 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Based Agile Landing on Turbulent Waters
May 22, 2026Autonomous landing of Unmanned Aerial Vehicles on maritime vessels is challenging due to the coupled motion of the vehicle and landing platform in open-sea conditions. This paper presents a reinforcement-learning-based approach for autonomous multirotor landing on moving maritime platforms without requiring explicit platform-state information. The proposed method uses multirotor state measurements together with local visual features, consisting of keypoints and associated descriptors extracted from the landing surface, to predict attitude and thrust commands. These commands are tracked by a conventional low-level controller. The policy is trained in simulation using synthetic keypoints with randomly generated normalized descriptors, enabling zero-shot deployment with different local feature extractors onboard the UAV. We evaluate the method in a realistic simulator and show that it outperforms a state-of-the-art Model Predictive Control baseline under platform motions corresponding to ``Very Rough'' sea conditions. Finally, we perform extensive real-world experiments, demonstrating autonomous onboard landing using two different local feature extractors. To the best of our knowledge, this is the first approach for agile multirotor landing on maritime platforms in turbulent waters that does not rely on an explicit platform-state representation.
Superhuman Safe and Agile Racing through Multi-Agent Reinforcement Learning
May 21, 2026Autonomous systems have achieved superhuman performance in isolation or simulation, yet they remain brittle in shared, dynamic real-world spaces. This failure stems from the dominant single-agent paradigm for physical applications, where other actors are ignored or treated as environmental noise, preventing effective coordination. Here we show that multi-agent reinforcement learning provides the essential safety scaffolding required for real-world interaction. Using high-speed quadrotor racing as a high-stakes testbed, we train agents to navigate complex aerodynamic interactions and strategic maneuvering with a variable number of racers. Through league-based self-play, agents evolve sophisticated anticipatory behaviors, including proactive collision avoidance, overtaking, and handling multi-agent physical interactions, including aerodynamic downwash. Our agents outperform a champion-level human pilot in multi-player races at speeds exceeding 22 m/s, while simultaneously reducing collision rates by 50 % compared to state-of-the-art single-agent baselines. Crucially, training with diverse artificial agents enables zero-shot generalization to safer human interaction. These results suggest that the path to robust robotic co-existence lies not in isolated safety constraints, but in the rigorous demands of multi-agent interaction. Multimedia materials are available at: https://rpg.ifi.uzh.ch/marl
Image-Conditioned Adaptive Parameter Tuning for Visual Odometry Frontends
Mar 23, 2026Resource-constrained autonomous robots rely on sparse direct and semi-direct visual-(inertial)-odometry (VO) pipelines, as they provide a favorable tradeoff between accuracy, robustness, and computational cost. However, the performance of most systems depends critically on hand-tuned hyperparameters governing feature detection, tracking, and outlier rejection. These parameters are typically fixed during deployment, even though their optimal values vary with scene characteristics such as texture density, illumination, motion blur, and sensor noise, leading to brittle performance in real-world environments. We propose the first image-conditioned reinforcement learning framework for online tuning of VO frontend parameters, effectively embedding the expert into the system. Our key idea is to formulate the frontend configuration as a sequential decision-making problem and learn a policy that directly maps visual input to feature detection and tracking parameters. The policy uses a lightweight texture-aware CNN encoder and a privileged critic during training. Unlike prior RL-based approaches that rely solely on internal VO statistics, our method observes the image content and proactively adapts parameters before tracking degrades. Experiments on TartanAirV2 and TUM RGB-D show 3x longer feature tracks and 3x lower computational cost, despite training entirely in simulation.
