit discontinuities due to contact, into two separate continuous domains. Subsequently, we align the robot state resulting from the simplified model with a more precise, non-differentiable simulator to maintain sufficient simulation accuracy. Our framework enables learning quadruped walking in minutes using a single simulated robot without any parallelization. When augmented with GPU parallelization, our approach allows the quadruped robot to master diverse locomotion skills, including trot, pace, bound, and gallop, on challenging terrains in minutes. Additionally, our policy achieves robust locomotion performance in the real world zero-shot. To the best of our knowledge, this work represents the first demonstration of using differentiable simulation for controlling a real quadruped robot. This work provides several important insights into using differentiable simulations for legged locomotion in the real world.
Reaching the Limit in Autonomous Racing: Optimal Control versus Reinforcement Learning
Oct 18, 2023A central question in robotics is how to design a control system for an agile mobile robot. This paper studies this question systematically, focusing on a challenging setting: autonomous drone racing. We show that a neural network controller trained with reinforcement learning (RL) outperformed optimal control (OC) methods in this setting. We then investigated which fundamental factors have contributed to the success of RL or have limited OC. Our study indicates that the fundamental advantage of RL over OC is not that it optimizes its objective better but that it optimizes a better objective. OC decomposes the problem into planning and control with an explicit intermediate representation, such as a trajectory, that serves as an interface. This decomposition limits the range of behaviors that can be expressed by the controller, leading to inferior control performance when facing unmodeled effects. In contrast, RL can directly optimize a task-level objective and can leverage domain randomization to cope with model uncertainty, allowing the discovery of more robust control responses. Our findings allowed us to push an agile drone to its maximum performance, achieving a peak acceleration greater than 12 times the gravitational acceleration and a peak velocity of 108 kilometers per hour. Our policy achieved superhuman control within minutes of training on a standard workstation. This work presents a milestone in agile robotics and sheds light on the role of RL and OC in robot control.
Flymation: Interactive Animation for Flying Robots
