 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgilicious: Open-Source and Open-Hardware Agile Quadrotor for Vision-Based Flight
Jul 12, 2023Autonomous, agile quadrotor flight raises fundamental challenges for robotics research in terms of perception, planning, learning, and control. A versatile and standardized platform is needed to accelerate research and let practitioners focus on the core problems. To this end, we present Agilicious, a co-designed hardware and software framework tailored to autonomous, agile quadrotor flight. It is completely open-source and open-hardware and supports both model-based and neural-network--based controllers. Also, it provides high thrust-to-weight and torque-to-inertia ratios for agility, onboard vision sensors, GPU-accelerated compute hardware for real-time perception and neural-network inference, a real-time flight controller, and a versatile software stack. In contrast to existing frameworks, Agilicious offers a unique combination of flexible software stack and high-performance hardware. We compare Agilicious with prior works and demonstrate it on different agile tasks, using both model-based and neural-network--based controllers. Our demonstrators include trajectory tracking at up to 5g and 70 km/h in a motion-capture system, and vision-based acrobatic flight and obstacle avoidance in both structured and unstructured environments using solely onboard perception. Finally, we demonstrate its use for hardware-in-the-loop simulation in virtual-reality environments. Thanks to its versatility, we believe that Agilicious supports the next generation of scientific and industrial quadrotor research.
* 14 pages, 5 figures, 2 tables
Learning Agile, Vision-based Drone Flight: from Simulation to Reality
Apr 09, 2023We present our latest research in learning deep sensorimotor policies for agile, vision-based quadrotor flight. We show methodologies for the successful transfer of such policies from simulation to the real world. In addition, we discuss the open research questions that still need to be answered to improve the agility and robustness of autonomous drones toward human-pilot performance.
Autonomous Drone Racing: A Survey
Jan 05, 2023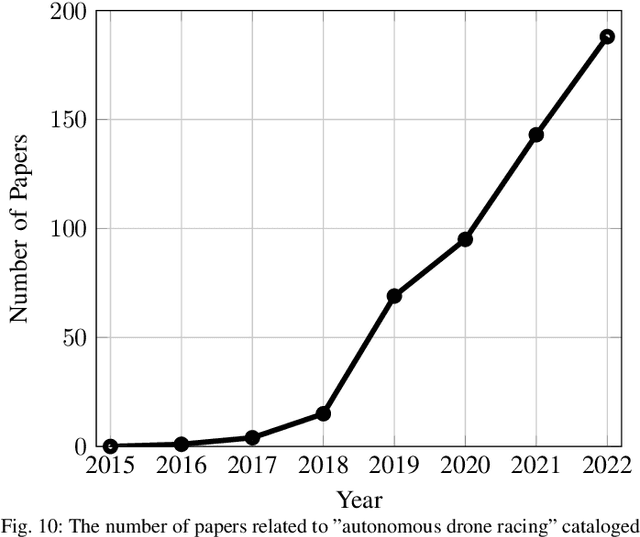


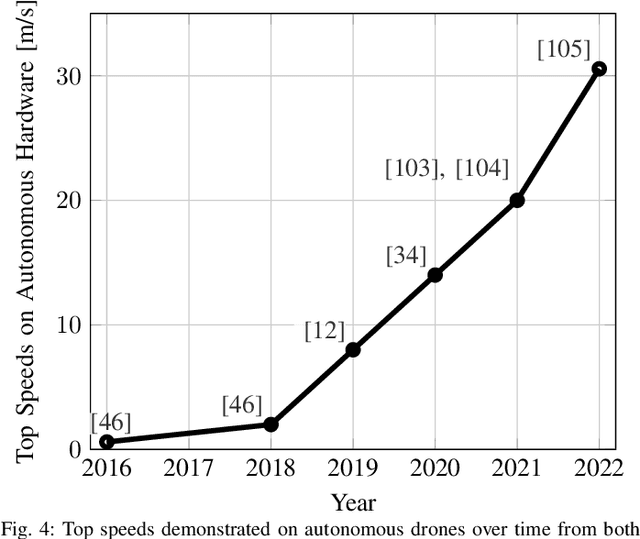
Over the last decade, the use of autonomous drone systems for surveying, search and rescue, or last-mile delivery has increased exponentially. With the rise of these applications comes the need for highly robust, safety-critical algorithms which can operate drones in complex and uncertain environments. Additionally, flying fast enables drones to cover more ground which in turn increases productivity and further strengthens their use case. One proxy for developing algorithms used in high-speed navigation is the task of autonomous drone racing, where researchers program drones to fly through a sequence of gates and avoid obstacles as quickly as possible using onboard sensors and limited computational power. Speeds and accelerations exceed over 80 kph and 4 g respectively, raising significant challenges across perception, planning, control, and state estimation. To achieve maximum performance, systems require real-time algorithms that are robust to motion blur, high dynamic range, model uncertainties, aerodynamic disturbances, and often unpredictable opponents. This survey covers the progression of autonomous drone racing across model-based and learning-based approaches. We provide an overview of the field, its evolution over the years, and conclude with the biggest challenges and open questions to be faced in the future.