EAAE: Energy-Aware Autonomous Exploration for UAVs in Unknown 3D Environments
Mar 16, 2026Battery-powered multirotor unmanned aerial vehicles (UAVs) can rapidly map unknown environments, but mission performance is often limited by energy rather than geometry alone. Standard exploration policies that optimise for coverage or time can therefore waste energy through manoeuvre-heavy trajectories. In this paper, we address energy-aware autonomous 3D exploration for multirotor UAVs in initially unknown environments. We propose Energy-Aware Autonomous Exploration (EAAE), a modular frontier-based framework that makes energy an explicit decision variable during frontier selection. EAAE clusters frontiers into view-consistent regions, plans dynamically feasible candidate trajectories to the most informative clusters, and predicts their execution energy using an offline power estimation loop. The next target is then selected by minimising predicted trajectory energy while preserving exploration progress through a dual-layer planning architecture for safe execution. We evaluate EAAE in a full exploration pipeline with a rotor-speed-based power model across simulated 3D environments of increasing complexity. Compared to representative distance-based and information gain-based frontier baselines, EAAE consistently reduces total energy consumption while maintaining competitive exploration time and comparable map quality, providing a practical drop-in energy-aware layer for frontier exploration.
Approximate Imitation Learning for Event-based Quadrotor Flight in Cluttered Environments
Mar 08, 2026Event cameras offer high temporal resolution and low latency, making them ideal sensors for high-speed robotic applications where conventional cameras suffer from image degradations such as motion blur. In addition, their low power consumption can enhance endurance, which is critical for resource-constrained platforms. Motivated by these properties, we present a novel approach that enables a quadrotor to fly through cluttered environments at high speed by perceiving the environment with a single event camera. Our proposed method employs an end-to-end neural network trained to map event data directly to control commands, eliminating the reliance on standard cameras. To enable efficient training in simulation, where rendering synthetic event data is computationally expensive, we propose Approximate Imitation Learning, a novel imitation learning framework. Our approach leverages a large-scale offline dataset to learn a task-specific representation space. Subsequently, the policy is trained through online interactions that rely solely on lightweight, simulated state information, eliminating the need to render events during training. This enables the efficient training of event-based control policies for fast quadrotor flight, highlighting the potential of our framework for other modalities where data simulation is costly or impractical. Our approach outperforms standard imitation learning baselines in simulation and demonstrates robust performance in real-world flight tests, achieving speeds up to 9.8 ms-1 in cluttered environments.
Unifying Quadrotor Motion Planning and Control by Chaining Different Fidelity Models
Dec 13, 2025Many aerial tasks involving quadrotors demand both instant reactivity and long-horizon planning. High-fidelity models enable accurate control but are too slow for long horizons; low-fidelity planners scale but degrade closed-loop performance. We present Unique, a unified MPC that cascades models of different fidelity within a single optimization: a short-horizon, high-fidelity model for accurate control, and a long-horizon, low-fidelity model for planning. We align costs across horizons, derive feasibility-preserving thrust and body-rate constraints for the point-mass model, and introduce transition constraints that match the different states, thrust-induced acceleration, and jerk-body-rate relations. To prevent local minima emerging from nonsmooth clutter, we propose a 3D progressive smoothing schedule that morphs norm-based obstacles along the horizon. In addition, we deploy parallel randomly initialized MPC solvers to discover lower-cost local minima on the long, low-fidelity horizon. In simulation and real flights, under equal computational budgets, Unique improves closed-loop position or velocity tracking by up to 75% compared with standard MPC and hierarchical planner-tracker baselines. Ablations and Pareto analyses confirm robust gains across horizon variations, constraint approximations, and smoothing schedules.
