 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Event Pretraining with Foundation Model Alignment
Mar 24, 2026Event cameras provide robust visual signals under fast motion and challenging illumination conditions thanks to their microsecond latency and high dynamic range. However, their unique sensing characteristics and limited labeled data make it challenging to train event-based visual foundation models (VFMs), which are crucial for learning visual features transferable across tasks. To tackle this problem, we propose GEP (Generative Event Pretraining), a two-stage framework that transfers semantic knowledge learned from internet-scale image datasets to event data while learning event-specific temporal dynamics. First, an event encoder is aligned to a frozen VFM through a joint regression-contrastive objective, grounding event features in image semantics. Second, a transformer backbone is autoregressively pretrained on mixed event-image sequences to capture the temporal structure unique to events. Our approach outperforms state-of-the-art event pretraining methods on a diverse range of downstream tasks, including object recognition, segmentation, and depth estimation. Together, VFM-guided alignment and generative sequence modeling yield a semantically rich, temporally aware event model that generalizes robustly across domains.
Approximate Imitation Learning for Event-based Quadrotor Flight in Cluttered Environments
Mar 08, 2026Event cameras offer high temporal resolution and low latency, making them ideal sensors for high-speed robotic applications where conventional cameras suffer from image degradations such as motion blur. In addition, their low power consumption can enhance endurance, which is critical for resource-constrained platforms. Motivated by these properties, we present a novel approach that enables a quadrotor to fly through cluttered environments at high speed by perceiving the environment with a single event camera. Our proposed method employs an end-to-end neural network trained to map event data directly to control commands, eliminating the reliance on standard cameras. To enable efficient training in simulation, where rendering synthetic event data is computationally expensive, we propose Approximate Imitation Learning, a novel imitation learning framework. Our approach leverages a large-scale offline dataset to learn a task-specific representation space. Subsequently, the policy is trained through online interactions that rely solely on lightweight, simulated state information, eliminating the need to render events during training. This enables the efficient training of event-based control policies for fast quadrotor flight, highlighting the potential of our framework for other modalities where data simulation is costly or impractical. Our approach outperforms standard imitation learning baselines in simulation and demonstrates robust performance in real-world flight tests, achieving speeds up to 9.8 ms-1 in cluttered environments.
Perception-Aware Time-Optimal Planning for Quadrotor Waypoint Flight
Mar 04, 2026Agile quadrotor flight pushes the limits of control, actuation, and onboard perception. While time-optimal trajectory planning has been extensively studied, existing approaches typically neglect the tight coupling between vehicle dynamics, environmental geometry, and the visual requirements of onboard state estimation. As a result, trajectories that are dynamically feasible may fail in closed-loop execution due to degraded visual quality. This paper introduces a unified time-optimal trajectory optimization framework for vision-based quadrotors that explicitly incorporates perception constraints alongside full nonlinear dynamics, rotor actuation limits, aerodynamic effects, camera field-of-view constraints, and convex geometric gate representations. The proposed formulation solves minimum-time lap trajectories for arbitrary racetracks with diverse gate shapes and orientations, while remaining numerically robust and computationally efficient. We derive an information-theoretic position uncertainty metric to quantify visual state-estimation quality and integrate it into the planner through three perception objectives: position uncertainty minimization, sequential field-of-view constraints, and look-ahead alignment. This enables systematic exploration of the trade-offs between speed and perceptual reliability. To accurately track the resulting perception-aware trajectories, we develop a model predictive contouring tracking controller that separates lateral and progress errors. Experiments demonstrate real-world flight speeds up to 9.8 m/s with 0.07 m average tracking error, and closed-loop success rates improved from 55% to 100% on a challenging Split-S course. The proposed system provides a scalable benchmark for studying the fundamental limits of perception-aware, time-optimal autonomous flight.
Learning Agile Quadrotor Flight in the Real World
Feb 10, 2026Learning-based controllers have achieved impressive performance in agile quadrotor flight but typically rely on massive training in simulation, necessitating accurate system identification for effective Sim2Real transfer. However, even with precise modeling, fixed policies remain susceptible to out-of-distribution scenarios, ranging from external aerodynamic disturbances to internal hardware degradation. To ensure safety under these evolving uncertainties, such controllers are forced to operate with conservative safety margins, inherently constraining their agility outside of controlled settings. While online adaptation offers a potential remedy, safely exploring physical limits remains a critical bottleneck due to data scarcity and safety risks. To bridge this gap, we propose a self-adaptive framework that eliminates the need for precise system identification or offline Sim2Real transfer. We introduce Adaptive Temporal Scaling (ATS) to actively explore platform physical limits, and employ online residual learning to augment a simple nominal model. {Based on the learned hybrid model, we further propose Real-world Anchored Short-horizon Backpropagation Through Time (RASH-BPTT) to achieve efficient and robust in-flight policy updates. Extensive experiments demonstrate that our quadrotor reliably executes agile maneuvers near actuator saturation limits. The system evolves a conservative base policy with a peak speed of 1.9 m/s to 7.3 m/s within approximately 100 seconds of flight time. These findings underscore that real-world adaptation serves not merely to compensate for modeling errors, but as a practical mechanism for sustained performance improvement in aggressive flight regimes.
