 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Real-World Acrobatic Flight from Human Preferences
Aug 26, 2025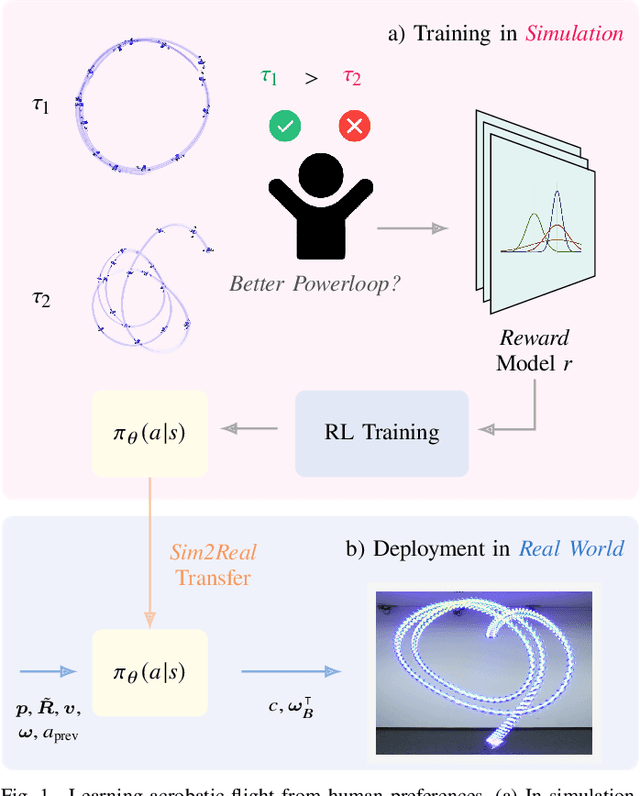
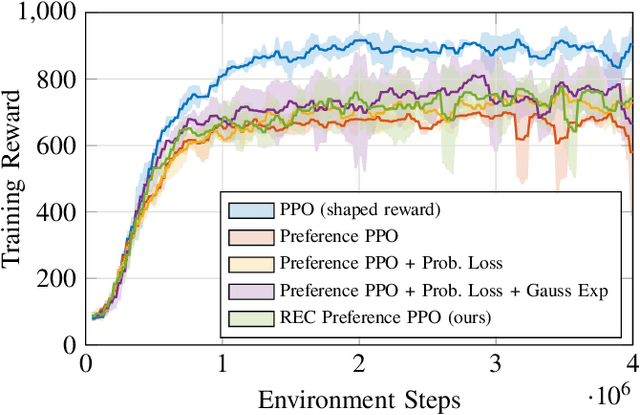


Preference-based reinforcement learning (PbRL) enables agents to learn control policies without requiring manually designed reward functions, making it well-suited for tasks where objectives are difficult to formalize or inherently subjective. Acrobatic flight poses a particularly challenging problem due to its complex dynamics, rapid movements, and the importance of precise execution. In this work, we explore the use of PbRL for agile drone control, focusing on the execution of dynamic maneuvers such as powerloops. Building on Preference-based Proximal Policy Optimization (Preference PPO), we propose Reward Ensemble under Confidence (REC), an extension to the reward learning objective that improves preference modeling and learning stability. Our method achieves 88.4% of the shaped reward performance, compared to 55.2% with standard Preference PPO. We train policies in simulation and successfully transfer them to real-world drones, demonstrating multiple acrobatic maneuvers where human preferences emphasize stylistic qualities of motion. Furthermore, we demonstrate the applicability of our probabilistic reward model in a representative MuJoCo environment for continuous control. Finally, we highlight the limitations of manually designed rewards, observing only 60.7% agreement with human preferences. These results underscore the effectiveness of PbRL in capturing complex, human-centered objectives across both physical and simulated domains.
