 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Power Line Inspection with Drones via Perception-Aware MPC
Apr 03, 2023Drones have the potential to revolutionize power line inspection by increasing productivity, reducing inspection time, improving data quality, and eliminating the risks for human operators. Current state-of-the-art systems for power line inspection have two shortcomings: (i) control is decoupled from perception and needs accurate information about the location of the power lines and masts; (ii) collision avoidance is decoupled from the power line tracking, which results in poor tracking in the vicinity of the power masts, and, consequently, in decreased data quality for visual inspection. In this work, we propose a model predictive controller (MPC) that overcomes these limitations by tightly coupling perception and action. Our controller generates commands that maximize the visibility of the power lines while, at the same time, safely avoiding the power masts. For power line detection, we propose a lightweight learning-based detector that is trained only on synthetic data and is able to transfer zero-shot to real-world power line images. We validate our system in simulation and real-world experiments on a mock-up power line infrastructure.
Data-Efficient Collaborative Decentralized Thermal-Inertial Odometry
Sep 14, 2022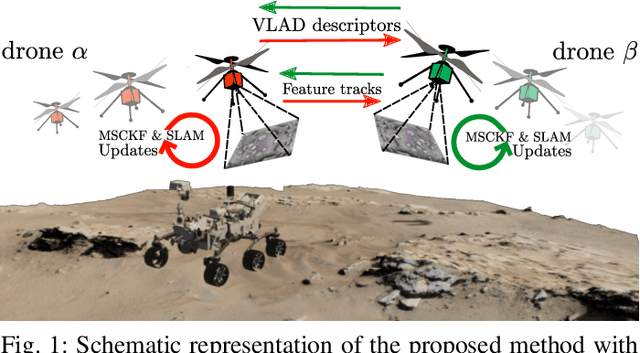
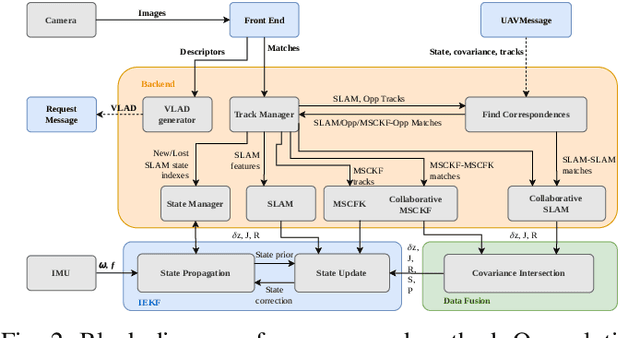
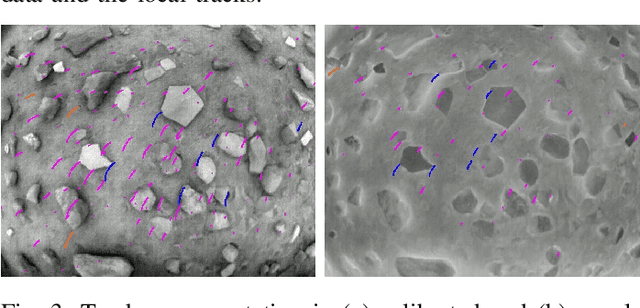
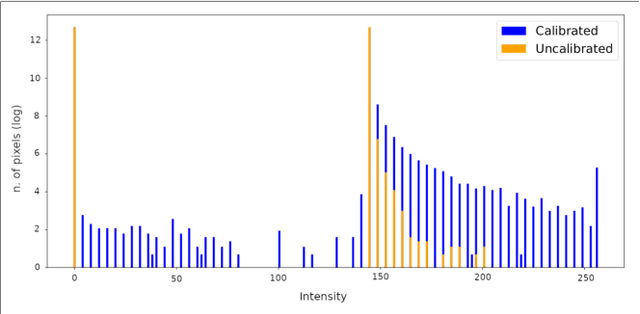
We propose a system solution to achieve data-efficient, decentralized state estimation for a team of flying robots using thermal images and inertial measurements. Each robot can fly independently, and exchange data when possible to refine its state estimate. Our system front-end applies an online photometric calibration to refine the thermal images so as to enhance feature tracking and place recognition. Our system back-end uses a covariance-intersection fusion strategy to neglect the cross-correlation between agents so as to lower memory usage and computational cost. The communication pipeline uses Vector of Locally Aggregated Descriptors (VLAD) to construct a request-response policy that requires low bandwidth usage. We test our collaborative method on both synthetic and real-world data. Our results show that the proposed method improves by up to 46 % trajectory estimation with respect to an individual-agent approach, while reducing up to 89 % the communication exchange. Datasets and code are released to the public, extending the already-public JPL xVIO library.
* 8 pages, 8 figures
Event-aided Direct Sparse Odometry
Apr 24, 2022