HDVIO2.0: Wind and Disturbance Estimation with Hybrid Dynamics VIO
Apr 01, 2025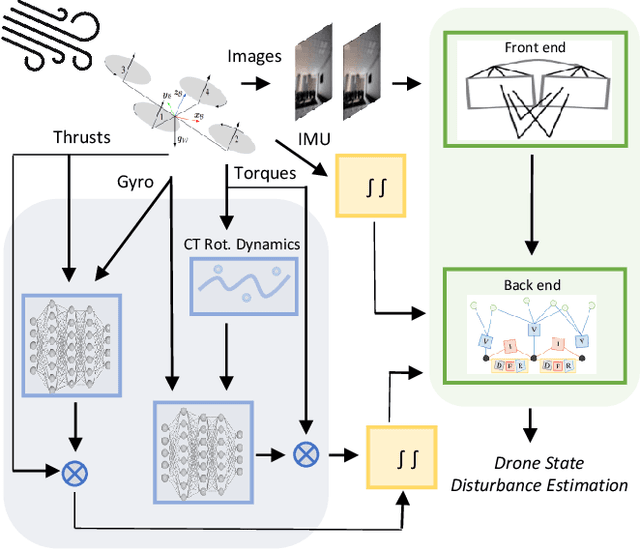
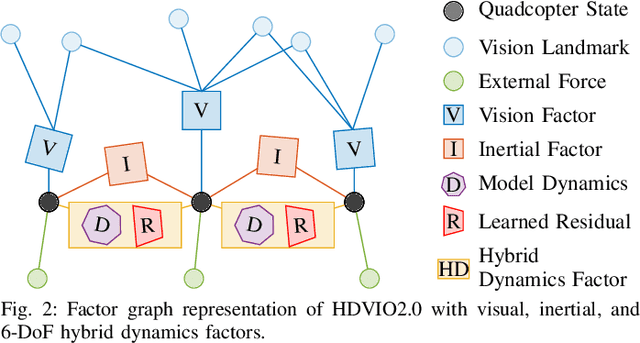
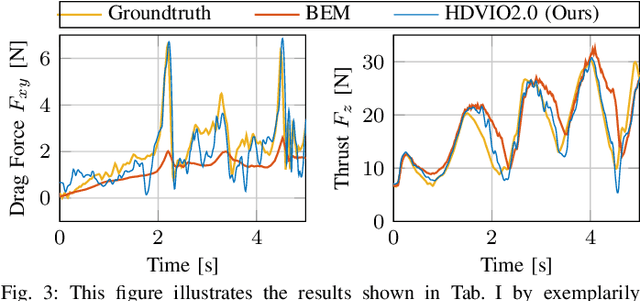

Visual-inertial odometry (VIO) is widely used for state estimation in autonomous micro aerial vehicles using onboard sensors. Current methods improve VIO by incorporating a model of the translational vehicle dynamics, yet their performance degrades when faced with low-accuracy vehicle models or continuous external disturbances, like wind. Additionally, incorporating rotational dynamics in these models is computationally intractable when they are deployed in online applications, e.g., in a closed-loop control system. We present HDVIO2.0, which models full 6-DoF, translational and rotational, vehicle dynamics and tightly incorporates them into a VIO with minimal impact on the runtime. HDVIO2.0 builds upon the previous work, HDVIO, and addresses these challenges through a hybrid dynamics model combining a point-mass vehicle model with a learning-based component, with access to control commands and IMU history, to capture complex aerodynamic effects. The key idea behind modeling the rotational dynamics is to represent them with continuous-time functions. HDVIO2.0 leverages the divergence between the actual motion and the predicted motion from the hybrid dynamics model to estimate external forces as well as the robot state. Our system surpasses the performance of state-of-the-art methods in experiments using public and new drone dynamics datasets, as well as real-world flights in winds up to 25 km/h. Unlike existing approaches, we also show that accurate vehicle dynamics predictions are achievable without precise knowledge of the full vehicle state.
