 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP3D-Bench: Benchmarking MLLMs for Parametric 3D Generation and Structural Reasoning
Jun 09, 2026Multimodal large language models can write code to produce complex programs as well as use programs to do 3D modeling, which opens up a new avenue for 3D generation powered by their priors, world knowledge and reasoning. Yet existing benchmarks rarely evaluate 3D modeling through code. Such modeling demands more than runnable code: from a text or visual specification, a model must generate a parametric 3D program that is geometrically precise, semantically aligned and assembly-consistent. We introduce P3D-Bench, a benchmark for parametric 3D generation. Unlike a 3D mesh, a parametric 3D program exposes explicit dimensions, construction operations and part relations, revealing whether a model recovers a design's structure, not just its appearance. Under a unified protocol, P3D-Bench covers three task families (Text-to-3D, Image-to-3D and Assembly-3D) and scores each output for executability, geometric fidelity, topology, text-grounded constraints, multiview semantic alignment and part-level structure. We evaluate frontier MLLMs and text-only LLMs on 400 text cases, 400 image cases and 203 annotated assemblies, with domain-specific models as reference points. Our extensive evaluation yields three findings. First, assemblies are the hardest setting, where models still fail to compose multiple parts into a coherent structure. Second, models can often recover the global shape and semantic identity of the target object, yet fail to reproduce the precise parametric geometry specified by the input. Third, part-level modeling remains weak on assemblies, where models recover neither the geometry of each part nor the right number of parts. These results position P3D-Bench as a benchmark for evaluating precise parametric geometry and part-level structure in parametric 3D generation.
Direct3D-S2: Gigascale 3D Generation Made Easy with Spatial Sparse Attention
May 26, 2025



Generating high-resolution 3D shapes using volumetric representations such as Signed Distance Functions (SDFs) presents substantial computational and memory challenges. We introduce Direct3D-S2, a scalable 3D generation framework based on sparse volumes that achieves superior output quality with dramatically reduced training costs. Our key innovation is the Spatial Sparse Attention (SSA) mechanism, which greatly enhances the efficiency of Diffusion Transformer (DiT) computations on sparse volumetric data. SSA allows the model to effectively process large token sets within sparse volumes, substantially reducing computational overhead and achieving a 3.9x speedup in the forward pass and a 9.6x speedup in the backward pass. Our framework also includes a variational autoencoder (VAE) that maintains a consistent sparse volumetric format across input, latent, and output stages. Compared to previous methods with heterogeneous representations in 3D VAE, this unified design significantly improves training efficiency and stability. Our model is trained on public available datasets, and experiments demonstrate that Direct3D-S2 not only surpasses state-of-the-art methods in generation quality and efficiency, but also enables training at 1024 resolution using only 8 GPUs, a task typically requiring at least 32 GPUs for volumetric representations at 256 resolution, thus making gigascale 3D generation both practical and accessible. Project page: https://www.neural4d.com/research/direct3d-s2.
Video Depth Anything: Consistent Depth Estimation for Super-Long Videos
Jan 21, 2025Depth Anything has achieved remarkable success in monocular depth estimation with strong generalization ability. However, it suffers from temporal inconsistency in videos, hindering its practical applications. Various methods have been proposed to alleviate this issue by leveraging video generation models or introducing priors from optical flow and camera poses. Nonetheless, these methods are only applicable to short videos (< 10 seconds) and require a trade-off between quality and computational efficiency. We propose Video Depth Anything for high-quality, consistent depth estimation in super-long videos (over several minutes) without sacrificing efficiency. We base our model on Depth Anything V2 and replace its head with an efficient spatial-temporal head. We design a straightforward yet effective temporal consistency loss by constraining the temporal depth gradient, eliminating the need for additional geometric priors. The model is trained on a joint dataset of video depth and unlabeled images, similar to Depth Anything V2. Moreover, a novel key-frame-based strategy is developed for long video inference. Experiments show that our model can be applied to arbitrarily long videos without compromising quality, consistency, or generalization ability. Comprehensive evaluations on multiple video benchmarks demonstrate that our approach sets a new state-of-the-art in zero-shot video depth estimation. We offer models of different scales to support a range of scenarios, with our smallest model capable of real-time performance at 30 FPS.
