 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline DNN-driven Nonlinear MPC for Stylistic Humanoid Robot Walking with Step Adjustment
Oct 10, 2024



This paper presents a three-layered architecture that enables stylistic locomotion with online contact location adjustment. Our method combines an autoregressive Deep Neural Network (DNN) acting as a trajectory generation layer with a model-based trajectory adjustment and trajectory control layers. The DNN produces centroidal and postural references serving as an initial guess and regularizer for the other layers. Being the DNN trained on human motion capture data, the resulting robot motion exhibits locomotion patterns, resembling a human walking style. The trajectory adjustment layer utilizes non-linear optimization to ensure dynamically feasible center of mass (CoM) motion while addressing step adjustments. We compare two implementations of the trajectory adjustment layer: one as a receding horizon planner (RHP) and the other as a model predictive controller (MPC). To enhance MPC performance, we introduce a Kalman filter to reduce measurement noise. The filter parameters are automatically tuned with a Genetic Algorithm. Experimental results on the ergoCub humanoid robot demonstrate the system's ability to prevent falls, replicate human walking styles, and withstand disturbances up to 68 Newton. Website: https://sites.google.com/view/dnn-mpc-walking Youtube video: https://www.youtube.com/watch?v=x3tzEfxO-xQ
Learning to Walk and Fly with Adversarial Motion Priors
Sep 22, 2023Robot multimodal locomotion encompasses the ability to transition between walking and flying, representing a significant challenge in robotics. This work presents an approach that enables automatic smooth transitions between legged and aerial locomotion. Leveraging the concept of Adversarial Motion Priors, our method allows the robot to imitate motion datasets and accomplish the desired task without the need for complex reward functions. The robot learns walking patterns from human-like gaits and aerial locomotion patterns from motions obtained using trajectory optimization. Through this process, the robot adapts the locomotion scheme based on environmental feedback using reinforcement learning, with the spontaneous emergence of mode-switching behavior. The results highlight the potential for achieving multimodal locomotion in aerial humanoid robotics through automatic control of walking and flying modes, paving the way for applications in diverse domains such as search and rescue, surveillance, and exploration missions. This research contributes to advancing the capabilities of aerial humanoid robots in terms of versatile locomotion in various environments.
iCub3 Avatar System
Mar 14, 2022
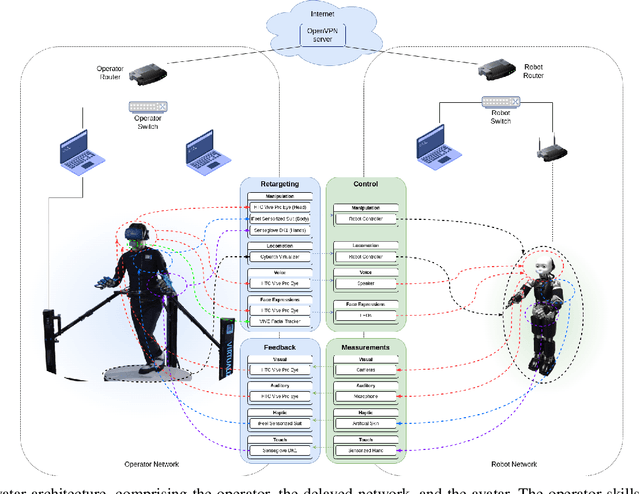
We present an avatar system that enables a human operator to visit a remote location via iCub3, a new humanoid robot developed at the Italian Institute of Technology (IIT) paving the way for the next generation of the iCub platforms. On the one hand, we present the humanoid iCub3 that plays the role of the robotic avatar. Particular attention is paid to the differences between iCub3 and the classical iCub humanoid robot. On the other hand, we present the set of technologies of the avatar system at the operator side. They are mainly composed of iFeel, namely, IIT lightweight non-invasive wearable devices for motion tracking and haptic feedback, and of non-IIT technologies designed for virtual reality ecosystems. Finally, we show the effectiveness of the avatar system by describing a demonstration involving a realtime teleoperation of the iCub3. The robot is located in Venice, Biennale di Venezia, while the human operator is at more than 290km distance and located in Genoa, IIT. Using a standard fiber optic internet connection, the avatar system transports the operator locomotion, manipulation, voice, and face expressions to the iCub3 with visual, auditory, haptic and touch feedback.
On the Emergence of Whole-body Strategies from Humanoid Robot Push-recovery Learning
Apr 29, 2021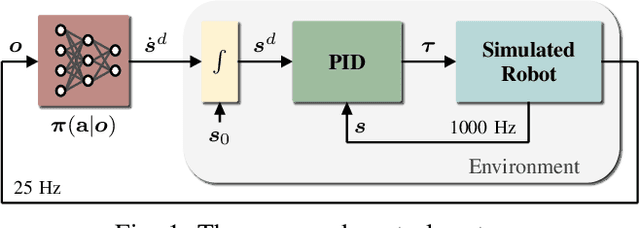
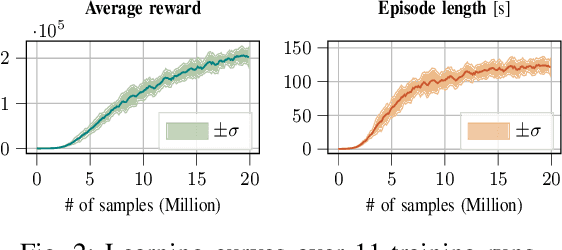
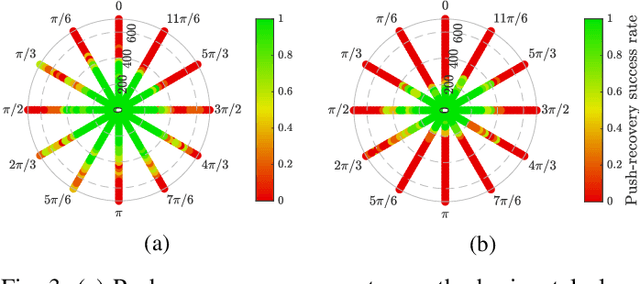

Balancing and push-recovery are essential capabilities enabling humanoid robots to solve complex locomotion tasks. In this context, classical control systems tend to be based on simplified physical models and hard-coded strategies. Although successful in specific scenarios, this approach requires demanding tuning of parameters and switching logic between specifically-designed controllers for handling more general perturbations. We apply model-free Deep Reinforcement Learning for training a general and robust humanoid push-recovery policy in a simulation environment. Our method targets high-dimensional whole-body humanoid control and is validated on the iCub humanoid. Reward components incorporating expert knowledge on humanoid control enable fast learning of several robust behaviors by the same policy, spanning the entire body. We validate our method with extensive quantitative analyses in simulation, including out-of-sample tasks which demonstrate policy robustness and generalization, both key requirements towards real-world robot deployment.