 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception-Aware Time-Optimal Planning for Quadrotor Waypoint Flight
Mar 04, 2026Agile quadrotor flight pushes the limits of control, actuation, and onboard perception. While time-optimal trajectory planning has been extensively studied, existing approaches typically neglect the tight coupling between vehicle dynamics, environmental geometry, and the visual requirements of onboard state estimation. As a result, trajectories that are dynamically feasible may fail in closed-loop execution due to degraded visual quality. This paper introduces a unified time-optimal trajectory optimization framework for vision-based quadrotors that explicitly incorporates perception constraints alongside full nonlinear dynamics, rotor actuation limits, aerodynamic effects, camera field-of-view constraints, and convex geometric gate representations. The proposed formulation solves minimum-time lap trajectories for arbitrary racetracks with diverse gate shapes and orientations, while remaining numerically robust and computationally efficient. We derive an information-theoretic position uncertainty metric to quantify visual state-estimation quality and integrate it into the planner through three perception objectives: position uncertainty minimization, sequential field-of-view constraints, and look-ahead alignment. This enables systematic exploration of the trade-offs between speed and perceptual reliability. To accurately track the resulting perception-aware trajectories, we develop a model predictive contouring tracking controller that separates lateral and progress errors. Experiments demonstrate real-world flight speeds up to 9.8 m/s with 0.07 m average tracking error, and closed-loop success rates improved from 55% to 100% on a challenging Split-S course. The proposed system provides a scalable benchmark for studying the fundamental limits of perception-aware, time-optimal autonomous flight.
The Reality Gap in Robotics: Challenges, Solutions, and Best Practices
Oct 23, 2025Machine learning has facilitated significant advancements across various robotics domains, including navigation, locomotion, and manipulation. Many such achievements have been driven by the extensive use of simulation as a critical tool for training and testing robotic systems prior to their deployment in real-world environments. However, simulations consist of abstractions and approximations that inevitably introduce discrepancies between simulated and real environments, known as the reality gap. These discrepancies significantly hinder the successful transfer of systems from simulation to the real world. Closing this gap remains one of the most pressing challenges in robotics. Recent advances in sim-to-real transfer have demonstrated promising results across various platforms, including locomotion, navigation, and manipulation. By leveraging techniques such as domain randomization, real-to-sim transfer, state and action abstractions, and sim-real co-training, many works have overcome the reality gap. However, challenges persist, and a deeper understanding of the reality gap's root causes and solutions is necessary. In this survey, we present a comprehensive overview of the sim-to-real landscape, highlighting the causes, solutions, and evaluation metrics for the reality gap and sim-to-real transfer.
Learning Real-World Acrobatic Flight from Human Preferences
Aug 26, 2025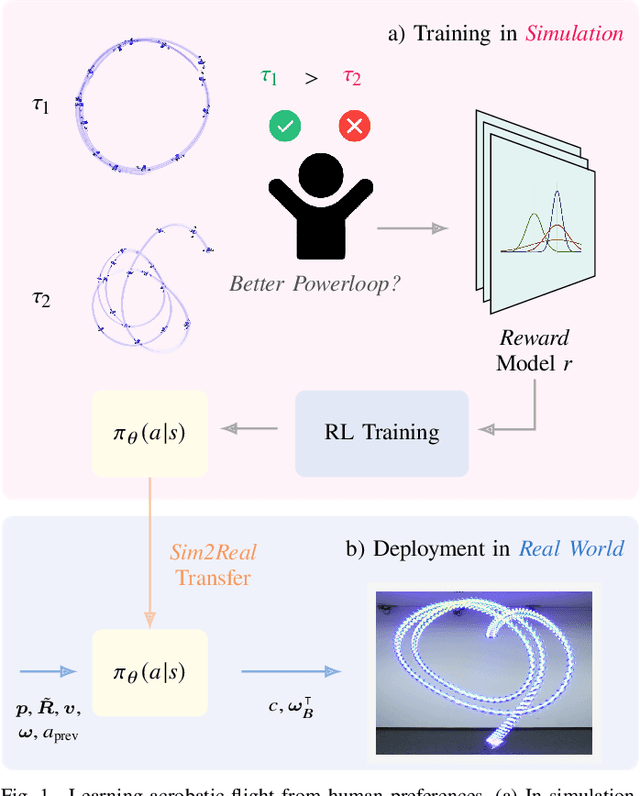
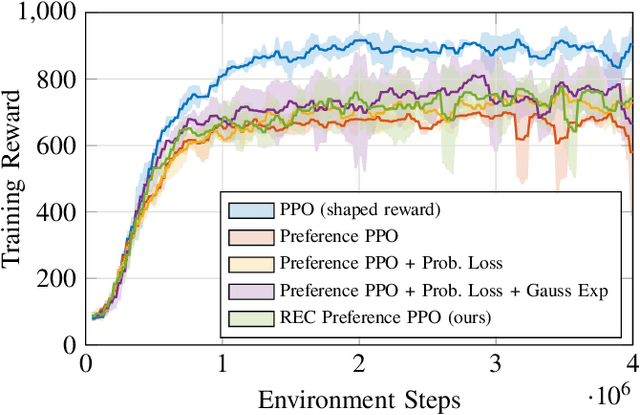


Preference-based reinforcement learning (PbRL) enables agents to learn control policies without requiring manually designed reward functions, making it well-suited for tasks where objectives are difficult to formalize or inherently subjective. Acrobatic flight poses a particularly challenging problem due to its complex dynamics, rapid movements, and the importance of precise execution. In this work, we explore the use of PbRL for agile drone control, focusing on the execution of dynamic maneuvers such as powerloops. Building on Preference-based Proximal Policy Optimization (Preference PPO), we propose Reward Ensemble under Confidence (REC), an extension to the reward learning objective that improves preference modeling and learning stability. Our method achieves 