Oct 18, 2023Trajectory visualization and animation play critical roles in robotics research. However, existing data visualization and animation tools often lack flexibility, scalability, and versatility, resulting in limited capability to fully explore and analyze flight data. To address this limitation, we introduce Flymation, a new flight trajectory visualization and animation tool. Built on the Unity3D engine, Flymation is an intuitive and interactive tool that allows users to visualize and analyze flight data in real time. Users can import data from various sources, including flight simulators and real-world data, and create customized visualizations with high-quality rendering. With Flymation, users can choose between trajectory snapshot and animation; both provide valuable insights into the behavior of the underlying autonomous system. Flymation represents an exciting step toward visualizing and interacting with large-scale data in robotics research.
Contrastive Learning for Enhancing Robust Scene Transfer in Vision-based Agile Flight
Sep 29, 2023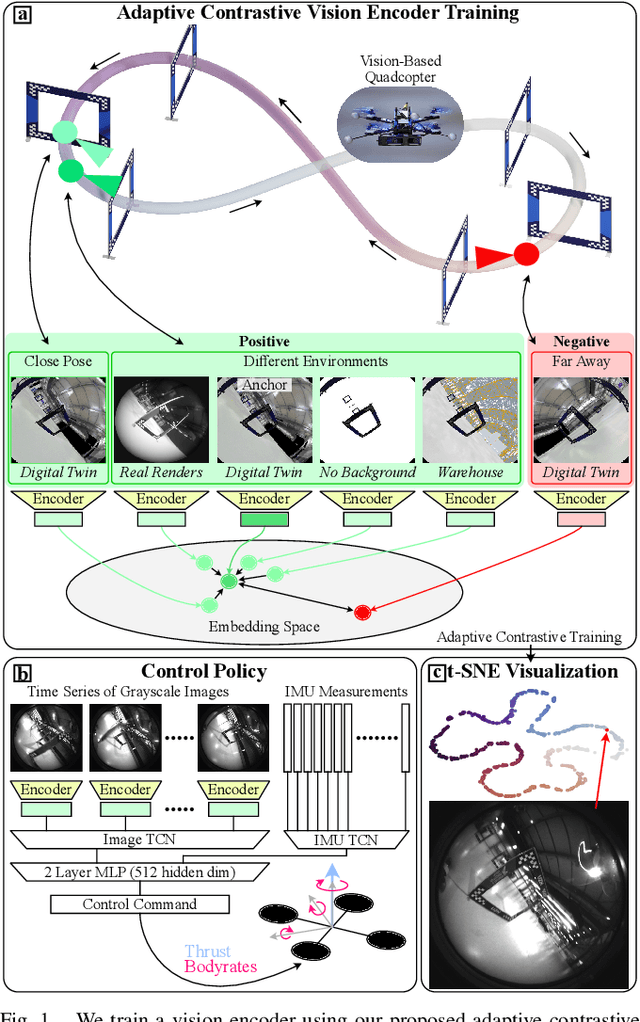
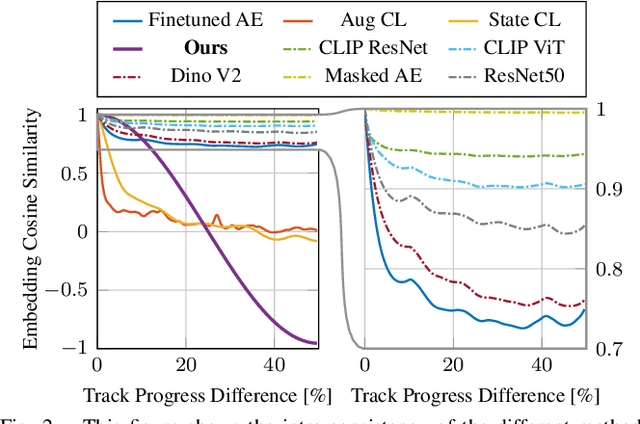
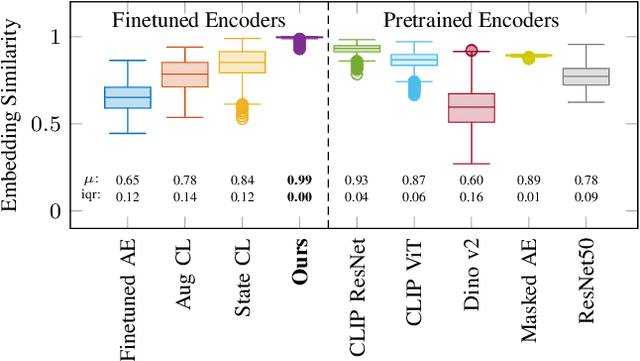

Scene transfer for vision-based mobile robotics applications is a highly relevant and challenging problem. The utility of a robot greatly depends on its ability to perform a task in the real world, outside of a well-controlled lab environment. Existing scene transfer end-to-end policy learning approaches often suffer from poor sample efficiency or limited generalization capabilities, making them unsuitable for mobile robotics applications. This work proposes an adaptive multi-pair contrastive learning strategy for visual representation learning that enables zero-shot scene transfer and real-world deployment. Control policies relying on the embedding are able to operate in unseen environments without the need for finetuning in the deployment environment. We demonstrate the performance of our approach on the task of agile, vision-based quadrotor flight. Extensive simulation and real-world experiments demonstrate that our approach successfully generalizes beyond the training domain and outperforms all baselines.
Learning to Walk and Fly with Adversarial Motion Priors
Sep 22, 2023



Robot multimodal locomotion encompasses the ability to transition between walking and flying, representing a significant challenge in robotics. This work presents an approach that enables automatic smooth transitions between legged and aerial locomotion. Leveraging the concept of Adversarial Motion Priors, our method allows the robot to imitate motion datasets and accomplish the desired task without the need for complex reward functions. The robot learns walking patterns from human-like gaits and aerial locomotion patterns from motions obtained using trajectory optimization. Through this process, the robot adapts the locomotion scheme based on environmental feedback using reinforcement learning, with the spontaneous emergence of mode-switching behavior. The results highlight the potential for achieving multimodal locomotion in aerial humanoid robotics through automatic control of walking and flying modes, paving the way for applications in diverse domains such as search and rescue, surveillance, and exploration missions. This research contributes to advancing the capabilities of aerial humanoid robots in terms of versatile locomotion in various environments.