 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Visual-Inertial Depth Estimation
Mar 21, 2023



We present a visual-inertial depth estimation pipeline that integrates monocular depth estimation and visual-inertial odometry to produce dense depth estimates with metric scale. Our approach performs global scale and shift alignment against sparse metric depth, followed by learning-based dense alignment. We evaluate on the TartanAir and VOID datasets, observing up to 30% reduction in inverse RMSE with dense scale alignment relative to performing just global alignment alone. Our approach is especially competitive at low density; with just 150 sparse metric depth points, our dense-to-dense depth alignment method achieves over 50% lower iRMSE over sparse-to-dense depth completion by KBNet, currently the state of the art on VOID. We demonstrate successful zero-shot transfer from synthetic TartanAir to real-world VOID data and perform generalization tests on NYUv2 and VCU-RVI. Our approach is modular and is compatible with a variety of monocular depth estimation models. Video: https://youtu.be/IMwiKwSpshQ Code: https://github.com/isl-org/VI-Depth
Unsupervised Contrastive Domain Adaptation for Semantic Segmentation
Apr 18, 2022

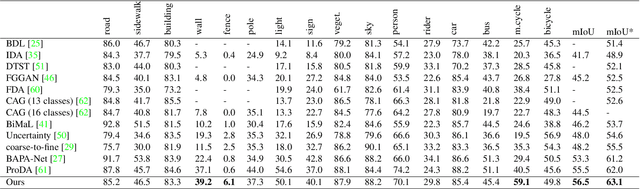
Semantic segmentation models struggle to generalize in the presence of domain shift. In this paper, we introduce contrastive learning for feature alignment in cross-domain adaptation. We assemble both in-domain contrastive pairs and cross-domain contrastive pairs to learn discriminative features that align across domains. Based on the resulting well-aligned feature representations we introduce a label expansion approach that is able to discover samples from hard classes during the adaptation process to further boost performance. The proposed approach consistently outperforms state-of-the-art methods for domain adaptation. It achieves 60.2% mIoU on the Cityscapes dataset when training on the synthetic GTA5 dataset together with unlabeled Cityscapes images.
Language-driven Semantic Segmentation
Jan 10, 2022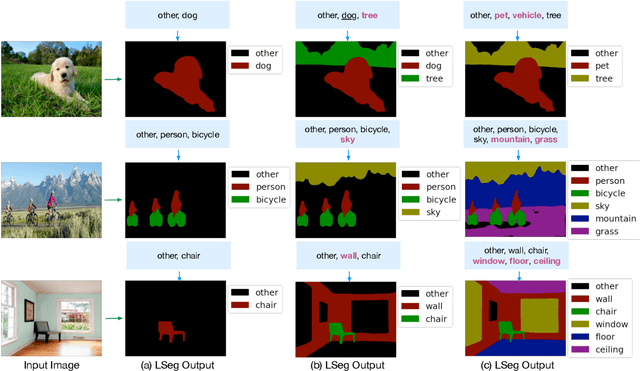
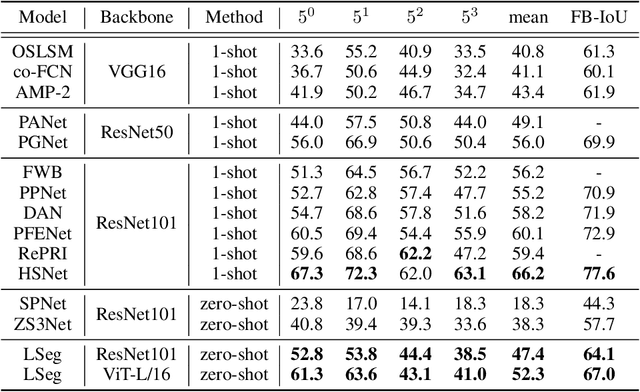
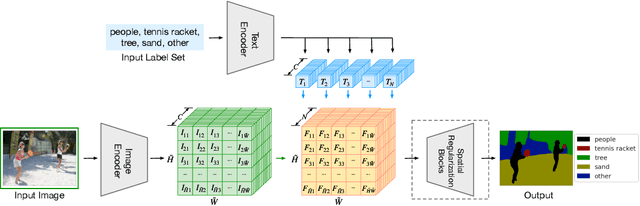
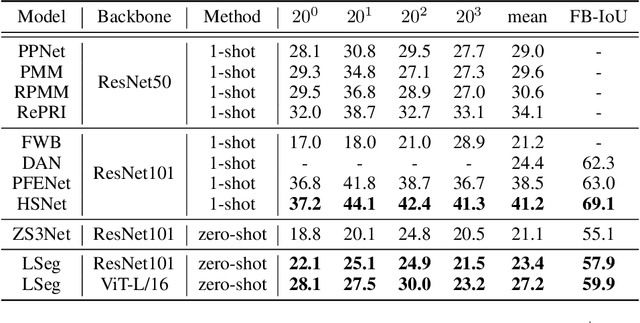
