 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAME-2: Agile and Generalized Legged Locomotion via Attention-Based Neural Map Encoding
Jan 13, 2026Achieving agile and generalized legged locomotion across terrains requires tight integration of perception and control, especially under occlusions and sparse footholds. Existing methods have demonstrated agility on parkour courses but often rely on end-to-end sensorimotor models with limited generalization and interpretability. By contrast, methods targeting generalized locomotion typically exhibit limited agility and struggle with visual occlusions. We introduce AME-2, a unified reinforcement learning (RL) framework for agile and generalized locomotion that incorporates a novel attention-based map encoder in the control policy. This encoder extracts local and global mapping features and uses attention mechanisms to focus on salient regions, producing an interpretable and generalized embedding for RL-based control. We further propose a learning-based mapping pipeline that provides fast, uncertainty-aware terrain representations robust to noise and occlusions, serving as policy inputs. It uses neural networks to convert depth observations into local elevations with uncertainties, and fuses them with odometry. The pipeline also integrates with parallel simulation so that we can train controllers with online mapping, aiding sim-to-real transfer. We validate AME-2 with the proposed mapping pipeline on a quadruped and a biped robot, and the resulting controllers demonstrate strong agility and generalization to unseen terrains in simulation and in real-world experiments.
Multi-Domain Motion Embedding: Expressive Real-Time Mimicry for Legged Robots
Dec 08, 2025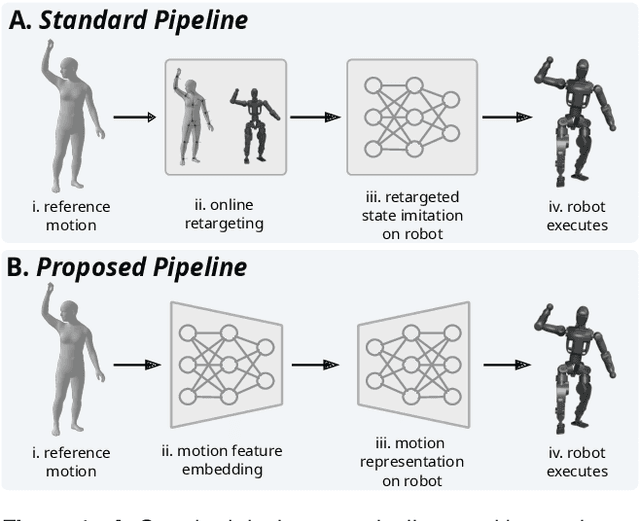

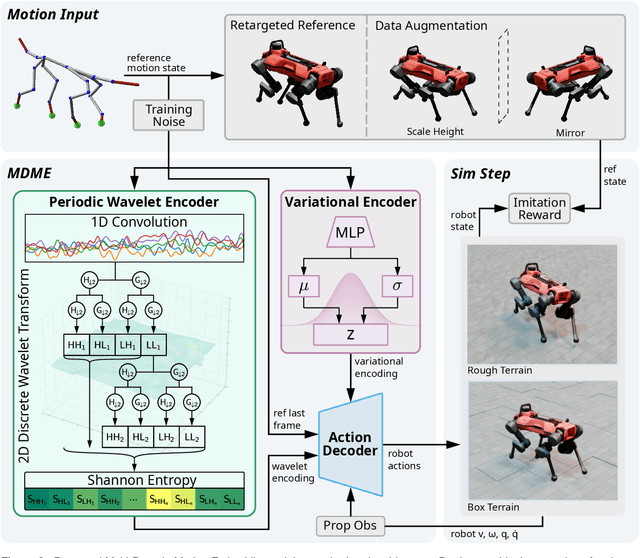

Effective motion representation is crucial for enabling robots to imitate expressive behaviors in real time, yet existing motion controllers often ignore inherent patterns in motion. Previous efforts in representation learning do not attempt to jointly capture structured periodic patterns and irregular variations in human and animal movement. To address this, we present Multi-Domain Motion Embedding (MDME), a motion representation that unifies the embedding of structured and unstructured features using a wavelet-based encoder and a probabilistic embedding in parallel. This produces a rich representation of reference motions from a minimal input set, enabling improved generalization across diverse motion styles and morphologies. We evaluate MDME on retargeting-free real-time motion imitation by conditioning robot control policies on the learned embeddings, demonstrating accurate reproduction of complex trajectories on both humanoid and quadruped platforms. Our comparative studies confirm that MDME outperforms prior approaches in reconstruction fidelity and generalizability to unseen motions. Furthermore, we demonstrate that MDME can reproduce novel motion styles in real-time through zero-shot deployment, eliminating the need for task-specific tuning or online retargeting. These results position MDME as a generalizable and structure-aware foundation for scalable real-time robot imitation.
FOCI: Trajectory Optimization on Gaussian Splats
May 13, 2025