User-Conditioned Neural Control Policies for Mobile Robotics
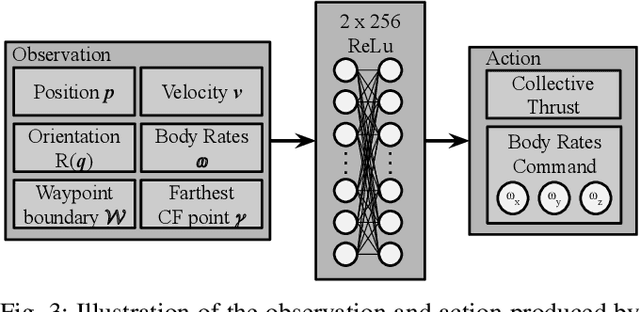
Dec 15, 2022Recently, learning-based controllers have been shown to push mobile robotic systems to their limits and provide the robustness needed for many real-world applications. However, only classical optimization-based control frameworks offer the inherent flexibility to be dynamically adjusted during execution by, for example, setting target speeds or actuator limits. We present a framework to overcome this shortcoming of neural controllers by conditioning them on an auxiliary input. This advance is enabled by including a feature-wise linear modulation layer (FiLM). We use model-free reinforcement-learning to train quadrotor control policies for the task of navigating through a sequence of waypoints in minimum time. By conditioning the policy on the maximum available thrust or the viewing direction relative to the next waypoint, a user can regulate the aggressiveness of the quadrotor's flight during deployment. We demonstrate in simulation and in real-world experiments that a single control policy can achieve close to time-optimal flight performance across the entire performance envelope of the robot, reaching up to 60 km/h and 4.5g in acceleration. The ability to guide a learned controller during task execution has implications beyond agile quadrotor flight, as conditioning the control policy on human intent helps safely bringing learning based systems out of the well-defined laboratory environment into the wild.
Learned Inertial Odometry for Autonomous Drone Racing
Oct 27, 2022Inertial odometry is an attractive solution to the problem of state estimation for agile quadrotor flight. It is inexpensive, lightweight, and it is not affected by perceptual degradation. However, only relying on the integration of the inertial measurements for state estimation is infeasible. The errors and time-varying biases present in such measurements cause the accumulation of large drift in the pose estimates. Recently, inertial odometry has made significant progress in estimating the motion of pedestrians. State-of-the-art algorithms rely on learning a motion prior that is typical of humans but cannot be transferred to drones. In this work, we propose a learning-based odometry algorithm that uses an inertial measurement unit (IMU) as the only sensor modality for autonomous drone racing tasks. The core idea of our system is to couple a model-based filter, driven by the inertial measurements, with a learning-based module that has access to the control commands. We show that our inertial odometry algorithm is superior to the state-of-the-art filter-based and optimization-based visual- inertial odometry as well as the state-of-the-art learned-inertial odometry. Additionally, we show that our system is comparable to a visual-inertial odometry solution that uses a camera and exploits the known gate location and appearance. We believe that the application in autonomous drone racing paves the way for novel research in inertial odometry for agile quadrotor flight. We will release the code upon acceptance.
