 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactEMG: Zero-Shot, Low-Latency Intent Detection via sEMG
Jun 24, 2025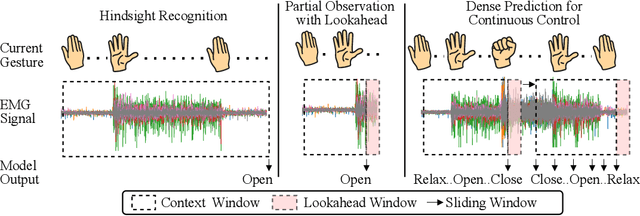
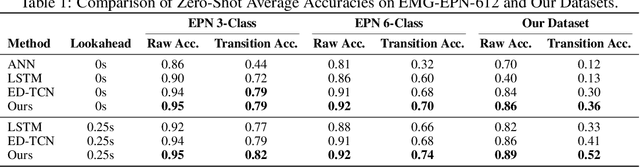
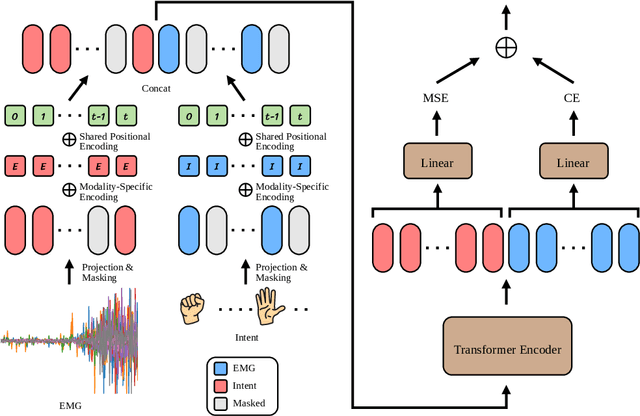
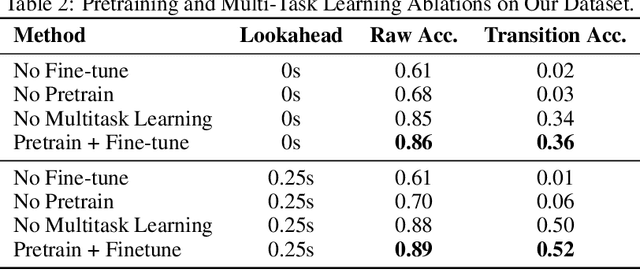
Surface electromyography (sEMG) signals show promise for effective human-computer interfaces, particularly in rehabilitation and prosthetics. However, challenges remain in developing systems that respond quickly and reliably to user intent, across different subjects and without requiring time-consuming calibration. In this work, we propose a framework for EMG-based intent detection that addresses these challenges. Unlike traditional gesture recognition models that wait until a gesture is completed before classifying it, our approach uses a segmentation strategy to assign intent labels at every timestep as the gesture unfolds. We introduce a novel masked modeling strategy that aligns muscle activations with their corresponding user intents, enabling rapid onset detection and stable tracking of ongoing gestures. In evaluations against baseline methods, considering both accuracy and stability for device control, our approach surpasses state-of-the-art performance in zero-shot transfer conditions, demonstrating its potential for wearable robotics and next-generation prosthetic systems. Our project page is available at: https://reactemg.github.io
Reciprocal Learning of Intent Inferral with Augmented Visual Feedback for Stroke
Dec 10, 2024



Intent inferral, the process by which a robotic device predicts a user's intent from biosignals, offers an effective and intuitive way to control wearable robots. Classical intent inferral methods treat biosignal inputs as unidirectional ground truths for training machine learning models, where the internal state of the model is not directly observable by the user. In this work, we propose reciprocal learning, a bidirectional paradigm that facilitates human adaptation to an intent inferral classifier. Our paradigm consists of iterative, interwoven stages that alternate between updating machine learning models and guiding human adaptation with the use of augmented visual feedback. We demonstrate this paradigm in the context of controlling a robotic hand orthosis for stroke, where the device predicts open, close, and relax intents from electromyographic (EMG) signals and provides appropriate assistance. We use LED progress-bar displays to communicate to the user the predicted probabilities for open and close intents by the classifier. Our experiments with stroke subjects show reciprocal learning improving performance in a subset of subjects (two out of five) without negatively impacting performance on the others. We hypothesize that, during reciprocal learning, subjects can learn to reproduce more distinguishable muscle activation patterns and generate more separable biosignals.
ChatEMG: Synthetic Data Generation to Control a Robotic Hand Orthosis for Stroke
Jun 17, 2024