Direct3D: Scalable Image-to-3D Generation via 3D Latent Diffusion Transformer
May 23, 2024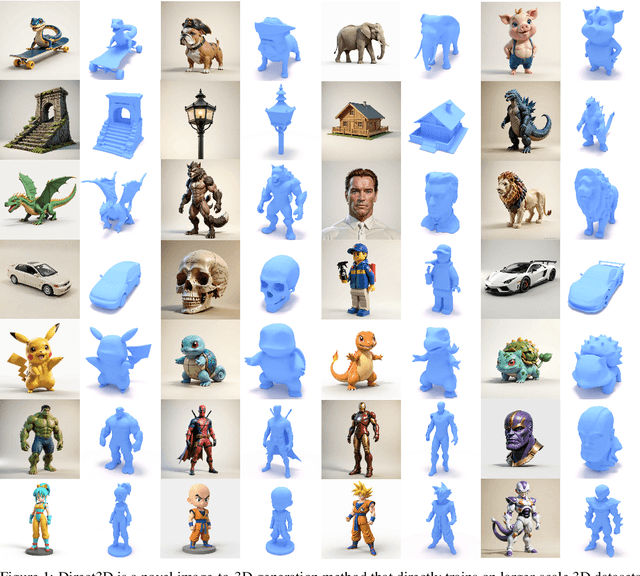

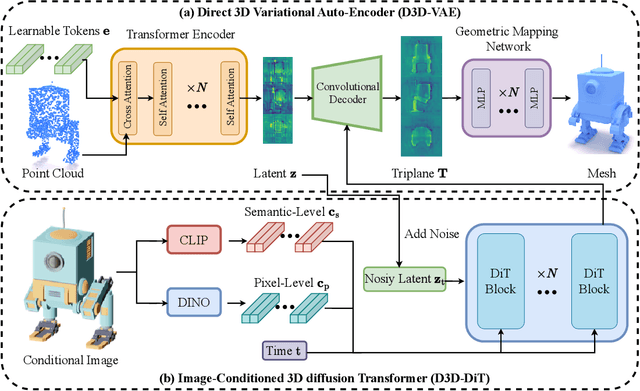
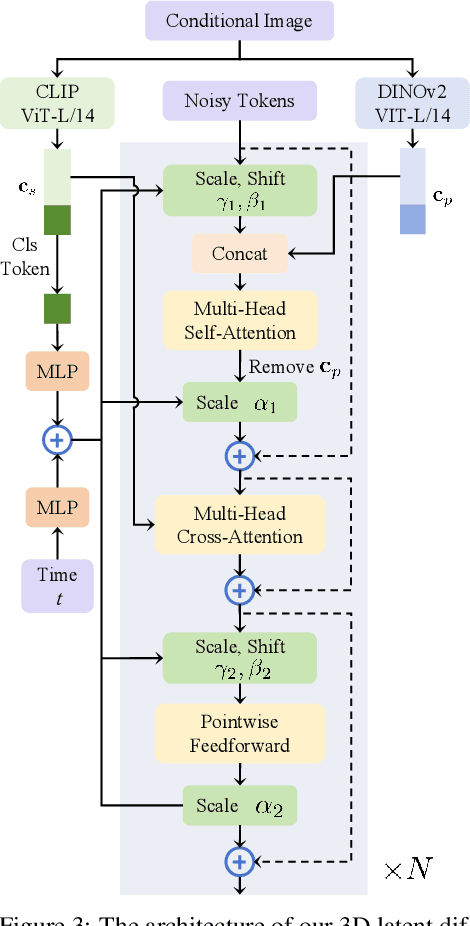
Generating high-quality 3D assets from text and images has long been challenging, primarily due to the absence of scalable 3D representations capable of capturing intricate geometry distributions. In this work, we introduce Direct3D, a native 3D generative model scalable to in-the-wild input images, without requiring a multiview diffusion model or SDS optimization. Our approach comprises two primary components: a Direct 3D Variational Auto-Encoder (D3D-VAE) and a Direct 3D Diffusion Transformer (D3D-DiT). D3D-VAE efficiently encodes high-resolution 3D shapes into a compact and continuous latent triplane space. Notably, our method directly supervises the decoded geometry using a semi-continuous surface sampling strategy, diverging from previous methods relying on rendered images as supervision signals. D3D-DiT models the distribution of encoded 3D latents and is specifically designed to fuse positional information from the three feature maps of the triplane latent, enabling a native 3D generative model scalable to large-scale 3D datasets. Additionally, we introduce an innovative image-to-3D generation pipeline incorporating semantic and pixel-level image conditions, allowing the model to produce 3D shapes consistent with the provided conditional image input. Extensive experiments demonstrate the superiority of our large-scale pre-trained Direct3D over previous image-to-3D approaches, achieving significantly better generation quality and generalization ability, thus establishing a new state-of-the-art for 3D content creation. Project page: https://nju-3dv.github.io/projects/Direct3D/.
Era3D: High-Resolution Multiview Diffusion using Efficient Row-wise Attention
May 19, 2024



In this paper, we introduce Era3D, a novel multiview diffusion method that generates high-resolution multiview images from a single-view image. Despite significant advancements in multiview generation, existing methods still suffer from camera prior mismatch, inefficacy, and low resolution, resulting in poor-quality multiview images. Specifically, these methods assume that the input images should comply with a predefined camera type, e.g. a perspective camera with a fixed focal length, leading to distorted shapes when the assumption fails. Moreover, the full-image or dense multiview attention they employ leads to an exponential explosion of computational complexity as image resolution increases, resulting in prohibitively