We present LSeg, a novel model for language-driven semantic image segmentation. LSeg uses a text encoder to compute embeddings of descriptive input labels (e.g., "grass" or "building") together with a transformer-based image encoder that computes dense per-pixel embeddings of the input image. The image encoder is trained with a contrastive objective to align pixel embeddings to the text embedding of the corresponding semantic class. The text embeddings provide a flexible label representation in which semantically similar labels map to similar regions in the embedding space (e.g., "cat" and "furry"). This allows LSeg to generalize to previously unseen categories at test time, without retraining or even requiring a single additional training sample. We demonstrate that our approach achieves highly competitive zero-shot performance compared to existing zero- and few-shot semantic segmentation methods, and even matches the accuracy of traditional segmentation algorithms when a fixed label set is provided. Code and demo are available at https://github.com/isl-org/lang-seg.
Learning High-Speed Flight in the Wild
Oct 11, 2021Quadrotors are agile. Unlike most other machines, they can traverse extremely complex environments at high speeds. To date, only expert human pilots have been able to fully exploit their capabilities. Autonomous operation with on-board sensing and computation has been limited to low speeds. State-of-the-art methods generally separate the navigation problem into subtasks: sensing, mapping, and planning. While this approach has proven successful at low speeds, the separation it builds upon can be problematic for high-speed navigation in cluttered environments. Indeed, the subtasks are executed sequentially, leading to increased processing latency and a compounding of errors through the pipeline. Here we propose an end-to-end approach that can autonomously fly quadrotors through complex natural and man-made environments at high speeds, with purely onboard sensing and computation. The key principle is to directly map noisy sensory observations to collision-free trajectories in a receding-horizon fashion. This direct mapping drastically reduces processing latency and increases robustness to noisy and incomplete perception. The sensorimotor mapping is performed by a convolutional network that is trained exclusively in simulation via privileged learning: imitating an expert with access to privileged information. By simulating realistic sensor noise, our approach achieves zero-shot transfer from simulation to challenging real-world environments that were never experienced during training: dense forests, snow-covered terrain, derailed trains, and collapsed buildings. Our work demonstrates that end-to-end policies trained in simulation enable high-speed autonomous flight through challenging environments, outperforming traditional obstacle avoidance pipelines.