88.4% of the shaped reward performance, compared to 55.2% with standard Preference PPO. We train policies in simulation and successfully transfer them to real-world drones, demonstrating multiple acrobatic maneuvers where human preferences emphasize stylistic qualities of motion. Furthermore, we demonstrate the applicability of our probabilistic reward model in a representative MuJoCo environment for continuous control. Finally, we highlight the limitations of manually designed rewards, observing only 60.7% agreement with human preferences. These results underscore the effectiveness of PbRL in capturing complex, human-centered objectives across both physical and simulated domains.
Accelerating Model-Based Reinforcement Learning with State-Space World Models
Feb 27, 2025Reinforcement learning (RL) is a powerful approach for robot learning. However, model-free RL (MFRL) requires a large number of environment interactions to learn successful control policies. This is due to the noisy RL training updates and the complexity of robotic systems, which typically involve highly non-linear dynamics and noisy sensor signals. In contrast, model-based RL (MBRL) not only trains a policy but simultaneously learns a world model that captures the environment's dynamics and rewards. The world model can either be used for planning, for data collection, or to provide first-order policy gradients for training. Leveraging a world model significantly improves sample efficiency compared to model-free RL. However, training a world model alongside the policy increases the computational complexity, leading to longer training times that are often intractable for complex real-world scenarios. In this work, we propose a new method for accelerating model-based RL using state-space world models. Our approach leverages state-space models (SSMs) to parallelize the training of the dynamics model, which is typically the main computational bottleneck. Additionally, we propose an architecture that provides privileged information to the world model during training, which is particularly relevant for partially observable environments. We evaluate our method in several real-world agile quadrotor flight tasks, involving complex dynamics, for both fully and partially observable environments. We demonstrate a significant speedup, reducing the world model training time by up to 10 times, and the overall MBRL training time by up to 4 times. This benefit comes without compromising performance, as our method achieves similar sample efficiency and task rewards to state-of-the-art MBRL methods.
Dream to Fly: Model-Based Reinforcement Learning for Vision-Based Drone Flight
Jan 24, 2025Autonomous drone racing has risen as a challenging robotic benchmark for testing the limits of learning, perception, planning, and control. Expert human pilots are able to agilely fly a drone through a race track by mapping the real-time feed from a single onboard camera directly to control commands. Recent works in autonomous drone racing attempting direct pixel-to-commands control policies (without explicit state estimation) have relied on either intermediate representations that simplify the observation space or performed extensive bootstrapping using Imitation Learning (IL). This paper introduces an approach that learns policies from scratch, allowing a quadrotor to autonomously navigate a race track by directly mapping raw onboard camera pixels to control commands, just as human pilots do. By leveraging model-based reinforcement learning~(RL) - specifically DreamerV3 - we train visuomotor policies capable of agile flight through a race track using only raw pixel observations. While model-free RL methods such as PPO struggle to learn under these conditions, DreamerV3 efficiently acquires complex visuomotor behaviors. Moreover, because our policies learn directly from pixel inputs, the perception-aware reward term employed in previous RL approaches to guide the training process is no longer needed. Our experiments demonstrate in both simulation and real-world flight how the proposed approach can be deployed on agile quadrotors. This approach advances the frontier of vision-based autonomous flight and shows that model-based RL is a promising direction for real-world robotics.