expensive training costs. To bridge the gap between assumption and reality, Era3D first proposes a diffusion-based camera prediction module to estimate the focal length and elevation of the input image, which allows our method to generate images without shape distortions. Furthermore, a simple but efficient attention layer, named row-wise attention, is used to enforce epipolar priors in the multiview diffusion, facilitating efficient cross-view information fusion. Consequently, compared with state-of-the-art methods, Era3D generates high-quality multiview images with up to a 512*512 resolution while reducing computation complexity by 12x times. Comprehensive experiments demonstrate that Era3D can reconstruct high-quality and detailed 3D meshes from diverse single-view input images, significantly outperforming baseline multiview diffusion methods.
S-NeRF++: Autonomous Driving Simulation via Neural Reconstruction and Generation
Feb 03, 2024



Autonomous driving simulation system plays a crucial role in enhancing self-driving data and simulating complex and rare traffic scenarios, ensuring navigation safety. However, traditional simulation systems, which often heavily rely on manual modeling and 2D image editing, struggled with scaling to extensive scenes and generating realistic simulation data. In this study, we present S-NeRF++, an innovative autonomous driving simulation system based on neural reconstruction. Trained on widely-used self-driving datasets such as nuScenes and Waymo, S-NeRF++ can generate a large number of realistic street scenes and foreground objects with high rendering quality as well as offering considerable flexibility in manipulation and simulation. Specifically, S-NeRF++ is an enhanced neural radiance field for synthesizing large-scale scenes and moving vehicles, with improved scene parameterization and camera pose learning. The system effectively utilizes noisy and sparse LiDAR data to refine training and address depth outliers, ensuring high quality reconstruction and novel-view rendering. It also provides a diverse foreground asset bank through reconstructing and generating different foreground vehicles to support comprehensive scenario creation. Moreover, we have developed an advanced foreground-background fusion pipeline that skillfully integrates illumination and shadow effects, further enhancing the realism of our simulations. With the high-quality simulated data provided by our S-NeRF++, we found the perception methods enjoy performance boost on several autonomous driving downstream tasks, which further demonstrate the effectiveness of our proposed simulator.