3D Gaussian Splatting (3DGS) has recently gained popularity as a faster alternative to Neural Radiance Fields (NeRFs) in 3D reconstruction and view synthesis methods. Leveraging the spatial information encoded in 3DGS, this work proposes FOCI (Field Overlap Collision Integral), an algorithm that is able to optimize trajectories directly on the Gaussians themselves. FOCI leverages a novel and interpretable collision formulation for 3DGS using the notion of the overlap integral between Gaussians. Contrary to other approaches, which represent the robot with conservative bounding boxes that underestimate the traversability of the environment, we propose to represent the environment and the robot as Gaussian Splats. This not only has desirable computational properties, but also allows for orientation-aware planning, allowing the robot to pass through very tight and narrow spaces. We extensively test our algorithm in both synthetic and real Gaussian Splats, showcasing that collision-free trajectories for the ANYmal legged robot that can be computed in a few seconds, even with hundreds of thousands of Gaussians making up the environment. The project page and code are available at https://rffr.leggedrobotics.com/works/foci/
LEVA: A high-mobility logistic vehicle with legged suspension
Mar 13, 2025The autonomous transportation of materials over challenging terrain is a challenge with major economic implications and remains unsolved. This paper introduces LEVA, a high-payload, high-mobility robot designed for autonomous logistics across varied terrains, including those typical in agriculture, construction, and search and rescue operations. LEVA uniquely integrates an advanced legged suspension system using parallel kinematics. It is capable of traversing stairs using a rl controller, has steerable wheels, and includes a specialized box pickup mechanism that enables autonomous payload loading as well as precise and reliable cargo transportation of up to 85 kg across uneven surfaces, steps and inclines while maintaining a cot of as low as 0.15. Through extensive experimental validation, LEVA demonstrates its off-road capabilities and reliability regarding payload loading and transport.
DiffSim2Real: Deploying Quadrupedal Locomotion Policies Purely Trained in Differentiable Simulation
Nov 04, 2024
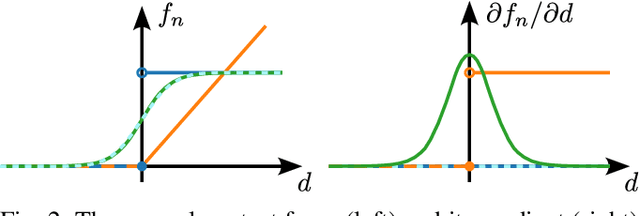

Differentiable simulators provide analytic gradients, enabling more sample-efficient learning algorithms and paving the way for data intensive learning tasks such as learning from images. In this work, we demonstrate that locomotion policies trained with analytic gradients from a differentiable simulator can be successfully transferred to the real world. Typically, simulators that offer informative gradients lack the physical accuracy needed for sim-to-real transfer, and vice-versa. A key factor in our success is a smooth contact model that combines informative gradients with physical accuracy, ensuring effective transfer of learned behaviors. To the best of our knowledge, this is the first time a real quadrupedal robot is able to locomote after training exclusively in a differentiable simulation.
Residual Policy Learning for Perceptive Quadruped Control Using Differentiable Simulation
Oct 04, 2024



First-order Policy Gradient (FoPG) algorithms such as Backpropagation through Time and Analytical Policy Gradients leverage local simulation physics to accelerate policy search, significantly improving sample efficiency in robot control compared to standard model-free reinforcement learning. However, FoPG algorithms can exhibit poor learning dynamics in contact-rich tasks like locomotion. Previous approaches address this issue by alleviating contact dynamics via algorithmic or simulation innovations. In contrast, we propose guiding the policy search by learning a residual over a simple baseline policy. For quadruped locomotion, we find that the role of residual policy learning in FoPG-based training (FoPG RPL) is primarily to improve asymptotic rewards, compared to improving sample efficiency for model-free RL. Additionally, we provide insights on applying FoPG's to pixel-based local navigation, training a point-mass robot to convergence within seconds. Finally, we showcase the versatility of FoPG RPL by using it to train locomotion and perceptive navigation end-to-end on a quadruped in minutes.
Dataset and Lessons Learned from the 2024 SaTML LLM Capture-the-Flag Competition
Jun 12, 2024



