 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflective Gaussian Splatting
Dec 26, 2024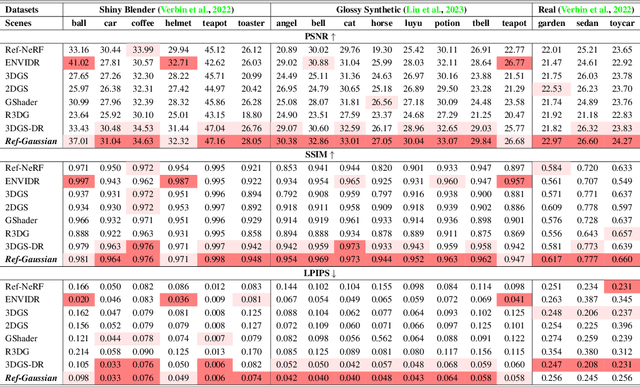
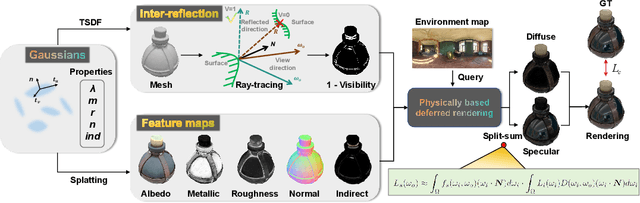
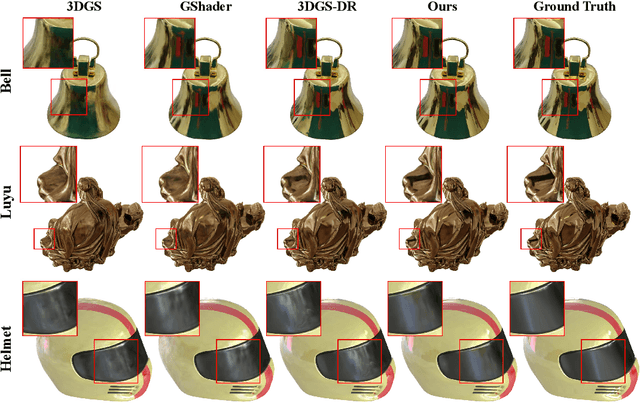

Novel view synthesis has experienced significant advancements owing to increasingly capable NeRF- and 3DGS-based methods. However, reflective object reconstruction remains challenging, lacking a proper solution to achieve real-time, high-quality rendering while accommodating inter-reflection. To fill this gap, we introduce a Reflective Gaussian splatting (\textbf{Ref-Gaussian}) framework characterized with two components: (I) {\em Physically based deferred rendering} that empowers the rendering equation with pixel-level material properties via formulating split-sum approximation; (II) {\em Gaussian-grounded inter-reflection} that realizes the desired inter-reflection function within a Gaussian splatting paradigm for the first time. To enhance geometry modeling, we further introduce material-aware normal propagation and an initial per-Gaussian shading stage, along with 2D Gaussian primitives. Extensive experiments on standard datasets demonstrate that Ref-Gaussian surpasses existing approaches in terms of quantitative metrics, visual quality, and compute efficiency. Further, we show that our method serves as a unified solution for both reflective and non-reflective scenes, going beyond the previous alternatives focusing on only reflective scenes. Also, we illustrate that Ref-Gaussian supports more applications such as relighting and editing.
IRGS: Inter-Reflective Gaussian Splatting with 2D Gaussian Ray Tracing
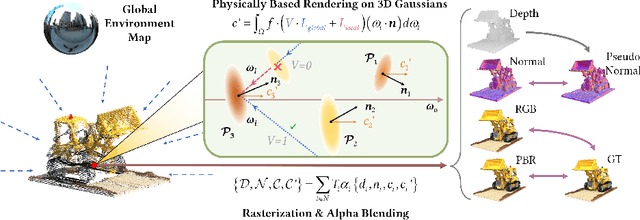
Dec 20, 2024In inverse rendering, accurately modeling visibility and indirect radiance for incident light is essential for capturing secondary effects. Due to the absence of a powerful Gaussian ray tracer, previous 3DGS-based methods have either adopted a simplified rendering equation or used learnable parameters to approximate incident light, resulting in inaccurate material and lighting estimations. To this end, we introduce inter-reflective Gaussian splatting (IRGS) for inverse rendering. To capture inter-reflection, we apply the full rendering equation without simplification and compute incident radiance on the fly using the proposed differentiable 2D Gaussian ray tracing. Additionally, we present an efficient optimization scheme to handle the computational demands of Monte Carlo sampling for rendering equation evaluation. Furthermore, we introduce a novel strategy for querying the indirect radiance of incident light when relighting the optimized scenes. Extensive experiments on multiple standard benchmarks validate the effectiveness of IRGS, demonstrating its capability to accurately model complex inter-reflection effects.