* 16 pages (+7 supplementary)
An Analysis of Super-Net Heuristics in Weight-Sharing NAS
Oct 04, 2021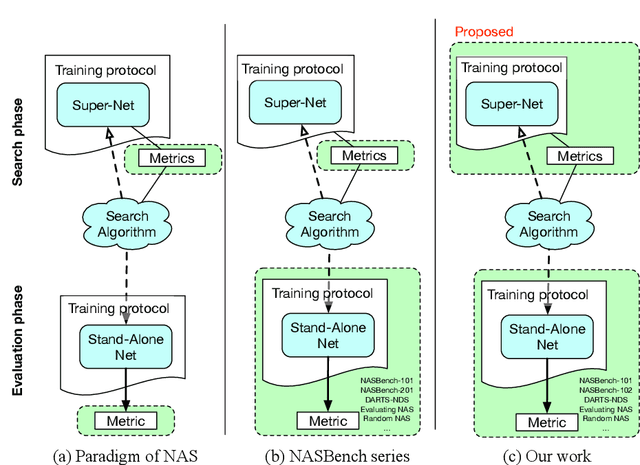
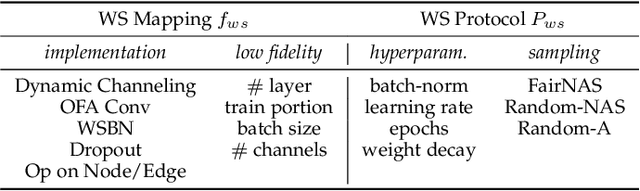
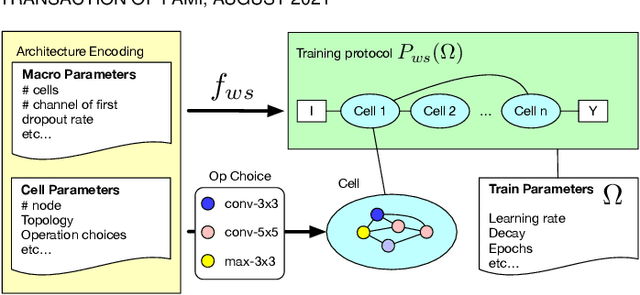
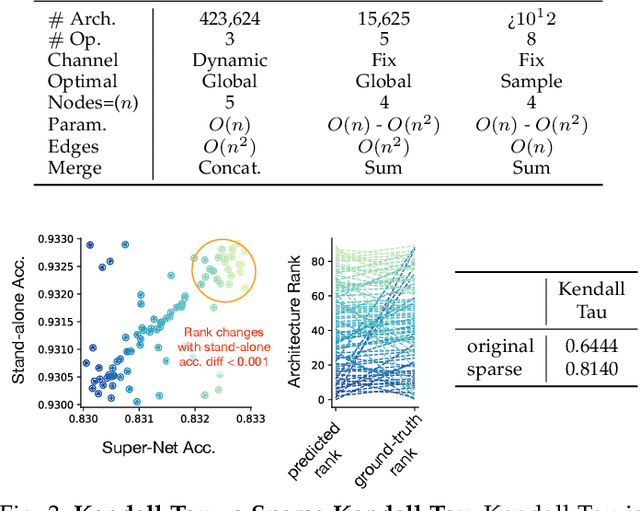
Weight sharing promises to make neural architecture search (NAS) tractable even on commodity hardware. Existing methods in this space rely on a diverse set of heuristics to design and train the shared-weight backbone network, a.k.a. the super-net. Since heuristics substantially vary across different methods and have not been carefully studied, it is unclear to which extent they impact super-net training and hence the weight-sharing NAS algorithms. In this paper, we disentangle super-net training from the search algorithm, isolate 14 frequently-used training heuristics, and evaluate them over three benchmark search spaces. Our analysis uncovers that several commonly-used heuristics negatively impact the correlation between super-net and stand-alone performance, whereas simple, but often overlooked factors, such as proper hyper-parameter settings, are key to achieve strong performance. Equipped with this knowledge, we show that simple random search achieves competitive performance to complex state-of-the-art NAS algorithms when the super-net is properly trained.