The Reality Gap in Robotics: Challenges, Solutions, and Best Practices
Oct 23, 2025Machine learning has facilitated significant advancements across various robotics domains, including navigation, locomotion, and manipulation. Many such achievements have been driven by the extensive use of simulation as a critical tool for training and testing robotic systems prior to their deployment in real-world environments. However, simulations consist of abstractions and approximations that inevitably introduce discrepancies between simulated and real environments, known as the reality gap. These discrepancies significantly hinder the successful transfer of systems from simulation to the real world. Closing this gap remains one of the most pressing challenges in robotics. Recent advances in sim-to-real transfer have demonstrated promising results across various platforms, including locomotion, navigation, and manipulation. By leveraging techniques such as domain randomization, real-to-sim transfer, state and action abstractions, and sim-real co-training, many works have overcome the reality gap. However, challenges persist, and a deeper understanding of the reality gap's root causes and solutions is necessary. In this survey, we present a comprehensive overview of the sim-to-real landscape, highlighting the causes, solutions, and evaluation metrics for the reality gap and sim-to-real transfer.
What Matters in RL-Based Methods for Object-Goal Navigation? An Empirical Study and A Unified Framework
Oct 02, 2025
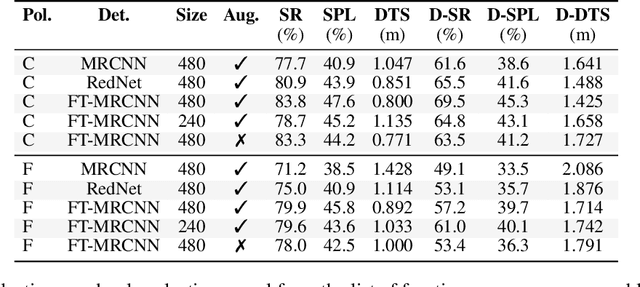
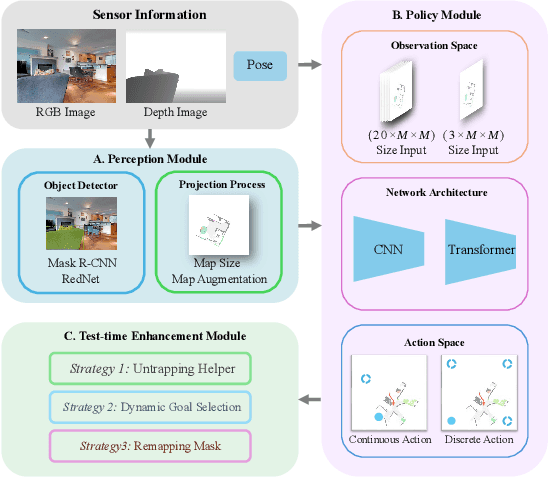
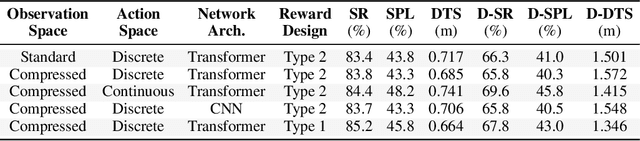
Object-Goal Navigation (ObjectNav) is a critical component toward deploying mobile robots in everyday, uncontrolled environments such as homes, schools, and workplaces. In this context, a robot must locate target objects in previously unseen environments using only its onboard perception. Success requires the integration of semantic understanding, spatial reasoning, and long-horizon planning, which is a combination that remains extremely challenging. While reinforcement learning (RL) has become the dominant paradigm, progress has spanned a wide range of design choices, yet the field still lacks a unifying analysis to determine which components truly drive performance. In this work, we conduct a large-scale empirical study of modular RL-based ObjectNav systems, decomposing them into three key components: perception, policy, and test-time enhancement. Through extensive controlled experiments, we isolate the contribution of each and uncover clear trends: perception quality and test-time strategies are decisive drivers of performance, whereas policy improvements with current methods yield only marginal gains. Building on these insights, we propose practical design guidelines and demonstrate an enhanced modular system that surpasses State-of-the-Art (SotA) methods by 6.6% on SPL and by a 2.7% success rate. We also introduce a human baseline under identical conditions, where experts achieve an average 98% success, underscoring the gap between RL agents and human-level navigation. Our study not only sets the SotA performance but also provides principled guidance for future ObjectNav development and evaluation.
