 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Open Doors with an Aerial Manipulator
Paper and Code
Jul 28, 2023
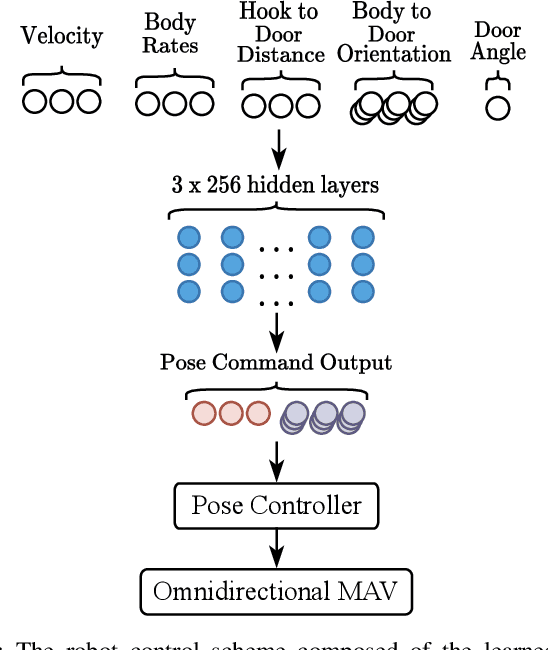
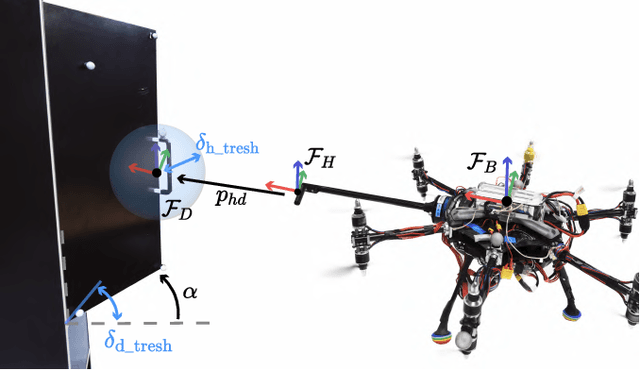
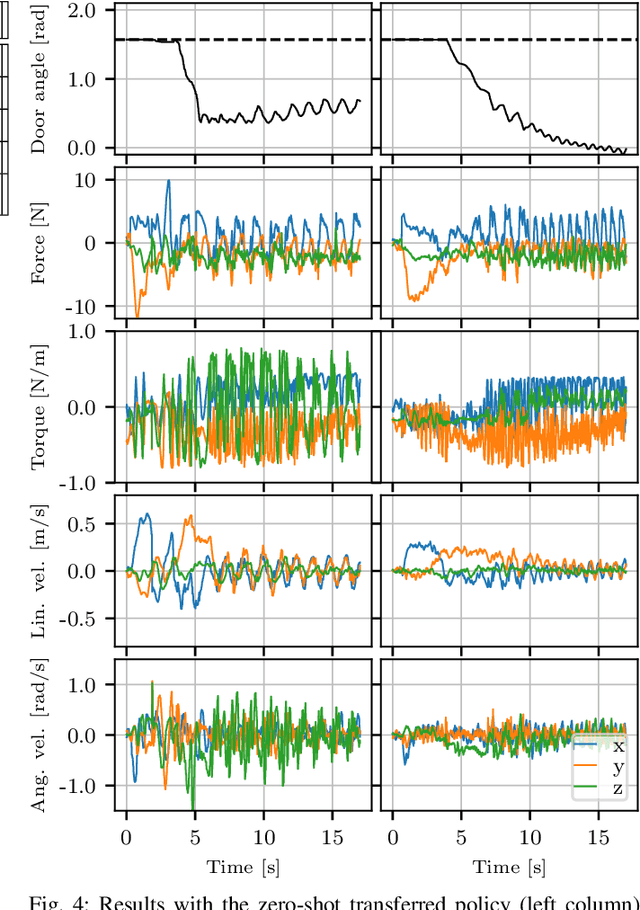
The field of aerial manipulation has seen rapid advances, transitioning from push-and-slide tasks to interaction with articulated objects. So far, when more complex actions are performed, the motion trajectory is usually handcrafted or a result of online optimization methods like Model Predictive Control (MPC) or Model Predictive Path Integral (MPPI) control. However, these methods rely on heuristics or model simplifications to efficiently run on onboard hardware, producing results in acceptable amounts of time. Moreover, they can be sensitive to disturbances and differences between the real environment and its simulated counterpart. In this work, we propose a Reinforcement Learning (RL) approach to learn motion behaviors for a manipulation task while producing policies that are robust to disturbances and modeling errors. Specifically, we train a policy to perform a door-opening task with an Omnidirectional Micro Aerial Vehicle (OMAV). The policy is trained in a physics simulator and experiments are presented both in simulation and running onboard the real platform, investigating the simulation to real world transfer. We compare our method against a state-of-the-art MPPI solution, showing a considerable increase in robustness and speed.