Dream to Fly: Model-Based Reinforcement Learning for Vision-Based Drone Flight
Jan 24, 2025Autonomous drone racing has risen as a challenging robotic benchmark for testing the limits of learning, perception, planning, and control. Expert human pilots are able to agilely fly a drone through a race track by mapping the real-time feed from a single onboard camera directly to control commands. Recent works in autonomous drone racing attempting direct pixel-to-commands control policies (without explicit state estimation) have relied on either intermediate representations that simplify the observation space or performed extensive bootstrapping using Imitation Learning (IL). This paper introduces an approach that learns policies from scratch, allowing a quadrotor to autonomously navigate a race track by directly mapping raw onboard camera pixels to control commands, just as human pilots do. By leveraging model-based reinforcement learning~(RL) - specifically DreamerV3 - we train visuomotor policies capable of agile flight through a race track using only raw pixel observations. While model-free RL methods such as PPO struggle to learn under these conditions, DreamerV3 efficiently acquires complex visuomotor behaviors. Moreover, because our policies learn directly from pixel inputs, the perception-aware reward term employed in previous RL approaches to guide the training process is no longer needed. Our experiments demonstrate in both simulation and real-world flight how the proposed approach can be deployed on agile quadrotors. This approach advances the frontier of vision-based autonomous flight and shows that model-based RL is a promising direction for real-world robotics.
Multi-Task Reinforcement Learning for Quadrotors
Dec 17, 2024Reinforcement learning (RL) has shown great effectiveness in quadrotor control, enabling specialized policies to develop even human-champion-level performance in single-task scenarios. However, these specialized policies often struggle with novel tasks, requiring a complete retraining of the policy from scratch. To address this limitation, this paper presents a novel multi-task reinforcement learning (MTRL) framework tailored for quadrotor control, leveraging the shared physical dynamics of the platform to enhance sample efficiency and task performance. By employing a multi-critic architecture and shared task encoders, our framework facilitates knowledge transfer across tasks, enabling a single policy to execute diverse maneuvers, including high-speed stabilization, velocity tracking, and autonomous racing. Our experimental results, validated both in simulation and real-world scenarios, demonstrate that our framework outperforms baseline approaches in terms of sample efficiency and overall task performance.
Demonstrating Agile Flight from Pixels without State Estimation
Jun 18, 2024


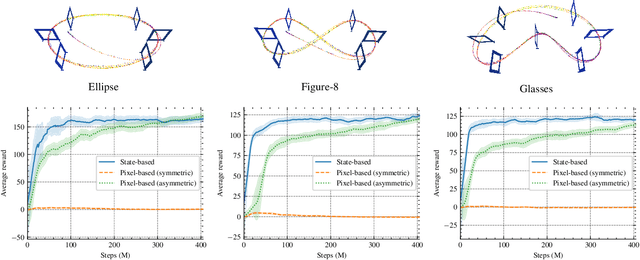
Quadrotors are among the most agile flying robots. Despite recent advances in learning-based control and computer vision, autonomous drones still rely on explicit state estimation. On the other hand, human pilots only rely on a first-person-view video stream from the drone onboard camera to push the platform to its limits and fly robustly in unseen environments. To the best of our knowledge, we present the first vision-based quadrotor system that autonomously navigates through a sequence of gates at high speeds while directly mapping pixels to control commands. Like professional drone-racing pilots, our system does not use explicit state estimation and leverages the same control commands humans use (collective thrust and body rates). We demonstrate agile flight at speeds up to 40km/h with accelerations up to 2g. This is achieved by training vision-based policies with reinforcement learning (RL). The training is facilitated using an asymmetric actor-critic with access to privileged information. To overcome the computational complexity during image-based RL training, we use the inner edges of the gates as a sensor abstraction. This simple yet robust, task-relevant representation can be simulated during training without rendering images. During deployment, a Swin-transformer-based gate detector is used. Our approach enables autonomous agile flight with standard, off-the-shelf hardware. Although our demonstration focuses on drone racing, we believe that our method has an impact beyond drone racing and can serve as a foundation for future research into real-world applications in structured environments.