Learning Minimum-Time Flight in Cluttered Environments
Mar 28, 2022
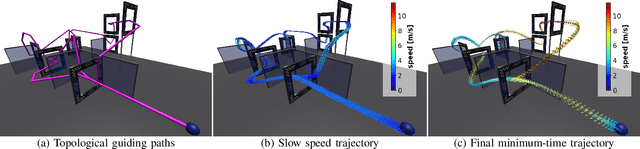
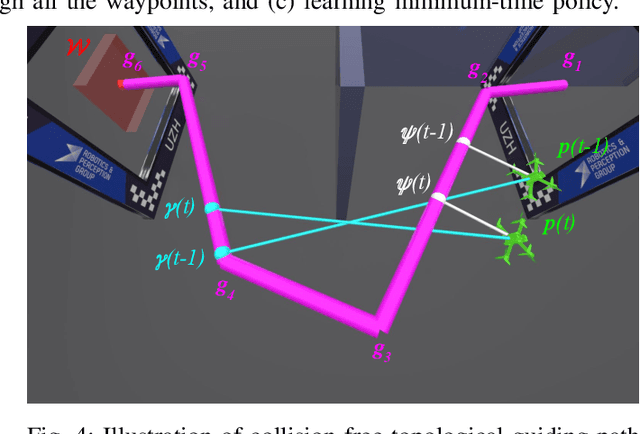
We tackle the problem of minimum-time flight for a quadrotor through a sequence of waypoints in the presence of obstacles while exploiting the full quadrotor dynamics. Early works relied on simplified dynamics or polynomial trajectory representations that did not exploit the full actuator potential of the quadrotor, and, thus, resulted in suboptimal solutions. Recent works can plan minimum-time trajectories; yet, the trajectories are executed with control methods that do not account for obstacles. Thus, a successful execution of such trajectories is prone to errors due to model mismatch and in-flight disturbances. To this end, we leverage deep reinforcement learning and classical topological path planning to train robust neural-network controllers for minimum-time quadrotor flight in cluttered environments. The resulting neural network controller demonstrates significantly better performance of up to 19% over state-of-the-art methods. More importantly, the learned policy solves the planning and control problem simultaneously online to account for disturbances, thus achieving much higher robustness. As such, the presented method achieves 100% success rate of flying minimum-time policies without collision, while traditional planning and control approaches achieve only 40%. The proposed method is validated in both simulation and the real world.
Neural-MPC: Deep Learning Model Predictive Control for Quadrotors and Agile Robotic Platforms
Mar 15, 2022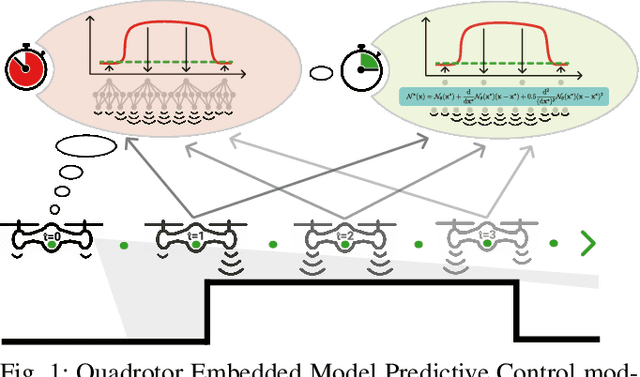
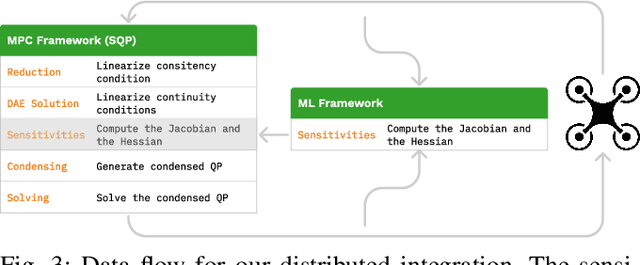
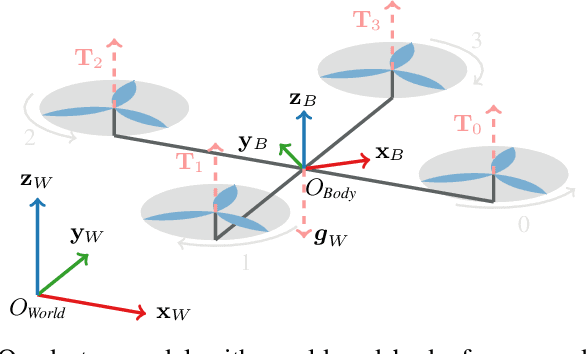
Model Predictive Control (MPC) has become a popular framework in embedded control for high-performance autonomous systems. However, to achieve good control performance using MPC, an accurate dynamics model is key. To maintain real-time operation, the dynamics models used on embedded systems have been limited to simple first-principle models, which substantially limits their representative power. In contrast, neural networks can model complex effects purely from data. In contrast to such simple models, machine learning approaches such as neural networks have been shown to accurately model even complex dynamic effects, but their large computational complexity hindered combination with fast real-time iteration loops. With this work, we present Neural-MPC, a framework to efficiently integrate large, complex neural network architectures as dynamics models within a model-predictive control pipeline. Our experiments, performed in simulation and the real world on a highly agile quadrotor platform, demonstrate up to 83% reduction in positional tracking error when compared to state-of-the-art MPC approaches without neural network dynamics.