Intent inferral on a hand orthosis for stroke patients is challenging due to the difficulty of data collection from impaired subjects. Additionally, EMG signals exhibit significant variations across different conditions, sessions, and subjects, making it hard for classifiers to generalize. Traditional approaches require a large labeled dataset from the new condition, session, or subject to train intent classifiers; however, this data collection process is burdensome and time-consuming. In this paper, we propose ChatEMG, an autoregressive generative model that can generate synthetic EMG signals conditioned on prompts (i.e., a given sequence of EMG signals). ChatEMG enables us to collect only a small dataset from the new condition, session, or subject and expand it with synthetic samples conditioned on prompts from this new context. ChatEMG leverages a vast repository of previous data via generative training while still remaining context-specific via prompting. Our experiments show that these synthetic samples are classifier-agnostic and can improve intent inferral accuracy for different types of classifiers. We demonstrate that our complete approach can be integrated into a single patient session, including the use of the classifier for functional orthosis-assisted tasks. To the best of our knowledge, this is the first time an intent classifier trained partially on synthetic data has been deployed for functional control of an orthosis by a stroke survivor. Videos and additional information can be found at https://jxu.ai/chatemg.
Direct3D: Scalable Image-to-3D Generation via 3D Latent Diffusion Transformer
May 23, 2024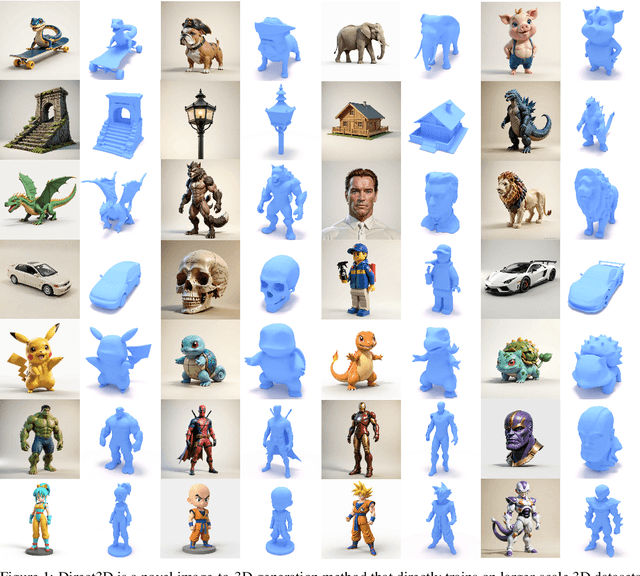

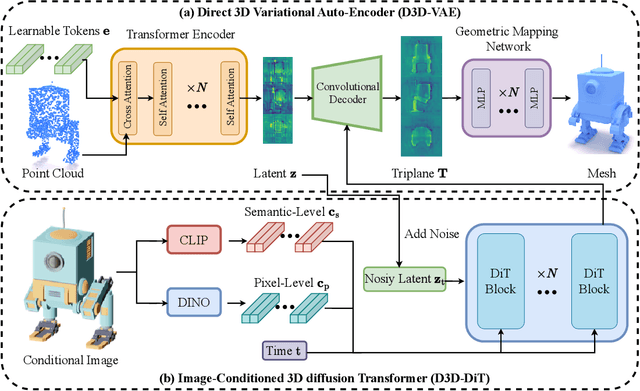
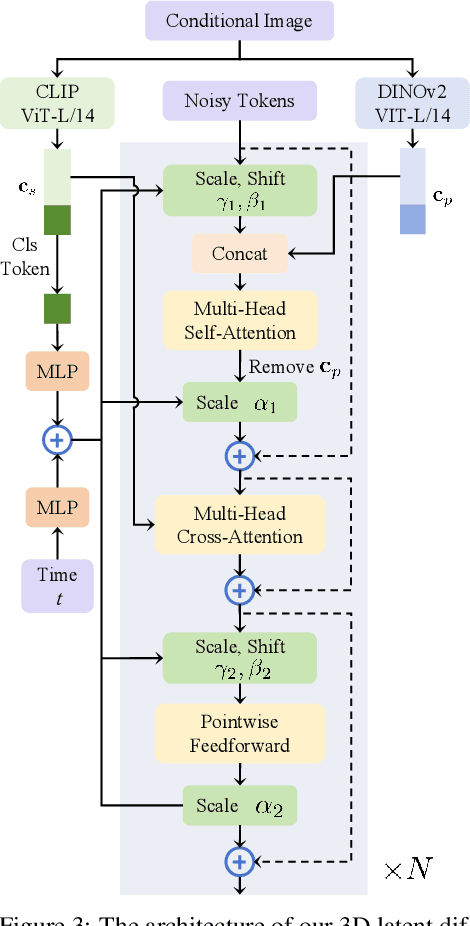
Generating high-quality 3D assets from text and images has long been challenging, primarily due to the absence of scalable 3D representations capable of capturing intricate geometry distributions. In this work, we introduce Direct3D, a native 3D generative model scalable to in-the-wild input images, without requiring a multiview diffusion model or SDS optimization. Our approach comprises two primary components: a Direct 3D Variational Auto-Encoder (D3D-VAE) and a Direct 3D Diffusion Transformer (D3D-DiT). D3D-VAE efficiently encodes high-resolution 3D shapes into a compact and continuous latent triplane space. Notably, our method directly supervises the decoded geometry using a semi-continuous surface sampling strategy, diverging from previous methods relying on rendered images as supervision signals. D3D-DiT models the distribution of encoded 3D latents and is specifically designed to fuse positional information from the three feature maps of the triplane latent, enabling a native 3D generative model scalable to large-scale 3D datasets. Additionally, we introduce an innovative image-to-3D generation pipeline incorporating semantic and pixel-level image conditions, allowing the model to produce 3D shapes consistent with the provided conditional image input. Extensive experiments demonstrate the superiority of our large-scale pre-trained Direct3D over previous image-to-3D approaches, achieving significantly better generation quality and generalization ability, thus establishing a new state-of-the-art for 3D content creation. Project page: https://nju-3dv.github.io/projects/Direct3D/.
Meta-Learning for Fast Adaptation in Intent Inferral on a Robotic Hand Orthosis for Stroke
Mar 19, 2024