Learning to Open Doors with an Aerial Manipulator
Jul 28, 2023
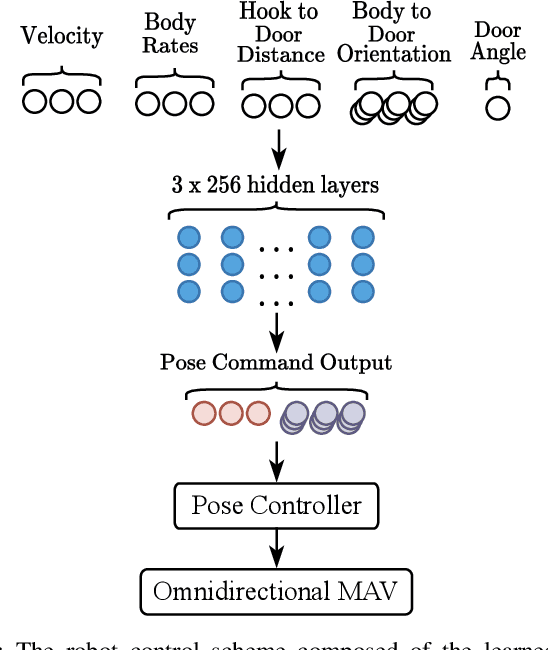
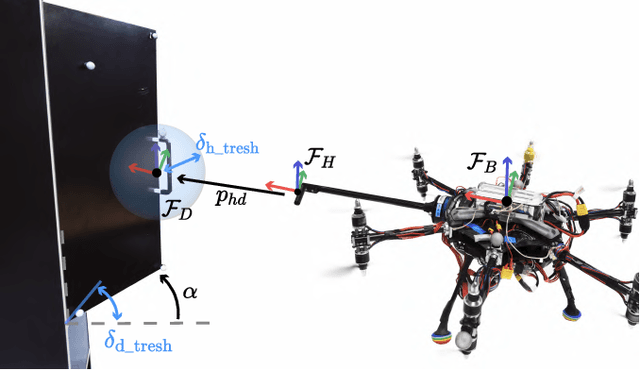
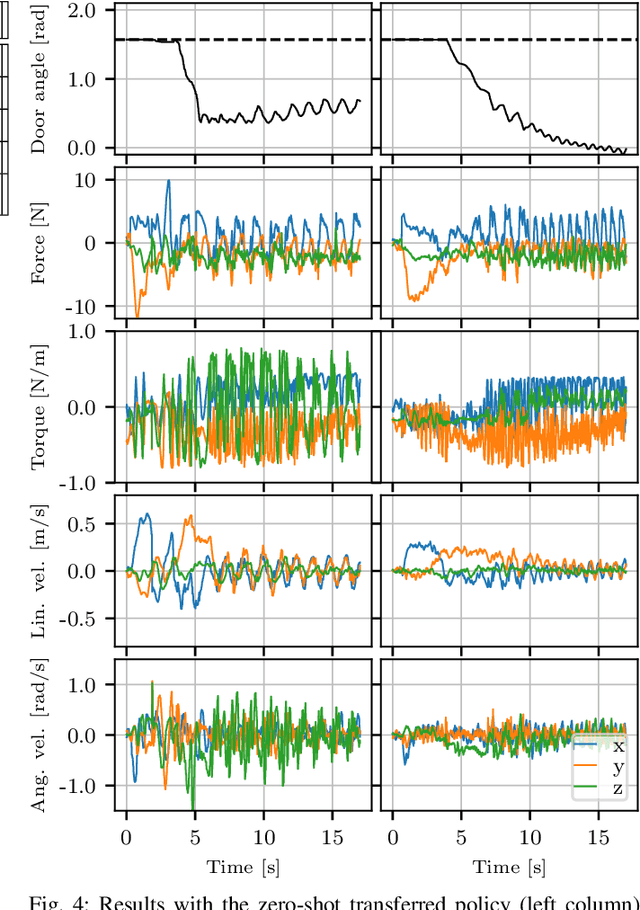
The field of aerial manipulation has seen rapid advances, transitioning from push-and-slide tasks to interaction with articulated objects. So far, when more complex actions are performed, the motion trajectory is usually handcrafted or a result of online optimization methods like Model Predictive Control (MPC) or Model Predictive Path Integral (MPPI) control. However, these methods rely on heuristics or model simplifications to efficiently run on onboard hardware, producing results in acceptable amounts of time. Moreover, they can be sensitive to disturbances and differences between the real environment and its simulated counterpart. In this work, we propose a Reinforcement Learning (RL) approach to learn motion behaviors for a manipulation task while producing policies that are robust to disturbances and modeling errors. Specifically, we train a policy to perform a door-opening task with an Omnidirectional Micro Aerial Vehicle (OMAV). The policy is trained in a physics simulator and experiments are presented both in simulation and running onboard the real platform, investigating the simulation to real world transfer. We compare our method against a state-of-the-art MPPI solution, showing a considerable increase in robustness and speed.