Transformation Decoupling Strategy based on Screw Theory for Deterministic Point Cloud Registration with Gravity Prior
Nov 02, 2023Point cloud registration is challenging in the presence of heavy outlier correspondences. This paper focuses on addressing the robust correspondence-based registration problem with gravity prior that often arises in practice. The gravity directions are typically obtained by inertial measurement units (IMUs) and can reduce the degree of freedom (DOF) of rotation from 3 to 1. We propose a novel transformation decoupling strategy by leveraging screw theory. This strategy decomposes the original 4-DOF problem into three sub-problems with 1-DOF, 2-DOF, and 1-DOF, respectively, thereby enhancing the computation efficiency. Specifically, the first 1-DOF represents the translation along the rotation axis and we propose an interval stabbing-based method to solve it. The second 2-DOF represents the pole which is an auxiliary variable in screw theory and we utilize a branch-and-bound method to solve it. The last 1-DOF represents the rotation angle and we propose a global voting method for its estimation. The proposed method sequentially solves three consensus maximization sub-problems, leading to efficient and deterministic registration. In particular, it can even handle the correspondence-free registration problem due to its significant robustness. Extensive experiments on both synthetic and real-world datasets demonstrate that our method is more efficient and robust than state-of-the-art methods, even when dealing with outlier rates exceeding 99%.
Efficient and Deterministic Search Strategy Based on Residual Projections for Point Cloud Registration
May 19, 2023Estimating the rigid transformation between two LiDAR scans through putative 3D correspondences is a typical point cloud registration paradigm. Current 3D feature matching approaches commonly lead to numerous outlier correspondences, making outlier-robust registration techniques indispensable. Many recent studies have adopted the branch and bound (BnB) optimization framework to solve the correspondence-based point cloud registration problem globally and deterministically. Nonetheless, BnB-based methods are time-consuming to search the entire 6-dimensional parameter space, since their computational complexity is exponential to the dimension of the solution domain. In order to enhance algorithm efficiency, existing works attempt to decouple the 6 degrees of freedom (DOF) original problem into two 3-DOF sub-problems, thereby reducing the dimension of the parameter space. In contrast, our proposed approach introduces a novel pose decoupling strategy based on residual projections, effectively decomposing the raw problem into three 2-DOF rotation search sub-problems. Subsequently, we employ a novel BnB-based search method to solve these sub-problems, achieving efficient and deterministic registration. Furthermore, our method can be adapted to address the challenging problem of simultaneous pose and correspondence registration (SPCR). Through extensive experiments conducted on synthetic and real-world datasets, we demonstrate that our proposed method outperforms state-of-the-art methods in terms of efficiency, while simultaneously ensuring robustness.