Learning on the Fly: Rapid Policy Adaptation via Differentiable Simulation
Aug 28, 2025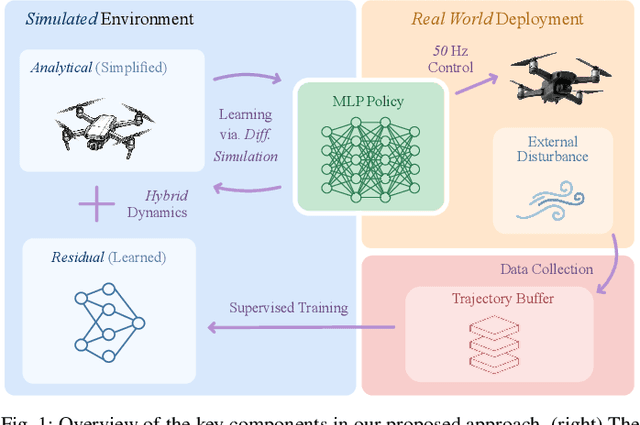

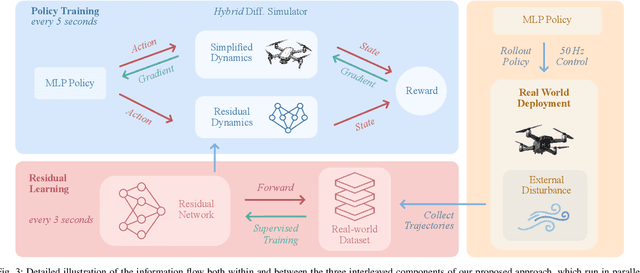
Learning control policies in simulation enables rapid, safe, and cost-effective development of advanced robotic capabilities. However, transferring these policies to the real world remains difficult due to the sim-to-real gap, where unmodeled dynamics and environmental disturbances can degrade policy performance. Existing approaches, such as domain randomization and Real2Sim2Real pipelines, can improve policy robustness, but either struggle under out-of-distribution conditions or require costly offline retraining. In this work, we approach these problems from a different perspective. Instead of relying on diverse training conditions before deployment, we focus on rapidly adapting the learned policy in the real world in an online fashion. To achieve this, we propose a novel online adaptive learning framework that unifies residual dynamics learning with real-time policy adaptation inside a differentiable simulation. Starting from a simple dynamics model, our framework refines the model continuously with real-world data to capture unmodeled effects and disturbances such as payload changes and wind. The refined dynamics model is embedded in a differentiable simulation framework, enabling gradient backpropagation through the dynamics and thus rapid, sample-efficient policy updates beyond the reach of classical RL methods like PPO. All components of our system are designed for rapid adaptation, enabling the policy to adjust to unseen disturbances within 5 seconds of training. We validate the approach on agile quadrotor control under various disturbances in both simulation and the real world. Our framework reduces hovering error by up to 81% compared to L1-MPC and 55% compared to DATT, while also demonstrating robustness in vision-based control without explicit state estimation.