Vision Transformers for Dense Prediction
Mar 24, 2021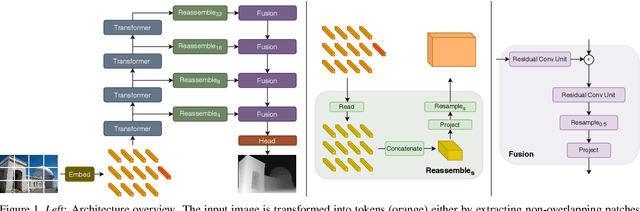
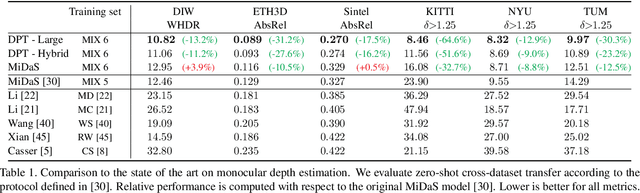
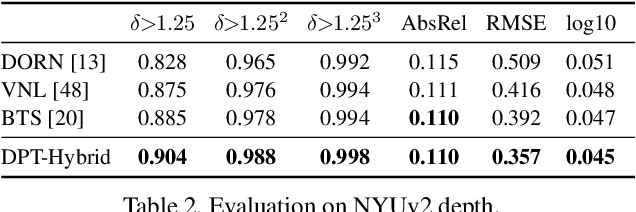

We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art. Our models are available at https://github.com/intel-isl/DPT.
Deep Drone Acrobatics
Jun 11, 2020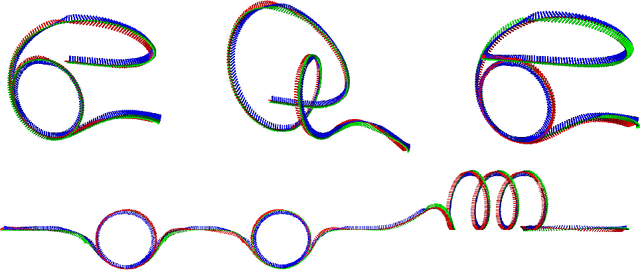
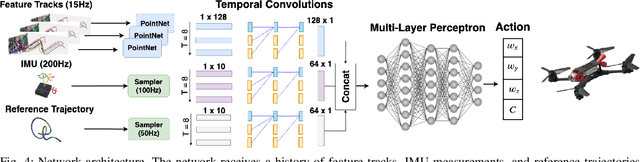

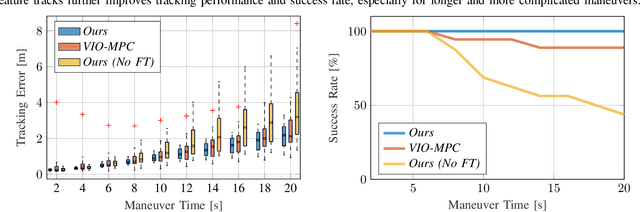
Performing acrobatic maneuvers with quadrotors is extremely challenging. Acrobatic flight requires high thrust and extreme angular accelerations that push the platform to its physical limits. Professional drone pilots often measure their level of mastery by flying such maneuvers in competitions. In this paper, we propose to learn a sensorimotor policy that enables an autonomous quadrotor to fly extreme acrobatic maneuvers with only onboard sensing and computation. We train the policy entirely in simulation by leveraging demonstrations from an optimal controller that has access to privileged information. We use appropriate abstractions of the visual input to enable transfer to a real quadrotor. We show that the resulting policy can be directly deployed in the physical world without any fine-tuning on real data. Our methodology has several favorable properties: it does not require a human expert to provide demonstrations, it cannot harm the physical system during training, and it can be used to learn maneuvers that are challenging even for the best human pilots. Our approach enables a physical quadrotor to fly maneuvers such as the Power Loop, the Barrel Roll, and the Matty Flip, during which it incurs accelerations of up to 3g.