We introduce EDS, a direct monocular visual odometry using events and frames. Our algorithm leverages the event generation model to track the camera motion in the blind time between frames. The method formulates a direct probabilistic approach of observed brightness increments. Per-pixel brightness increments are predicted using a sparse number of selected 3D points and are compared to the events via the brightness increment error to estimate camera motion. The method recovers a semi-dense 3D map using photometric bundle adjustment. EDS is the first method to perform 6-DOF VO using events and frames with a direct approach. By design, it overcomes the problem of changing appearance in indirect methods. We also show that, for a target error performance, EDS can work at lower frame rates than state-of-the-art frame-based VO solutions. This opens the door to low-power motion-tracking applications where frames are sparingly triggered "on demand" and our method tracks the motion in between. We release code and datasets to the public.
* 16 pages, 14 Figures, Page: https://rpg.ifi.uzh.ch/eds
Learning Monocular Dense Depth from Events
Oct 22, 2020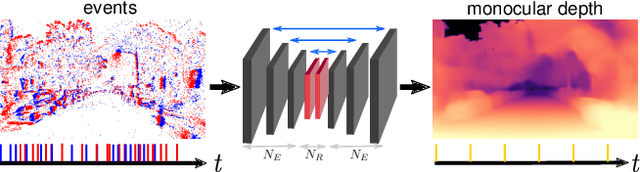


Event cameras are novel sensors that output brightness changes in the form of a stream of asynchronous events instead of intensity frames. Compared to conventional image sensors, they offer significant advantages: high temporal resolution, high dynamic range, no motion blur, and much lower bandwidth. Recently, learning-based approaches have been applied to event-based data, thus unlocking their potential and making significant progress in a variety of tasks, such as monocular depth prediction. Most existing approaches use standard feed-forward architectures to generate network predictions, which do not leverage the temporal consistency presents in the event stream. We propose a recurrent architecture to solve this task and show significant improvement over standard feed-forward methods. In particular, our method generates dense depth predictions using a monocular setup, which has not been shown previously. We pretrain our model using a new dataset containing events and depth maps recorded in the CARLA simulator. We test our method on the Multi Vehicle Stereo Event Camera Dataset (MVSEC). Quantitative experiments show up to 50% improvement in average depth error with respect to previous event-based methods.
Video to Events: Bringing Modern Computer Vision Closer to Event Cameras
Dec 06, 2019



Event cameras are novel sensors that output brightness changes in the form of a stream of asynchronous "events" instead of intensity frames. They offer significant advantages with respect to conventional cameras: high dynamic range (HDR), high temporal resolution, and no motion blur. Recently, novel learning approaches operating on event data have achieved impressive results. Yet, these methods require a large amount of event data for training, which is hardly available due the novelty of event sensors in computer vision research. In this paper, we present a method that addresses these needs by converting any existing video dataset recorded with conventional cameras to synthetic event data. This unlocks the use of a virtually unlimited number of existing video datasets for training networks designed for real event data. We evaluate our method on two relevant vision tasks, i.e., object recognition and semantic segmentation, and show that models trained on synthetic events have several benefits: (i) they generalize well to real event data, even in scenarios where standard-camera images are blurry or overexposed, by inheriting the outstanding properties of event cameras; (ii) they can be used for fine-tuning on real data to improve over state-of-the-art for both classification and semantic segmentation.