Tetrahedron Splatting for 3D Generation
Jun 03, 2024



3D representation is essential to the significant advance of 3D generation with 2D diffusion priors. As a flexible representation, NeRF has been first adopted for 3D representation. With density-based volumetric rendering, it however suffers both intensive computational overhead and inaccurate mesh extraction. Using a signed distance field and Marching Tetrahedra, DMTet allows for precise mesh extraction and real-time rendering but is limited in handling large topological changes in meshes, leading to optimization challenges. Alternatively, 3D Gaussian Splatting (3DGS) is favored in both training and rendering efficiency while falling short in mesh extraction. In this work, we introduce a novel 3D representation, Tetrahedron Splatting (TeT-Splatting), that supports easy convergence during optimization, precise mesh extraction, and real-time rendering simultaneously. This is achieved by integrating surface-based volumetric rendering within a structured tetrahedral grid while preserving the desired ability of precise mesh extraction, and a tile-based differentiable tetrahedron rasterizer. Furthermore, we incorporate eikonal and normal consistency regularization terms for the signed distance field to improve generation quality and stability. Critically, our representation can be trained without mesh extraction, making the optimization process easier to converge. Our TeT-Splatting can be readily integrated in existing 3D generation pipelines, along with polygonal mesh for texture optimization. Extensive experiments show that our TeT-Splatting strikes a superior tradeoff among convergence speed, render efficiency, and mesh quality as compared to previous alternatives under varying 3D generation settings.
Diffusion$^2$: Dynamic 3D Content Generation via Score Composition of Orthogonal Diffusion Models
Apr 02, 2024



Recent advancements in 3D generation are predominantly propelled by improvements in 3D-aware image diffusion models which are pretrained on Internet-scale image data and fine-tuned on massive 3D data, offering the capability of producing highly consistent multi-view images. However, due to the scarcity of synchronized multi-view video data, it is impractical to adapt this paradigm to 4D generation directly. Despite that, the available video and 3D data are adequate for training video and multi-view diffusion models that can provide satisfactory dynamic and geometric priors respectively. In this paper, we present Diffusion$^2$, a novel framework for dynamic 3D content creation that leverages the knowledge about geometric consistency and temporal smoothness from these models to directly sample dense multi-view and multi-frame images which can be employed to optimize continuous 4D representation. Specifically, we design a simple yet effective denoising strategy via score composition of video and multi-view diffusion models based on the probability structure of the images to be generated. Owing to the high parallelism of the image generation and the efficiency of the modern 4D reconstruction pipeline, our framework can generate 4D content within few minutes. Furthermore, our method circumvents the reliance on 4D data, thereby having the potential to benefit from the scalability of the foundation video and multi-view diffusion models. Extensive experiments demonstrate the efficacy of our proposed framework and its capability to flexibly adapt to various types of prompts.
Periodic Vibration Gaussian: Dynamic Urban Scene Reconstruction and Real-time Rendering
Nov 30, 2023Modeling dynamic, large-scale urban scenes is challenging due to their highly intricate geometric structures and unconstrained dynamics in both space and time. Prior methods often employ high-level architectural priors, separating static and dynamic elements, resulting in suboptimal capture of their synergistic interactions. To address this challenge, we present a unified representation model, called Periodic Vibration Gaussian (PVG). PVG builds upon the efficient 3D Gaussian splatting technique, originally designed for static scene representation, by introducing periodic vibration-based temporal dynamics. This innovation enables PVG to elegantly and uniformly represent the characteristics of various objects and elements in dynamic urban scenes. To enhance temporally coherent representation learning with sparse training data, we introduce a novel flow-based temporal smoothing mechanism and a position-aware adaptive control strategy. Extensive experiments on Waymo Open Dataset and KITTI benchmarks demonstrate that PVG surpasses state-of-the-art alternatives in both reconstruction and novel view synthesis for both dynamic and static scenes. Notably, PVG achieves this without relying on manually labeled object bounding boxes or expensive optical flow estimation. Moreover, PVG exhibits 50/6000-fold acceleration in training/rendering over the best alternative.