* 8 pages + 2 pages references. Video: https://youtu.be/2N_wKXQ6MXA. Code: https://github.com/uzh-rpg/deep_drone_acrobatics
Safe Robot Navigation via Multi-Modal Anomaly Detection
Jan 22, 2020
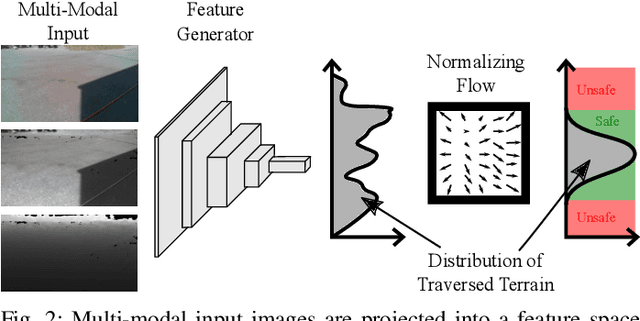
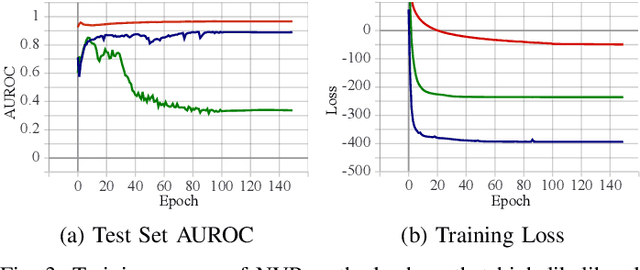

Navigation in natural outdoor environments requires a robust and reliable traversability classification method to handle the plethora of situations a robot can encounter. Binary classification algorithms perform well in their native domain but tend to provide overconfident predictions when presented with out-of-distribution samples, which can lead to catastrophic failure when navigating unknown environments. We propose to overcome this issue by using anomaly detection on multi-modal images for traversability classification, which is easily scalable by training in a self-supervised fashion from robot experience. In this work, we evaluate multiple anomaly detection methods with a combination of uni- and multi-modal images in their performance on data from different environmental conditions. Our results show that an approach using a feature extractor and normalizing flow with an input of RGB, depth and surface normals performs best. It achieves over 95% area under the ROC curve and is robust to out-of-distribution samples.
Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer
Jul 02, 2019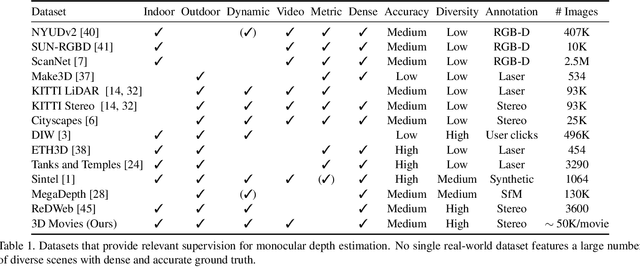

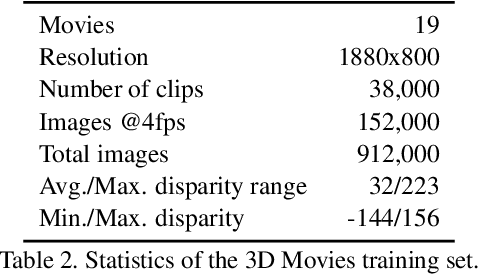
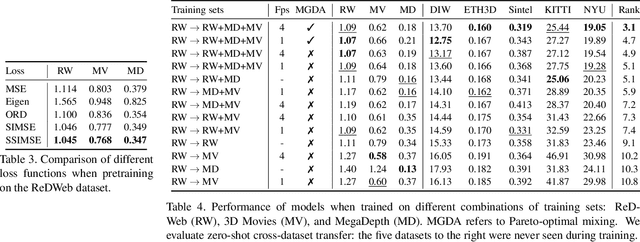
The success of monocular depth estimation relies on large and diverse training sets. Due to the challenges associated with acquiring dense ground-truth depth across different environments at scale, a number of datasets with distinct characteristics and biases have emerged. We develop tools that enable mixing multiple datasets during training, even if their annotations are incompatible. In particular, we propose a training objective that is invariant to changes in depth range and scale. Armed with this objective, we explore an abundant source of training data: 3D films. We demonstrate that despite pervasive inaccuracies, 3D films constitute a useful source of data that is complementary to existing training sets. We evaluate the presented approach on diverse datasets, focusing on zero-shot cross-dataset transfer: testing the generality of the learned model by evaluating it on datasets that were not seen during training. The experiments confirm that mixing data from complementary sources yields improved depth estimates, particularly on previously unseen datasets. Some results are shown in the supplementary video: https://youtu.be/ITI0YS6IrUQ
