 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKPIs 2024 Challenge: Advancing Glomerular Segmentation from Patch- to Slide-Level
Feb 11, 2025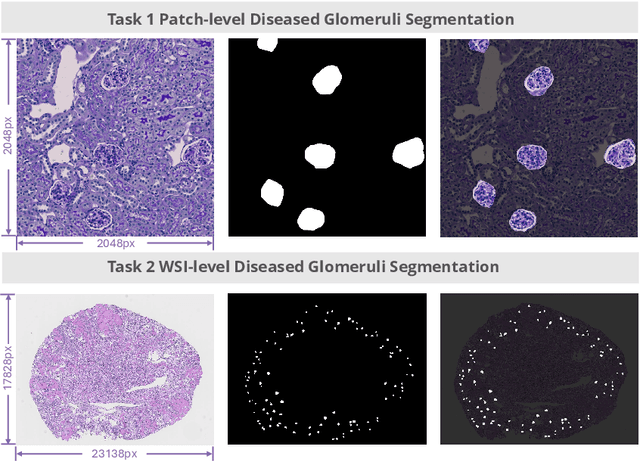

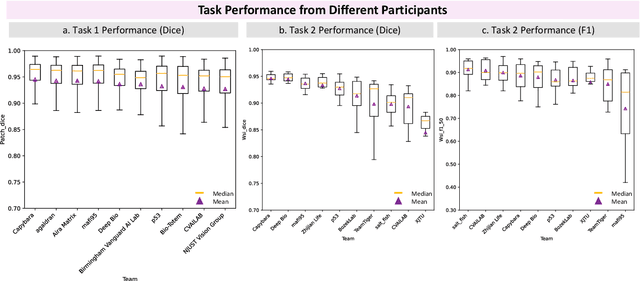

Chronic kidney disease (CKD) is a major global health issue, affecting over 10% of the population and causing significant mortality. While kidney biopsy remains the gold standard for CKD diagnosis and treatment, the lack of comprehensive benchmarks for kidney pathology segmentation hinders progress in the field. To address this, we organized the Kidney Pathology Image Segmentation (KPIs) Challenge, introducing a dataset that incorporates preclinical rodent models of CKD with over 10,000 annotated glomeruli from 60+ Periodic Acid Schiff (PAS)-stained whole slide images. The challenge includes two tasks, patch-level segmentation and whole slide image segmentation and detection, evaluated using the Dice Similarity Coefficient (DSC) and F1-score. By encouraging innovative segmentation methods that adapt to diverse CKD models and tissue conditions, the KPIs Challenge aims to advance kidney pathology analysis, establish new benchmarks, and enable precise, large-scale quantification for disease research and diagnosis.
Predicting the risk of early-stage breast cancer recurrence using H\&E-stained tissue images
Jun 10, 2024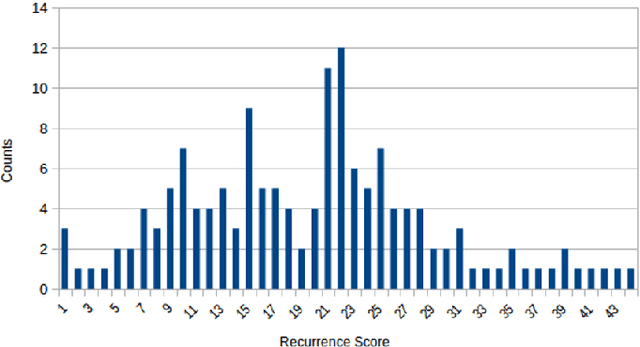
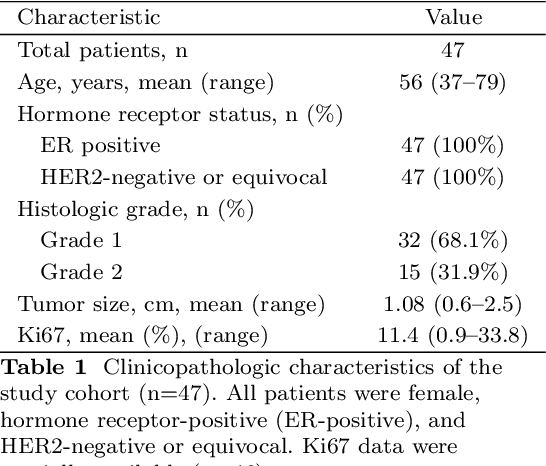
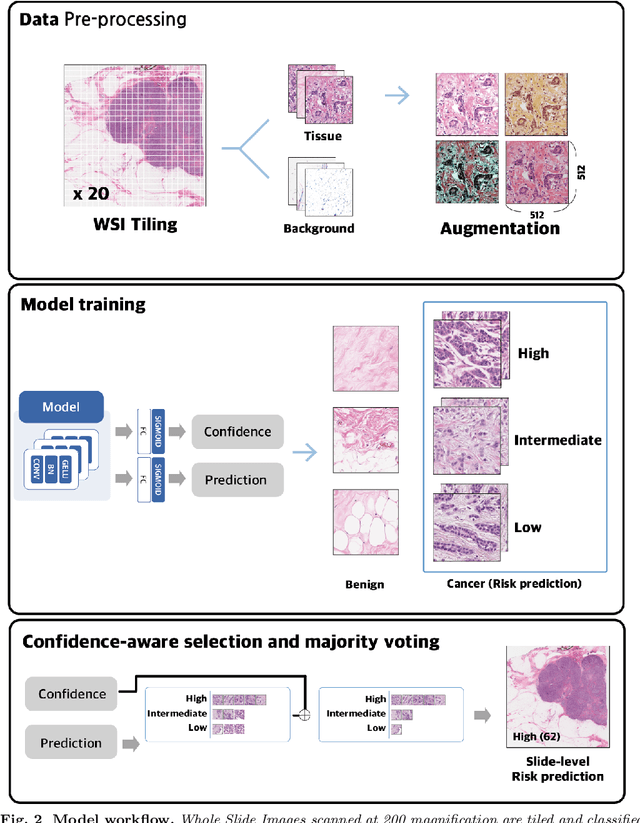
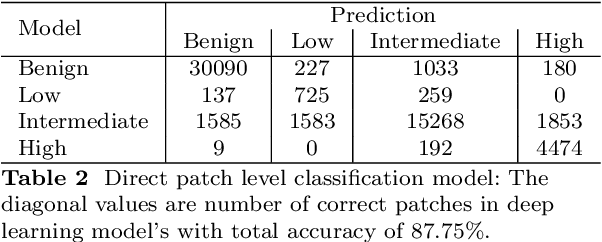
Accurate prediction of the likelihood of recurrence is important in the selection of postoperative treatment for patients with early-stage breast cancer. In this study, we investigated whether deep learning algorithms can predict patients' risk of recurrence by analyzing the pathology images of their cancer histology. A total of 125 hematoxylin and eosin stained breast cancer whole slide images labeled with the risk prediction via genomics assays were used, and we obtained sensitivity of 0.857, 0.746, and 0.529 for predicting low, intermediate, and high risk, and specificity of 0.816, 0.803, and 0.972. When compared to the expert pathologist's regional histology grade information, a Pearson's correlation coefficient of 0.61 was obtained. When we checked the model learned through these studies through the class activation map, we found that it actually considered tubule formation and mitotic rate when predicting different risk groups.
Learning-based legged locomotion; state of the art and future perspectives