Relightable 3D Gaussian: Real-time Point Cloud Relighting with BRDF Decomposition and Ray Tracing
Nov 27, 2023
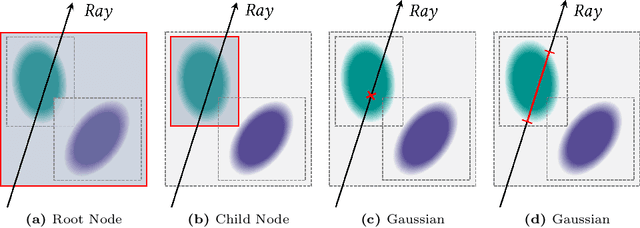
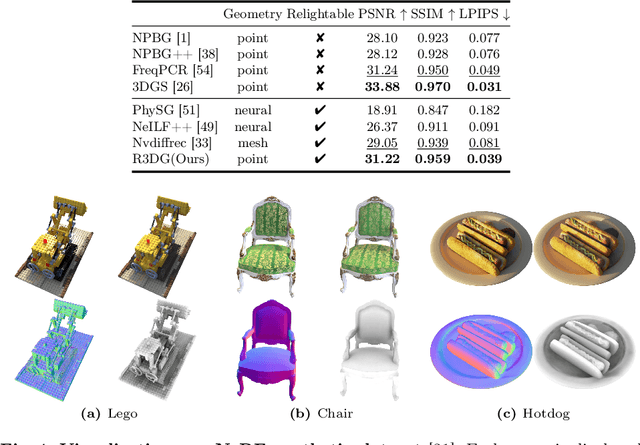
We present a novel differentiable point-based rendering framework for material and lighting decomposition from multi-view images, enabling editing, ray-tracing, and real-time relighting of the 3D point cloud. Specifically, a 3D scene is represented as a set of relightable 3D Gaussian points, where each point is additionally associated with a normal direction, BRDF parameters, and incident lights from different directions. To achieve robust lighting estimation, we further divide incident lights of each point into global and local components, as well as view-dependent visibilities. The 3D scene is optimized through the 3D Gaussian Splatting technique while BRDF and lighting are decomposed by physically-based differentiable rendering. Moreover, we introduce an innovative point-based ray-tracing approach based on the bounding volume hierarchy for efficient visibility baking, enabling real-time rendering and relighting of 3D Gaussian points with accurate shadow effects. Extensive experiments demonstrate improved BRDF estimation and novel view rendering results compared to state-of-the-art material estimation approaches. Our framework showcases the potential to revolutionize the mesh-based graphics pipeline with a relightable, traceable, and editable rendering pipeline solely based on point cloud. Project page:https://nju-3dv.github.io/projects/Relightable3DGaussian/.
Single-view Neural Radiance Fields with Depth Teacher
Mar 17, 2023



Neural Radiance Fields (NeRF) have been proposed for photorealistic novel view rendering. However, it requires many different views of one scene for training. Moreover, it has poor generalizations to new scenes and requires retraining or fine-tuning on each scene. In this paper, we develop a new NeRF model for novel view synthesis using only a single image as input. We propose to combine the (coarse) planar rendering and the (fine) volume rendering to achieve higher rendering quality and better generalizations. We also design a depth teacher net that predicts dense pseudo depth maps to supervise the joint rendering mechanism and boost the learning of consistent 3D geometry. We evaluate our method on three challenging datasets. It outperforms state-of-the-art single-view NeRFs by achieving 5$\sim$20\% improvements in PSNR and reducing 20$\sim$50\% of the errors in the depth rendering. It also shows excellent generalization abilities to unseen data without the need to fine-tune on each new scene.