We propose MetaEMG, a meta-learning approach for fast adaptation in intent inferral on a robotic hand orthosis for stroke. One key challenge in machine learning for assistive and rehabilitative robotics with disabled-bodied subjects is the difficulty of collecting labeled training data. Muscle tone and spasticity often vary significantly among stroke subjects, and hand function can even change across different use sessions of the device for the same subject. We investigate the use of meta-learning to mitigate the burden of data collection needed to adapt high-capacity neural networks to a new session or subject. Our experiments on real clinical data collected from five stroke subjects show that MetaEMG can improve the intent inferral accuracy with a small session- or subject-specific dataset and very few fine-tuning epochs. To the best of our knowledge, we are the first to formulate intent inferral on stroke subjects as a meta-learning problem and demonstrate fast adaptation to a new session or subject for controlling a robotic hand orthosis with EMG signals.
Tactile-based Object Retrieval From Granular Media
Feb 21, 2024



We introduce GEOTACT, a robotic manipulation method capable of retrieving objects buried in granular media. This is a challenging task due to the need to interact with granular media, and doing so based exclusively on tactile feedback, since a buried object can be completely hidden from vision. Tactile feedback is in itself challenging in this context, due to ubiquitous contact with the surrounding media, and the inherent noise level induced by the tactile readings. To address these challenges, we use a learning method trained end-to-end with simulated sensor noise. We show that our problem formulation leads to the natural emergence of learned pushing behaviors that the manipulator uses to reduce uncertainty and funnel the object to a stable grasp despite spurious and noisy tactile readings. We also introduce a training curriculum that enables learning these behaviors in simulation, followed by zero-shot transfer to real hardware. To the best of our knowledge, GEOTACT is the first method to reliably retrieve a number of different objects from a granular environment, doing so on real hardware and with integrated tactile sensing. Videos and additional information can be found at https://jxu.ai/geotact.
Volitional Control of the Paretic Hand Post-Stroke Increases Finger Stiffness and Resistance to Robot-Assisted Movement
Feb 12, 2024
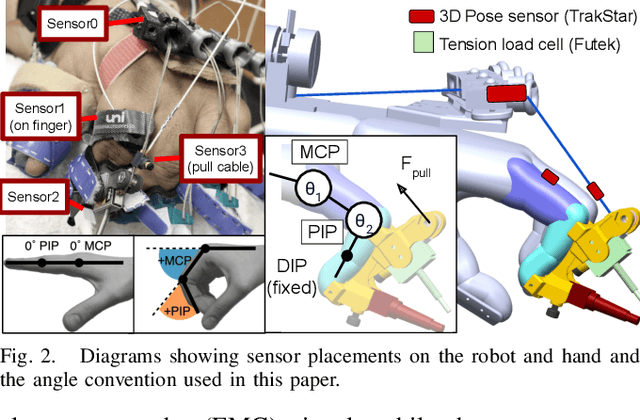
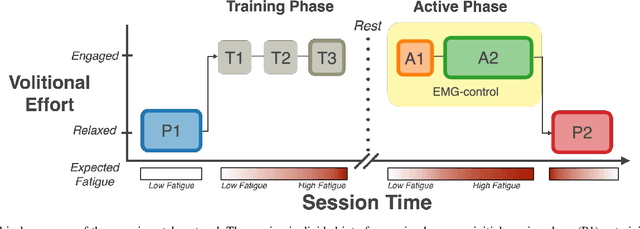
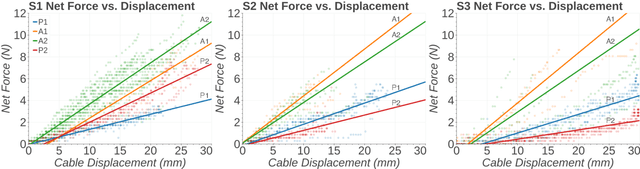
