 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Aware Policy Learning for Adaptive and Punctual Robot Control
Nov 10, 2025


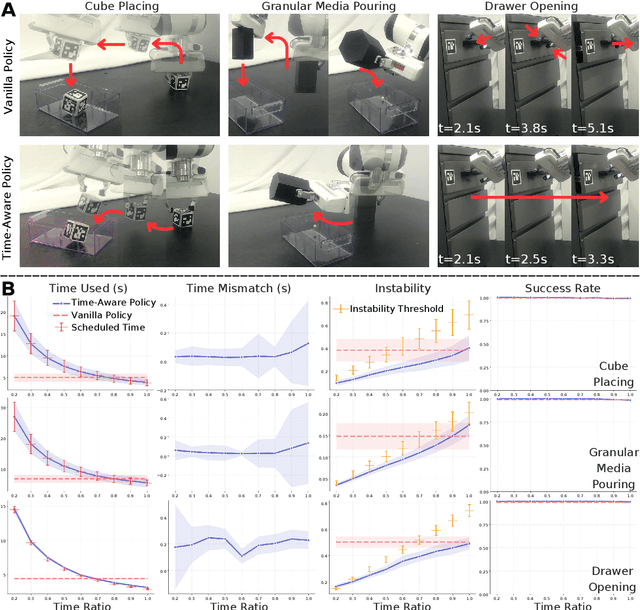
Temporal awareness underlies intelligent behavior in both animals and humans, guiding how actions are sequenced, paced, and adapted to changing goals and environments. Yet most robot learning algorithms remain blind to time. We introduce time-aware policy learning, a reinforcement learning framework that enables robots to explicitly perceive and reason with time as a first-class variable. The framework augments conventional reinforcement policies with two complementary temporal signals, the remaining time and a time ratio, which allow a single policy to modulate its behavior continuously from rapid and dynamic to cautious and precise execution. By jointly optimizing punctuality and stability, the robot learns to balance efficiency, robustness, resiliency, and punctuality without re-training or reward adjustment. Across diverse manipulation domains from long-horizon pick and place, to granular-media pouring, articulated-object handling, and multi-agent object delivery, the time-aware policy produces adaptive behaviors that outperform standard reinforcement learning baselines by up to 48% in efficiency, 8 times more robust in sim-to-real transfer, and 90% in acoustic quietness while maintaining near-perfect success rates. Explicit temporal reasoning further enables real-time human-in-the-loop control and multi-agent coordination, allowing robots to recover from disturbances, re-synchronize after delays, and align motion tempo with human intent. By treating time not as a constraint but as a controllable dimension of behavior, time-aware policy learning provides a unified foundation for efficient, robust, resilient, and human-aligned robot autonomy.
ClutterGen: A Cluttered Scene Generator for Robot Learning
Jul 07, 2024We introduce ClutterGen, a physically compliant simulation scene generator capable of producing highly diverse, cluttered, and stable scenes for robot learning. Generating such scenes is challenging as each object must adhere to physical laws like gravity and collision. As the number of objects increases, finding valid poses becomes more difficult, necessitating significant human engineering effort, which limits the diversity of the scenes. To overcome these challenges, we propose a reinforcement learning method that can be trained with physics-based reward signals provided by the simulator. Our experiments demonstrate that ClutterGen can generate cluttered object layouts with up to ten objects on confined table surfaces. Additionally, our policy design explicitly encourages the diversity of the generated scenes for open-ended generation. Our real-world robot results show that ClutterGen can be directly used for clutter rearrangement and stable placement policy training.
Tactile-based Object Retrieval From Granular Media
Feb 21, 2024



We introduce GEOTACT, a robotic manipulation method capable of retrieving objects buried in granular media. This is a challenging task due to the need to interact with granular media, and doing so based exclusively on tactile feedback, since a buried object can be completely hidden from vision. Tactile feedback is in itself challenging in this context, due to ubiquitous contact with the surrounding media, and the inherent noise level induced by the tactile readings. To address these challenges, we use a learning method trained end-to-end with simulated sensor noise. We show that our problem formulation leads to the natural emergence of learned pushing behaviors that the manipulator uses to reduce uncertainty and funnel the object to a stable grasp despite spurious and noisy tactile readings. We also introduce a training curriculum that enables learning these behaviors in simulation, followed by zero-shot transfer to real hardware. To the best of our knowledge, GEOTACT is the first method to reliably retrieve a number of different objects from a granular environment, doing so on real hardware and with integrated tactile sensing. Videos and additional information can be found at https://jxu.ai/geotact.
Learning a Meta-Controller for Dynamic Grasping
Feb 16, 2023



Grasping moving objects is a challenging task that combines multiple submodules such as object pose predictor, arm motion planner, etc. Each submodule operates under its own set of meta-parameters. For example, how far the pose predictor should look into the future (i.e., look-ahead time) and the maximum amount of time the motion planner can spend planning a motion (i.e., time budget). Many previous works assign fixed values to these parameters either heuristically or through grid search; however, at different moments within a single episode of dynamic grasping, the optimal values should vary depending on the current scene. In this work, we learn a meta-controller through reinforcement learning to control the look-ahead time and time budget dynamically. Our extensive experiments show that the meta-controller improves the grasping success rate (up to 12% in the most cluttered environment) and reduces grasping time, compared to the strongest baseline. Our meta-controller learns to reason about the reachable workspace and maintain the predicted pose within the reachable region. In addition, it assigns a small but sufficient time budget for the motion planner. Our method can handle different target objects, trajectories, and obstacles. Despite being trained only with 3-6 randomly generated cuboidal obstacles, our meta-controller generalizes well to 7-9 obstacles and more realistic out-of-domain household setups with unseen obstacle shapes. Video is available at https://youtu.be/CwHq77wFQqI.