A Monocular Event-Camera Motion Capture System
Feb 17, 2025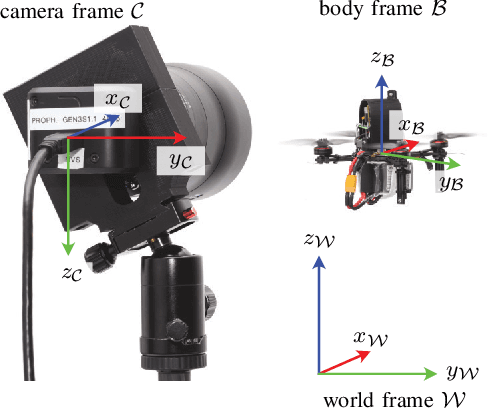
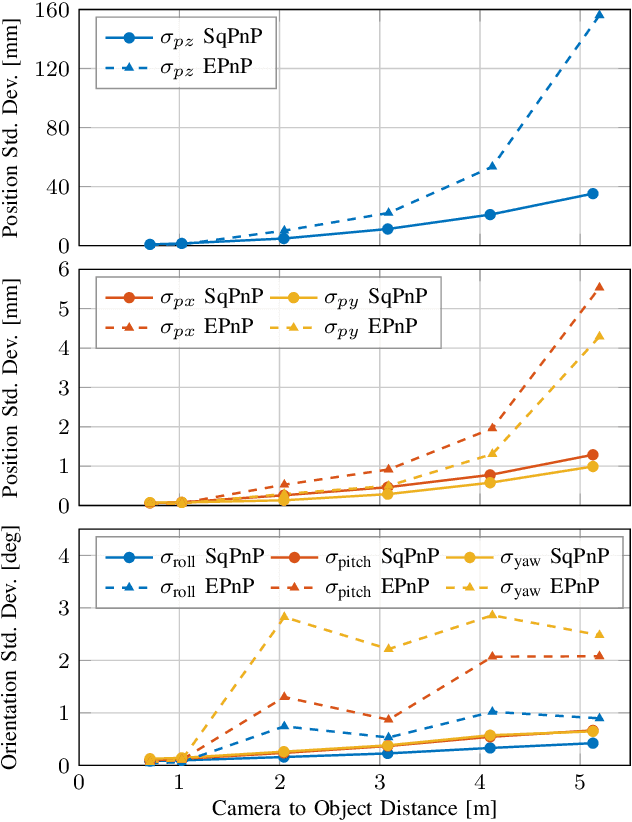
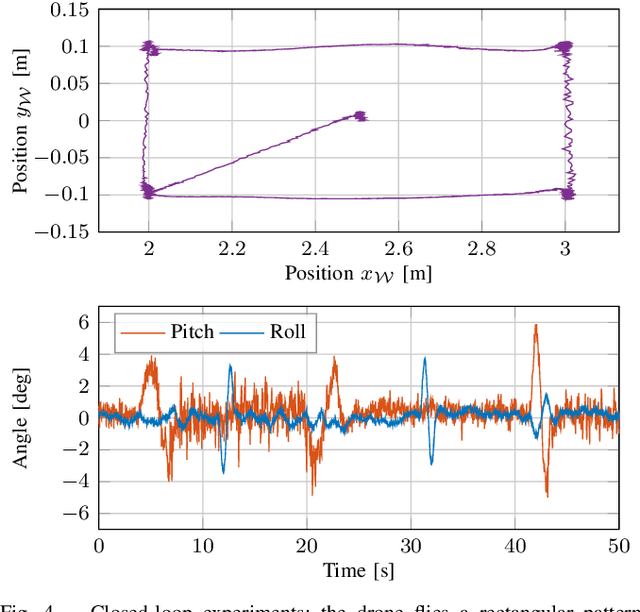
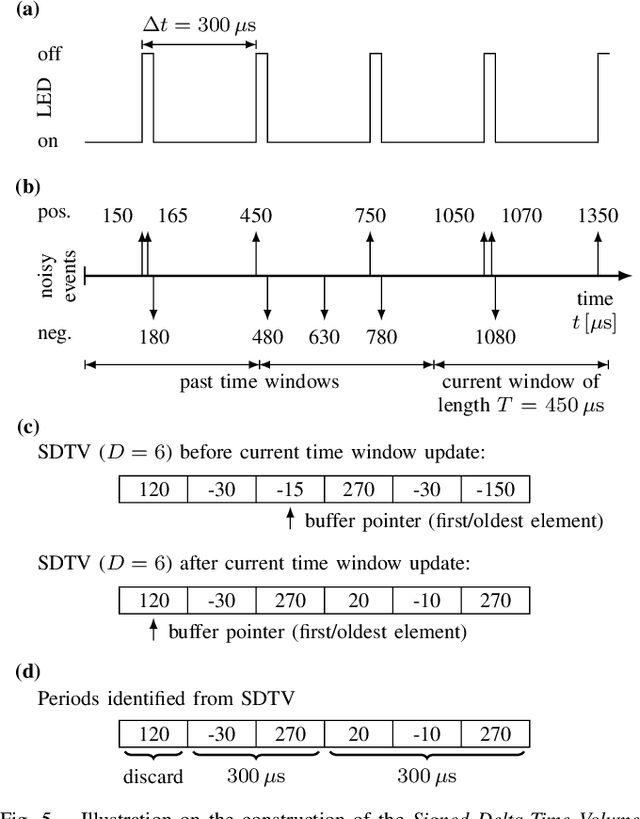
Motion capture systems are a widespread tool in research to record ground-truth poses of objects. Commercial systems use reflective markers attached to the object and then triangulate pose of the object from multiple camera views. Consequently, the object must be visible to multiple cameras which makes such multi-view motion capture systems unsuited for deployments in narrow, confined spaces (e.g. ballast tanks of ships). In this technical report we describe a monocular event-camera motion capture system which overcomes this limitation and is ideally suited for narrow spaces. Instead of passive markers it relies on active, blinking LED markers such that each marker can be uniquely identified from the blinking frequency. The markers are placed at known locations on the tracking object. We then solve the PnP (perspective-n-points) problem to obtain the position and orientation of the object. The developed system has millimeter accuracy, millisecond latency and we demonstrate that its state estimate can be used to fly a small, agile quadrotor.