A Benchmark Comparison of Learned Control Policies for Agile Quadrotor Flight
Feb 22, 2022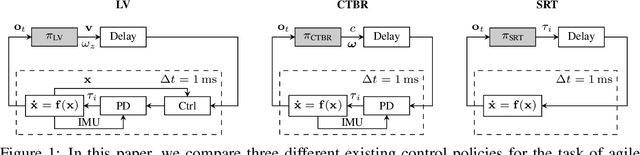
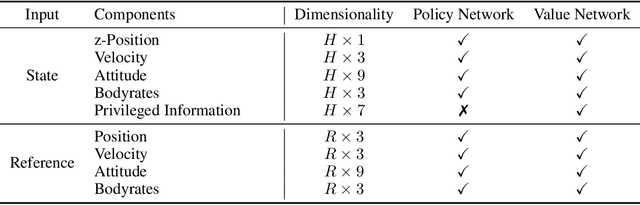

Quadrotors are highly nonlinear dynamical systems that require carefully tuned controllers to be pushed to their physical limits. Recently, learning-based control policies have been proposed for quadrotors, as they would potentially allow learning direct mappings from high-dimensional raw sensory observations to actions. Due to sample inefficiency, training such learned controllers on the real platform is impractical or even impossible. Training in simulation is attractive but requires to transfer policies between domains, which demands trained policies to be robust to such domain gap. In this work, we make two contributions: (i) we perform the first benchmark comparison of existing learned control policies for agile quadrotor flight and show that training a control policy that commands body-rates and thrust results in more robust sim-to-real transfer compared to a policy that directly specifies individual rotor thrusts, (ii) we demonstrate for the first time that such a control policy trained via deep reinforcement learning can control a quadrotor in real-world experiments at speeds over 45km/h.
* 6 pages (+1 references)
Learning High-Speed Flight in the Wild
Oct 11, 2021Quadrotors are agile. Unlike most other machines, they can traverse extremely complex environments at high speeds. To date, only expert human pilots have been able to fully exploit their capabilities. Autonomous operation with on-board sensing and computation has been limited to low speeds. State-of-the-art methods generally separate the navigation problem into subtasks: sensing, mapping, and planning. While this approach has proven successful at low speeds, the separation it builds upon can be problematic for high-speed navigation in cluttered environments. Indeed, the subtasks are executed sequentially, leading to increased processing latency and a compounding of errors through the pipeline. Here we propose an end-to-end approach that can autonomously fly quadrotors through complex natural and man-made environments at high speeds, with purely onboard sensing and computation. The key principle is to directly map noisy sensory observations to collision-free trajectories in a receding-horizon fashion. This direct mapping drastically reduces processing latency and increases robustness to noisy and incomplete perception. The sensorimotor mapping is performed by a convolutional network that is trained exclusively in simulation via privileged learning: imitating an expert with access to privileged information. By simulating realistic sensor noise, our approach achieves zero-shot transfer from simulation to challenging real-world environments that were never experienced during training: dense forests, snow-covered terrain, derailed trains, and collapsed buildings. Our work demonstrates that end-to-end policies trained in simulation enable high-speed autonomous flight through challenging environments, outperforming traditional obstacle avoidance pipelines.