High Speed and High Dynamic Range Video with an Event Camera
Jun 15, 2019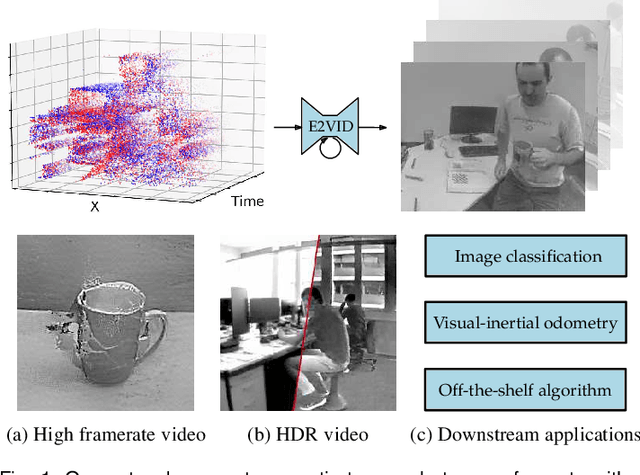
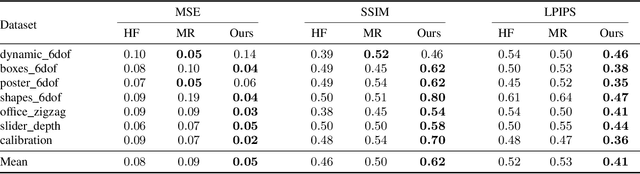
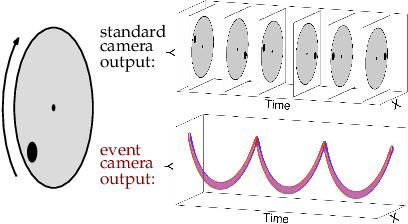
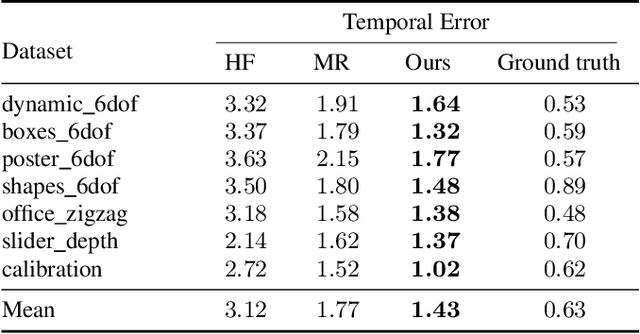
Event cameras are novel sensors that report brightness changes in the form of a stream of asynchronous "events" instead of intensity frames. They offer significant advantages with respect to conventional cameras: high temporal resolution, high dynamic range, and no motion blur. While the stream of events encodes in principle the complete visual signal, the reconstruction of an intensity image from a stream of events is an ill-posed problem in practice. Existing reconstruction approaches are based on hand-crafted priors and strong assumptions about the imaging process as well as the statistics of natural images. In this work we propose to learn to reconstruct intensity images from event streams directly from data instead of relying on any hand-crafted priors. We propose a novel recurrent network to reconstruct videos from a stream of events, and train it on a large amount of simulated event data. During training we propose to use a perceptual loss to encourage reconstructions to follow natural image statistics. We further extend our approach to synthesize color images from color event streams. Our network surpasses state-of-the-art reconstruction methods by a large margin in terms of image quality (> 20%), while comfortably running in real-time. We show that the network is able to synthesize high framerate videos (> 5,000 frames per second) of high-speed phenomena (e.g. a bullet hitting an object) and is able to provide high dynamic range reconstructions in challenging lighting conditions. We also demonstrate the effectiveness of our reconstructions as an intermediate representation for event data. We show that off-the-shelf computer vision algorithms can be applied to our reconstructions for tasks such as object classification and visual-inertial odometry and that this strategy consistently outperforms algorithms that were specifically designed for event data.