Demonstrating Agile Flight from Pixels without State Estimation
Jun 18, 2024


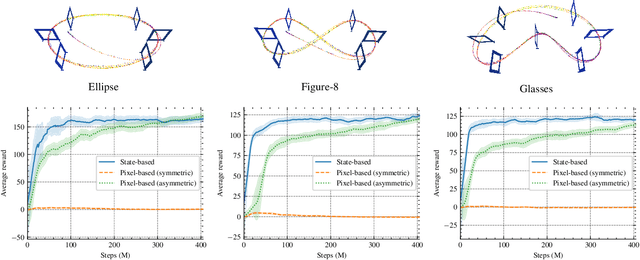
Quadrotors are among the most agile flying robots. Despite recent advances in learning-based control and computer vision, autonomous drones still rely on explicit state estimation. On the other hand, human pilots only rely on a first-person-view video stream from the drone onboard camera to push the platform to its limits and fly robustly in unseen environments. To the best of our knowledge, we present the first vision-based quadrotor system that autonomously navigates through a sequence of gates at high speeds while directly mapping pixels to control commands. Like professional drone-racing pilots, our system does not use explicit state estimation and leverages the same control commands humans use (collective thrust and body rates). We demonstrate agile flight at speeds up to 40km/h with accelerations up to 2g. This is achieved by training vision-based policies with reinforcement learning (RL). The training is facilitated using an asymmetric actor-critic with access to privileged information. To overcome the computational complexity during image-based RL training, we use the inner edges of the gates as a sensor abstraction. This simple yet robust, task-relevant representation can be simulated during training without rendering images. During deployment, a Swin-transformer-based gate detector is used. Our approach enables autonomous agile flight with standard, off-the-shelf hardware. Although our demonstration focuses on drone racing, we believe that our method has an impact beyond drone racing and can serve as a foundation for future research into real-world applications in structured environments.
Time-Optimal Flight with Safety Constraints and Data-driven Dynamics
Mar 26, 2024
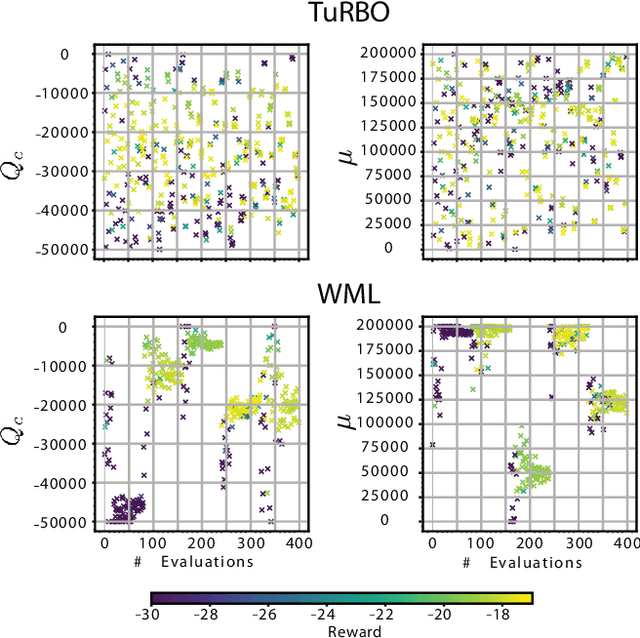


Time-optimal quadrotor flight is an extremely challenging problem due to the limited control authority encountered at the limit of handling. Model Predictive Contouring Control (MPCC) has emerged as a leading model-based approach for time optimization problems such as drone racing. However, the standard MPCC formulation used in quadrotor racing introduces the notion of the gates directly in the cost function, creating a multi-objective optimization that continuously trades off between maximizing progress and tracking the path accurately. This paper introduces three key components that enhance the MPCC approach for drone racing. First and foremost, we provide safety guarantees in the form of a constraint and terminal set. The safety set is designed as a spatial constraint which prevents gate collisions while allowing for time-optimization only in the cost function. Second, we augment the existing first principles dynamics with a residual term that captures complex aerodynamic effects and thrust forces learned directly from real world data. Third, we use Trust Region Bayesian Optimization (TuRBO), a state of the art global Bayesian Optimization algorithm, to tune the hyperparameters of the MPC controller given a sparse reward based on lap time minimization. The proposed approach achieves similar lap times to the best state-of-the-art RL and outperforms the best time-optimal controller while satisfying constraints. In both simulation and real-world, our approach consistently prevents gate crashes with 100\% success rate, while pushing the quadrotor to its physical limit reaching speeds of more than 80km/h.