Increased effort during use of the paretic arm and hand can provoke involuntary abnormal synergy patterns and amplify stiffness effects of muscle tone for individuals after stroke, which can add difficulty for user-controlled devices to assist hand movement during functional tasks. We study how volitional effort, exerted in an attempt to open or close the hand, affects resistance to robot-assisted movement at the finger level. We perform experiments with three chronic stroke survivors to measure changes in stiffness when the user is actively exerting effort to activate ipsilateral EMG-controlled robot-assisted hand movements, compared with when the fingers are passively stretched, as well as overall effects from sustained active engagement and use. Our results suggest that active engagement of the upper extremity increases muscle tone in the finger to a much greater degree than through passive-stretch or sustained exertion over time. Potential design implications of this work suggest that developers should anticipate higher levels of finger stiffness when relying on user-driven ipsilateral control methods for assistive or rehabilitative devices for stroke.
An Investigation of Multi-feature Extraction and Super-resolution with Fast Microphone Arrays
Sep 30, 2023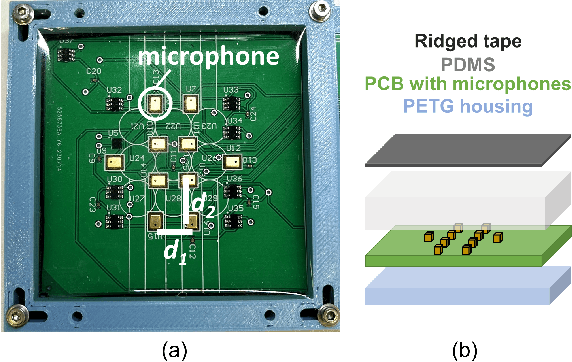

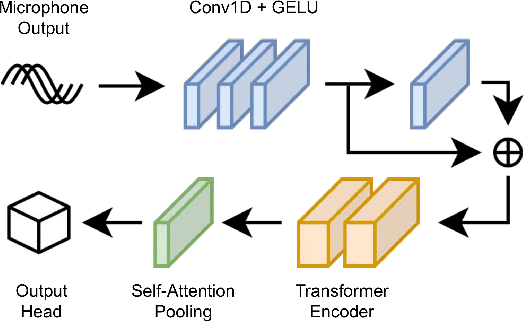

In this work, we use MEMS microphones as vibration sensors to simultaneously classify texture and estimate contact position and velocity. Vibration sensors are an important facet of both human and robotic tactile sensing, providing fast detection of contact and onset of slip. Microphones are an attractive option for implementing vibration sensing as they offer a fast response and can be sampled quickly, are affordable, and occupy a very small footprint. Our prototype sensor uses only a sparse array of distributed MEMS microphones (8-9 mm spacing) embedded under an elastomer. We use transformer-based architectures for data analysis, taking advantage of the microphones' high sampling rate to run our models on time-series data as opposed to individual snapshots. This approach allows us to obtain 77.3% average accuracy on 4-class texture classification (84.2% when excluding the slowest drag velocity), 1.5 mm median error on contact localization, and 4.5 mm/s median error on contact velocity. We show that the learned texture and localization models are robust to varying velocity and generalize to unseen velocities. We also report that our sensor provides fast contact detection, an important advantage of fast transducers. This investigation illustrates the capabilities one can achieve with a MEMS microphone array alone, leaving valuable sensor real estate available for integration with complementary tactile sensing modalities.
Learning a Meta-Controller for Dynamic Grasping
Feb 16, 2023