GAFAR: Graph-Attention Feature-Augmentation for Registration A Fast and Light-weight Point Set Registration Algorithm
Jul 05, 2023
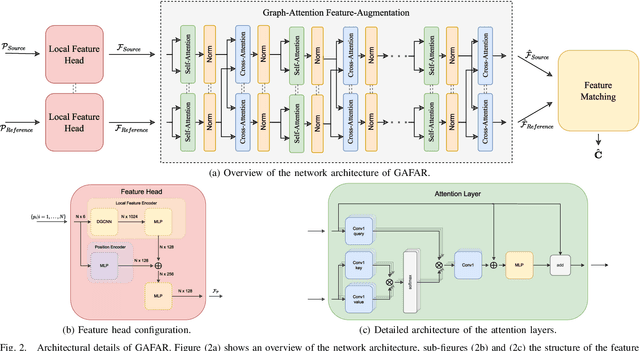
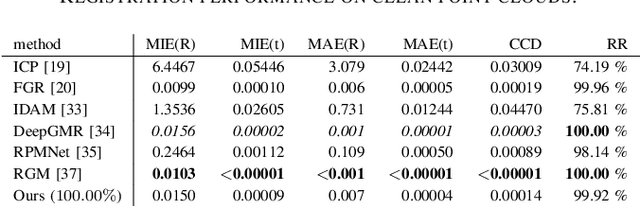
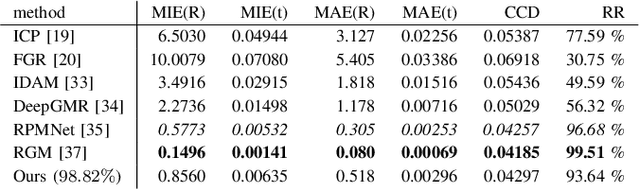
Rigid registration of point clouds is a fundamental problem in computer vision with many applications from 3D scene reconstruction to geometry capture and robotics. If a suitable initial registration is available, conventional methods like ICP and its many variants can provide adequate solutions. In absence of a suitable initialization and in the presence of a high outlier rate or in the case of small overlap though the task of rigid registration still presents great challenges. The advent of deep learning in computer vision has brought new drive to research on this topic, since it provides the possibility to learn expressive feature-representations and provide one-shot estimates instead of depending on time-consuming iterations of conventional robust methods. Yet, the rotation and permutation invariant nature of point clouds poses its own challenges to deep learning, resulting in loss of performance and low generalization capability due to sensitivity to outliers and characteristics of 3D scans not present during network training. In this work, we present a novel fast and light-weight network architecture using the attention mechanism to augment point descriptors at inference time to optimally suit the registration task of the specific point clouds it is presented with. Employing a fully-connected graph both within and between point clouds lets the network reason about the importance and reliability of points for registration, making our approach robust to outliers, low overlap and unseen data. We test the performance of our registration algorithm on different registration and generalization tasks and provide information on runtime and resource consumption. The code and trained weights are available at https://github.com/mordecaimalignatius/GAFAR/.