* 16 pages (+7 supplementary)
Performance, Precision, and Payloads: Adaptive Nonlinear MPC for Quadrotors
Sep 09, 2021
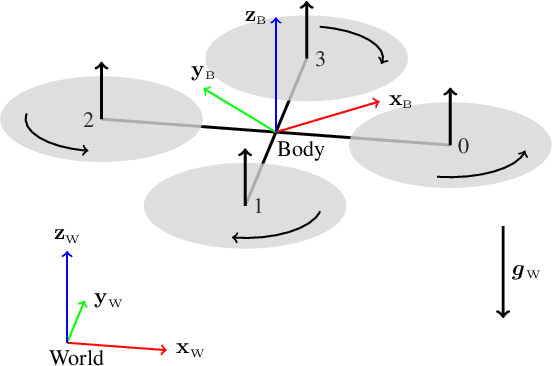
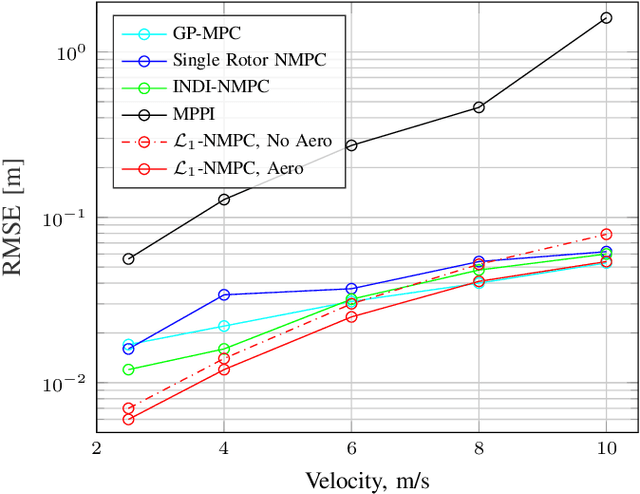
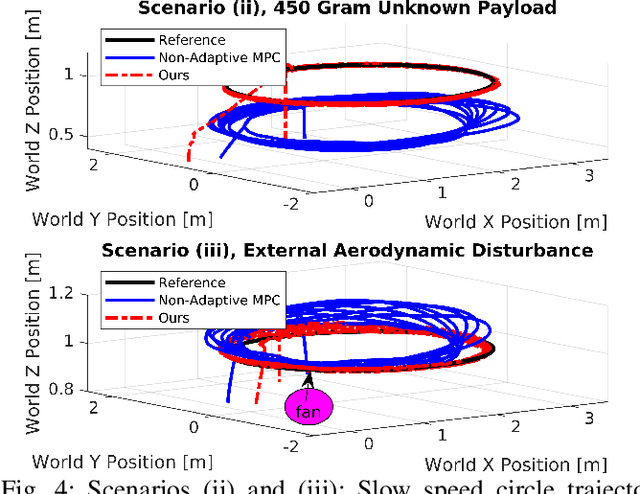
Agile quadrotor flight in challenging environments has the potential to revolutionize shipping, transportation, and search and rescue applications. Nonlinear model predictive control (NMPC) has recently shown promising results for agile quadrotor control, but relies on highly accurate models for maximum performance. Hence, model uncertainties in the form of unmodeled complex aerodynamic effects, varying payloads and parameter mismatch will degrade overall system performance. In this paper, we propose L1-NMPC, a novel hybrid adaptive NMPC to learn model uncertainties online and immediately compensate for them, drastically improving performance over the non-adaptive baseline with minimal computational overhead. Our proposed architecture generalizes to many different environments from which we evaluate wind, unknown payloads, and highly agile flight conditions. The proposed method demonstrates immense flexibility and robustness, with more than 90% tracking error reduction over non-adaptive NMPC under large unknown disturbances and without any gain tuning. In addition, the same controller with identical gains can accurately fly highly agile racing trajectories exhibiting top speeds of 70 km/h, offering tracking performance improvements of around 50% relative to the non-adaptive NMPC baseline. We will release our code fully open-sourced upon acceptance.