Bootstrapping Reinforcement Learning with Imitation for Vision-Based Agile Flight
Mar 18, 2024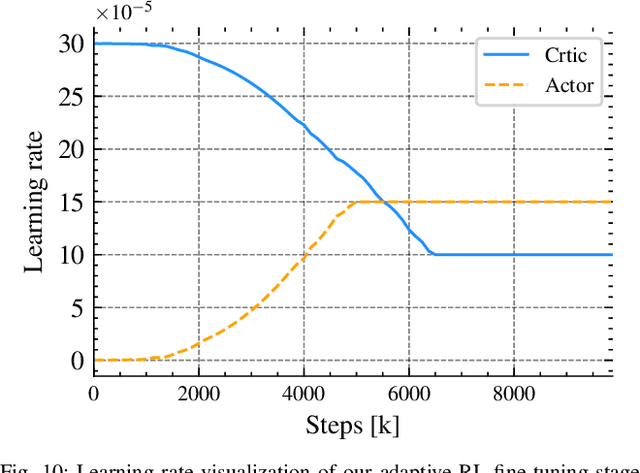
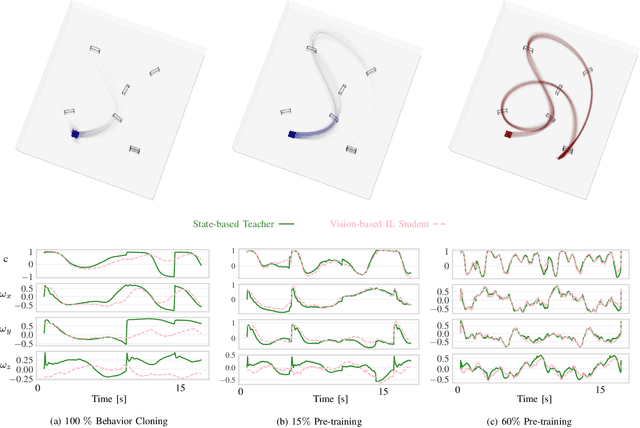


We combine the effectiveness of Reinforcement Learning (RL) and the efficiency of Imitation Learning (IL) in the context of vision-based, autonomous drone racing. We focus on directly processing visual input without explicit state estimation. While RL offers a general framework for learning complex controllers through trial and error, it faces challenges regarding sample efficiency and computational demands due to the high dimensionality of visual inputs. Conversely, IL demonstrates efficiency in learning from visual demonstrations but is limited by the quality of those demonstrations and faces issues like covariate shift. To overcome these limitations, we propose a novel training framework combining RL and IL's advantages. Our framework involves three stages: initial training of a teacher policy using privileged state information, distilling this policy into a student policy using IL, and performance-constrained adaptive RL fine-tuning. Our experiments in both simulated and real-world environments demonstrate that our approach achieves superior performance and robustness than IL or RL alone in navigating a quadrotor through a racing course using only visual information without explicit state estimation.
Reaching the Limit in Autonomous Racing: Optimal Control versus Reinforcement Learning
Oct 18, 2023A central question in robotics is how to design a control system for an agile mobile robot. This paper studies this question systematically, focusing on a challenging setting: autonomous drone racing. We show that a neural network controller trained with reinforcement learning (RL) outperformed optimal control (OC) methods in this setting. We then investigated which fundamental factors have contributed to the success of RL or have limited OC. Our study indicates that the fundamental advantage of RL over OC is not that it optimizes its objective better but that it optimizes a better objective. OC decomposes the problem into planning and control with an explicit intermediate representation, such as a trajectory, that serves as an interface. This decomposition limits the range of behaviors that can be expressed by the controller, leading to inferior control performance when facing unmodeled effects. In contrast, RL can directly optimize a task-level objective and can leverage domain randomization to cope with model uncertainty, allowing the discovery of more robust control responses. Our findings allowed us to push an agile drone to its maximum performance, achieving a peak acceleration greater than 12 times the gravitational acceleration and a peak velocity of 108 kilometers per hour. Our policy achieved superhuman control within minutes of training on a standard workstation. This work presents a milestone in agile robotics and sheds light on the role of RL and OC in robot control.
Learning to Walk and Fly with Adversarial Motion Priors
Sep 22, 2023



Robot multimodal locomotion encompasses the ability to transition between walking and flying, representing a significant challenge in robotics. This work presents an approach that enables automatic smooth transitions between legged and aerial locomotion. Leveraging the concept of Adversarial Motion Priors, our method allows the robot to imitate motion datasets and accomplish the desired task without the need for complex reward functions. The robot learns walking patterns from human-like gaits and aerial locomotion patterns from motions obtained using trajectory optimization. Through this process, the robot adapts the locomotion scheme based on environmental feedback using reinforcement learning, with the spontaneous emergence of mode-switching behavior. The results highlight the potential for achieving multimodal locomotion in aerial humanoid robotics through automatic control of walking and flying modes, paving the way for applications in diverse domains such as search and rescue, surveillance, and exploration missions. This research contributes to advancing the capabilities of aerial humanoid robots in terms of versatile locomotion in various environments.