NeRF-LiDAR: Generating Realistic LiDAR Point Clouds with Neural Radiance Fields
Apr 28, 2023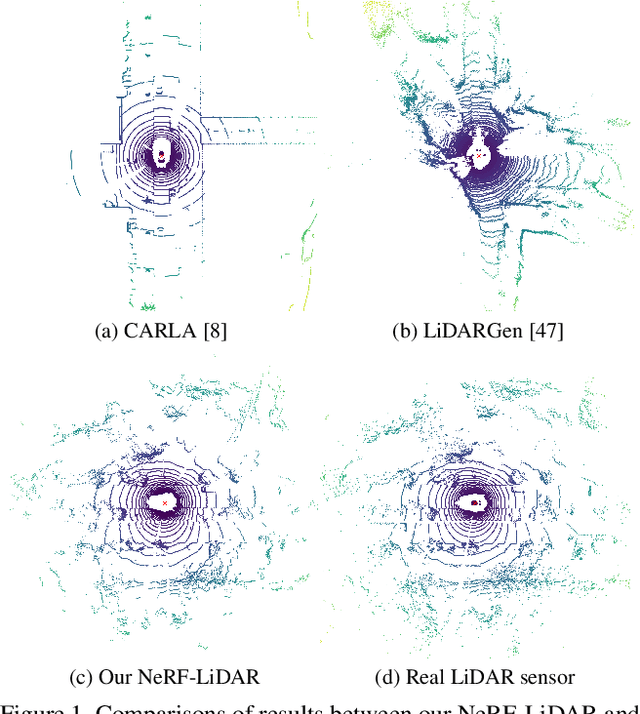
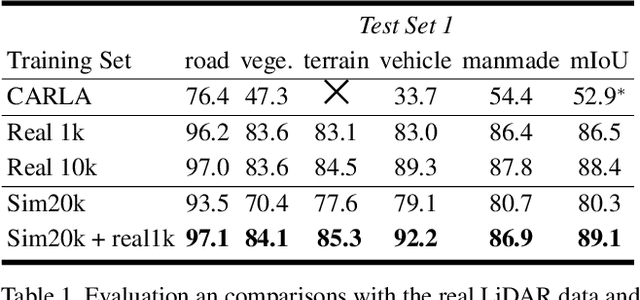
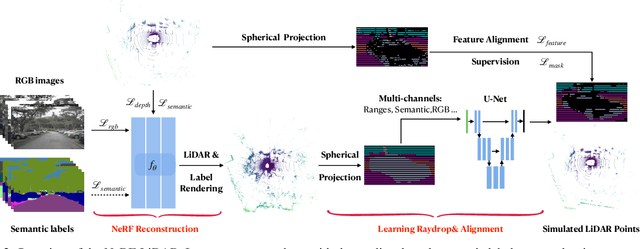
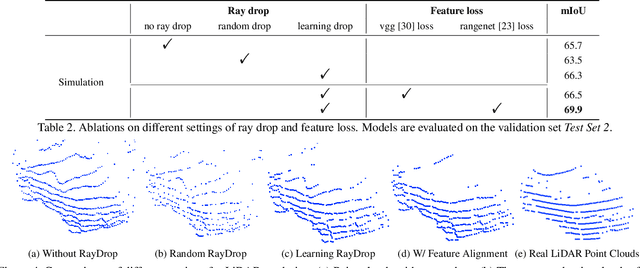
Labeling LiDAR point clouds for training autonomous driving is extremely expensive and difficult. LiDAR simulation aims at generating realistic LiDAR data with labels for training and verifying self-driving algorithms more efficiently. Recently, Neural Radiance Fields (NeRF) have been proposed for novel view synthesis using implicit reconstruction of 3D scenes. Inspired by this, we present NeRF-LIDAR, a novel LiDAR simulation method that leverages real-world information to generate realistic LIDAR point clouds. Different from existing LiDAR simulators, we use real images and point cloud data collected by self-driving cars to learn the 3D scene representation, point cloud generation and label rendering. We verify the effectiveness of our NeRF-LiDAR by training different 3D segmentation models on the generated LiDAR point clouds. It reveals that the trained models are able to achieve similar accuracy when compared with the same model trained on the real LiDAR data. Besides, the generated data is capable of boosting the accuracy through pre-training which helps reduce the requirements of the real labeled data.
Single-view Neural Radiance Fields with Depth Teacher
Mar 17, 2023



Neural Radiance Fields (NeRF) have been proposed for photorealistic novel view rendering. However, it requires many different views of one scene for training. Moreover, it has poor generalizations to new scenes and requires retraining or fine-tuning on each scene. In this paper, we develop a new NeRF model for novel view synthesis using only a single image as input. We propose to combine the (coarse) planar rendering and the (fine) volume rendering to achieve higher rendering quality and better generalizations. We also design a depth teacher net that predicts dense pseudo depth maps to supervise the joint rendering mechanism and boost the learning of consistent 3D geometry. We evaluate our method on three challenging datasets. It outperforms state-of-the-art single-view NeRFs by achieving 5$\sim$20\% improvements in PSNR and reducing 20$\sim$50\% of the errors in the depth rendering. It also shows excellent generalization abilities to unseen data without the need to fine-tune on each new scene.