Learning Real-World Acrobatic Flight from Human Preferences
Aug 26, 2025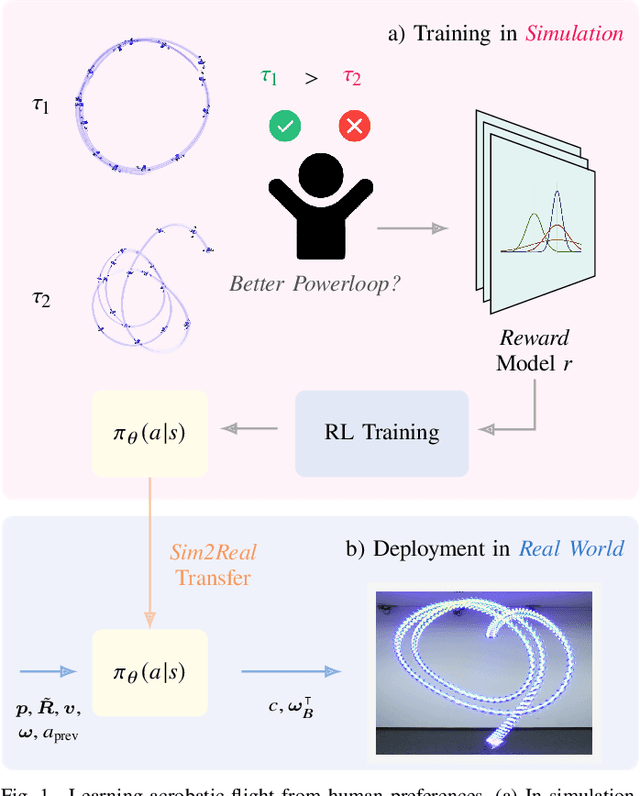
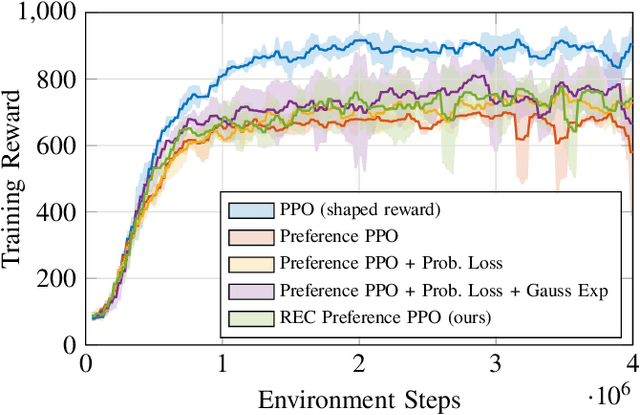


Preference-based reinforcement learning (PbRL) enables agents to learn control policies without requiring manually designed reward functions, making it well-suited for tasks where objectives are difficult to formalize or inherently subjective. Acrobatic flight poses a particularly challenging problem due to its complex dynamics, rapid movements, and the importance of precise execution. In this work, we explore the use of PbRL for agile drone control, focusing on the execution of dynamic maneuvers such as powerloops. Building on Preference-based Proximal Policy Optimization (Preference PPO), we propose Reward Ensemble under Confidence (REC), an extension to the reward learning objective that improves preference modeling and learning stability. Our method achieves 88.4% of the shaped reward performance, compared to 55.2% with standard Preference PPO. We train policies in simulation and successfully transfer them to real-world drones, demonstrating multiple acrobatic maneuvers where human preferences emphasize stylistic qualities of motion. Furthermore, we demonstrate the applicability of our probabilistic reward model in a representative MuJoCo environment for continuous control. Finally, we highlight the limitations of manually designed rewards, observing only 60.7% agreement with human preferences. These results underscore the effectiveness of PbRL in capturing complex, human-centered objectives across both physical and simulated domains.
ForesightNav: Learning Scene Imagination for Efficient Exploration
Apr 22, 2025Understanding how humans leverage prior knowledge to navigate unseen environments while making exploratory decisions is essential for developing autonomous robots with similar abilities. In this work, we propose ForesightNav, a novel exploration strategy inspired by human imagination and reasoning. Our approach equips robotic agents with the capability to predict contextual information, such as occupancy and semantic details, for unexplored regions. These predictions enable the robot to efficiently select meaningful long-term navigation goals, significantly enhancing exploration in unseen environments. We validate our imagination-based approach using the Structured3D dataset, demonstrating accurate occupancy prediction and superior performance in anticipating unseen scene geometry. Our experiments show that the imagination module improves exploration efficiency in unseen environments, achieving a 100% completion rate for PointNav and an SPL of 67% for ObjectNav on the Structured3D Validation split. These contributions demonstrate the power of imagination-driven reasoning for autonomous systems to enhance generalizable and efficient exploration.
Multi-Task Reinforcement Learning for Quadrotors
Dec 17, 2024Reinforcement learning (RL) has shown great effectiveness in quadrotor control, enabling specialized policies to develop even human-champion-level performance in single-task scenarios. However, these specialized policies often struggle with novel tasks, requiring a complete retraining of the policy from scratch. To address this limitation, this paper presents a novel multi-task reinforcement learning (MTRL) framework tailored for quadrotor control, leveraging the shared physical dynamics of the platform to enhance sample efficiency and task performance. By employing a multi-critic architecture and shared task encoders, our framework facilitates knowledge transfer across tasks, enabling a single policy to execute diverse maneuvers, including high-speed stabilization, velocity tracking, and autonomous racing. Our experimental results, validated both in simulation and real-world scenarios, demonstrate that our framework outperforms baseline approaches in terms of sample efficiency and overall task performance.