Drift-free Visual SLAM using Digital Twins
Dec 12, 2024



Globally-consistent localization in urban environments is crucial for autonomous systems such as self-driving vehicles and drones, as well as assistive technologies for visually impaired people. Traditional Visual-Inertial Odometry (VIO) and Visual Simultaneous Localization and Mapping (VSLAM) methods, though adequate for local pose estimation, suffer from drift in the long term due to reliance on local sensor data. While GPS counteracts this drift, it is unavailable indoors and often unreliable in urban areas. An alternative is to localize the camera to an existing 3D map using visual-feature matching. This can provide centimeter-level accurate localization but is limited by the visual similarities between the current view and the map. This paper introduces a novel approach that achieves accurate and globally-consistent localization by aligning the sparse 3D point cloud generated by the VIO/VSLAM system to a digital twin using point-to-plane matching; no visual data association is needed. The proposed method provides a 6-DoF global measurement tightly integrated into the VIO/VSLAM system. Experiments run on a high-fidelity GPS simulator and real-world data collected from a drone demonstrate that our approach outperforms state-of-the-art VIO-GPS systems and offers superior robustness against viewpoint changes compared to the state-of-the-art Visual SLAM systems.
Demonstrating Agile Flight from Pixels without State Estimation
Jun 18, 2024


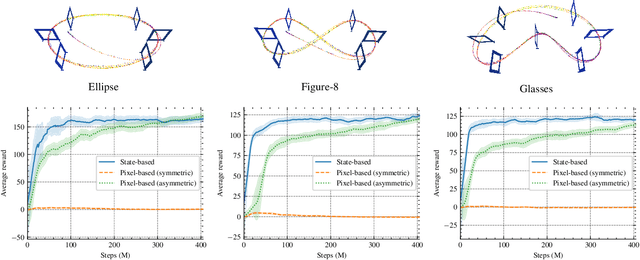
Quadrotors are among the most agile flying robots. Despite recent advances in learning-based control and computer vision, autonomous drones still rely on explicit state estimation. On the other hand, human pilots only rely on a first-person-view video stream from the drone onboard camera to push the platform to its limits and fly robustly in unseen environments. To the best of our knowledge, we present the first vision-based quadrotor system that autonomously navigates through a sequence of gates at high speeds while directly mapping pixels to control commands. Like professional drone-racing pilots, our system does not use explicit state estimation and leverages the same control commands humans use (collective thrust and body rates). We demonstrate agile flight at speeds up to 40km/h with accelerations up to 2g. This is achieved by training vision-based policies with reinforcement learning (RL). The training is facilitated using an asymmetric actor-critic with access to privileged information. To overcome the computational complexity during image-based RL training, we use the inner edges of the gates as a sensor abstraction. This simple yet robust, task-relevant representation can be simulated during training without rendering images. During deployment, a Swin-transformer-based gate detector is used. Our approach enables autonomous agile flight with standard, off-the-shelf hardware. Although our demonstration focuses on drone racing, we believe that our method has an impact beyond drone racing and can serve as a foundation for future research into real-world applications in structured environments.