Large language model systems face important security risks from maliciously crafted messages that aim to overwrite the system's original instructions or leak private data. To study this problem, we organized a capture-the-flag competition at IEEE SaTML 2024, where the flag is a secret string in the LLM system prompt. The competition was organized in two phases. In the first phase, teams developed defenses to prevent the model from leaking the secret. During the second phase, teams were challenged to extract the secrets hidden for defenses proposed by the other teams. This report summarizes the main insights from the competition. Notably, we found that all defenses were bypassed at least once, highlighting the difficulty of designing a successful defense and the necessity for additional research to protect LLM systems. To foster future research in this direction, we compiled a dataset with over 137k multi-turn attack chats and open-sourced the platform.
Learning Quadrupedal Locomotion via Differentiable Simulation
Apr 03, 2024



The emergence of differentiable simulators enabling analytic gradient computation has motivated a new wave of learning algorithms that hold the potential to significantly increase sample efficiency over traditional Reinforcement Learning (RL) methods. While recent research has demonstrated performance gains in scenarios with comparatively smooth dynamics and, thus, smooth optimization landscapes, research on leveraging differentiable simulators for contact-rich scenarios, such as legged locomotion, is scarce. This may be attributed to the discontinuous nature of contact, which introduces several challenges to optimizing with analytic gradients. The purpose of this paper is to determine if analytic gradients can be beneficial even in the face of contact. Our investigation focuses on the effects of different soft and hard contact models on the learning process, examining optimization challenges through the lens of contact simulation. We demonstrate the viability of employing analytic gradients to learn physically plausible locomotion skills with a quadrupedal robot using Short-Horizon Actor-Critic (SHAC), a learning algorithm leveraging analytic gradients, and draw a comparison to a state-of-the-art RL algorithm, Proximal Policy Optimization (PPO), to understand the benefits of analytic gradients.
Symmetry Considerations for Learning Task Symmetric Robot Policies
Mar 07, 2024



Symmetry is a fundamental aspect of many real-world robotic tasks. However, current deep reinforcement learning (DRL) approaches can seldom harness and exploit symmetry effectively. Often, the learned behaviors fail to achieve the desired transformation invariances and suffer from motion artifacts. For instance, a quadruped may exhibit different gaits when commanded to move forward or backward, even though it is symmetrical about its torso. This issue becomes further pronounced in high-dimensional or complex environments, where DRL methods are prone to local optima and fail to explore regions of the state space equally. Past methods on encouraging symmetry for robotic tasks have studied this topic mainly in a single-task setting, where symmetry usually refers to symmetry in the motion, such as the gait patterns. In this paper, we revisit this topic for goal-conditioned tasks in robotics, where symmetry lies mainly in task execution and not necessarily in the learned motions themselves. In particular, we investigate two approaches to incorporate symmetry invariance into DRL -- data augmentation and mirror loss function. We provide a theoretical foundation for using augmented samples in an on-policy setting. Based on this, we show that the corresponding approach achieves faster convergence and improves the learned behaviors in various challenging robotic tasks, from climbing boxes with a quadruped to dexterous manipulation.
Reinforcement Learning for Blind Stair Climbing with Legged and Wheeled-Legged Robots
Feb 09, 2024
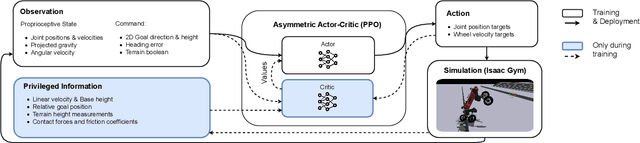


In recent years, legged and wheeled-legged robots have gained prominence for tasks in environments predominantly created for humans across various domains. One significant challenge faced by many of these robots is their limited capability to navigate stairs, which hampers their functionality in multi-story environments. This study proposes a method aimed at addressing this limitation, employing reinforcement learning to develop a versatile controller applicable to a wide range of robots. In contrast to the conventional velocity-based controllers, our approach builds upon a position-based formulation of the RL task, which we show to be vital for stair climbing. Furthermore, the methodology leverages an asymmetric actor-critic structure, enabling the utilization of privileged information from simulated environments during training while eliminating the reliance on exteroceptive sensors during real-world deployment. Another key feature of the proposed approach is the incorporation of a boolean observation within the controller, enabling the activation or deactivation of a stair-climbing mode. We present our results on different quadrupeds and bipedal robots in simulation and showcase how our method allows the balancing robot Ascento to climb 15cm stairs in the real world, a task that was previously impossible for this robot.