Grasping moving objects is a challenging task that combines multiple submodules such as object pose predictor, arm motion planner, etc. Each submodule operates under its own set of meta-parameters. For example, how far the pose predictor should look into the future (i.e., look-ahead time) and the maximum amount of time the motion planner can spend planning a motion (i.e., time budget). Many previous works assign fixed values to these parameters either heuristically or through grid search; however, at different moments within a single episode of dynamic grasping, the optimal values should vary depending on the current scene. In this work, we learn a meta-controller through reinforcement learning to control the look-ahead time and time budget dynamically. Our extensive experiments show that the meta-controller improves the grasping success rate (up to 12% in the most cluttered environment) and reduces grasping time, compared to the strongest baseline. Our meta-controller learns to reason about the reachable workspace and maintain the predicted pose within the reachable region. In addition, it assigns a small but sufficient time budget for the motion planner. Our method can handle different target objects, trajectories, and obstacles. Despite being trained only with 3-6 randomly generated cuboidal obstacles, our meta-controller generalizes well to 7-9 obstacles and more realistic out-of-domain household setups with unseen obstacle shapes. Video is available at https://youtu.be/CwHq77wFQqI.
TANDEM3D: Active Tactile Exploration for 3D Object Recognition
Sep 19, 2022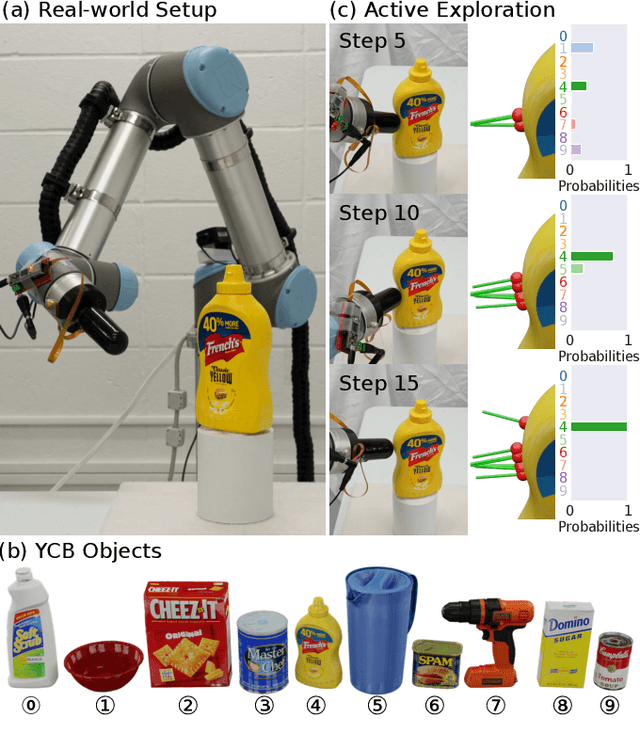
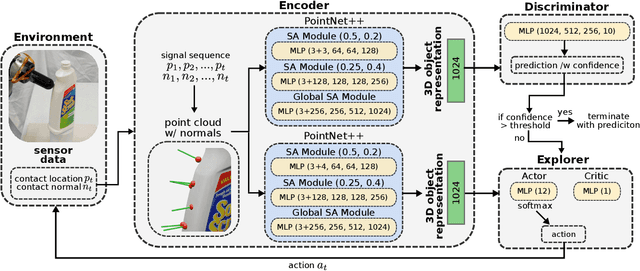

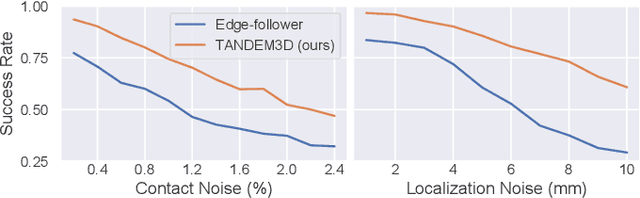
Tactile recognition of 3D objects remains a challenging task. Compared to 2D shapes, the complex geometry of 3D surfaces requires richer tactile signals, more dexterous actions, and more advanced encoding techniques. In this work, we propose TANDEM3D, a method that applies a co-training framework for exploration and decision making to 3D object recognition with tactile signals. Starting with our previous work, which introduced a co-training paradigm for 2D recognition problems, we introduce a number of advances that enable us to scale up to 3D. TANDEM3D is based on a novel encoder that builds 3D object representation from contact positions and normals using PointNet++. Furthermore, by enabling 6DOF movement, TANDEM3D explores and collects discriminative touch information with high efficiency. Our method is trained entirely in simulation and validated with real-world experiments. Compared to state-of-the-art baselines, TANDEM3D achieves higher accuracy and a lower number of actions in recognizing 3D objects and is also shown to be more robust to different types and amounts of sensor noise. Video is available at https://jxu.ai/tandem3d.