Jun 03, 2024Legged locomotion holds the premise of universal mobility, a critical capability for many real-world robotic applications. Both model-based and learning-based approaches have advanced the field of legged locomotion in the past three decades. In recent years, however, a number of factors have dramatically accelerated progress in learning-based methods, including the rise of deep learning, rapid progress in simulating robotic systems, and the availability of high-performance and affordable hardware. This article aims to give a brief history of the field, to summarize recent efforts in learning locomotion skills for quadrupeds, and to provide researchers new to the area with an understanding of the key issues involved. With the recent proliferation of humanoid robots, we further outline the rapid rise of analogous methods for bipedal locomotion. We conclude with a discussion of open problems as well as related societal impact.
Rethinking Robustness Assessment: Adversarial Attacks on Learning-based Quadrupedal Locomotion Controllers
May 21, 2024
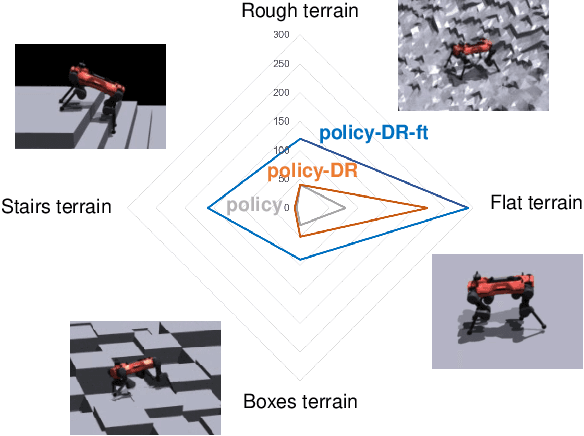


Legged locomotion has recently achieved remarkable success with the progress of machine learning techniques, especially deep reinforcement learning (RL). Controllers employing neural networks have demonstrated empirical and qualitative robustness against real-world uncertainties, including sensor noise and external perturbations. However, formally investigating the vulnerabilities of these locomotion controllers remains a challenge. This difficulty arises from the requirement to pinpoint vulnerabilities across a long-tailed distribution within a high-dimensional, temporally sequential space. As a first step towards quantitative verification, we propose a computational method that leverages sequential adversarial attacks to identify weaknesses in learned locomotion controllers. Our research demonstrates that, even state-of-the-art robust controllers can fail significantly under well-designed, low-magnitude adversarial sequence. Through experiments in simulation and on the real robot, we validate our approach's effectiveness, and we illustrate how the results it generates can be used to robustify the original policy and offer valuable insights into the safety of these black-box policies.
Learning Robust Autonomous Navigation and Locomotion for Wheeled-Legged Robots
May 03, 2024Autonomous wheeled-legged robots have the potential to transform logistics systems, improving operational efficiency and adaptability in urban environments. Navigating urban environments, however, poses unique challenges for robots, necessitating innovative solutions for locomotion and navigation. These challenges include the need for adaptive locomotion across varied terrains and the ability to navigate efficiently around complex dynamic obstacles. This work introduces a fully integrated system comprising adaptive locomotion control, mobility-aware local navigation planning, and large-scale path planning within the city. Using model-free reinforcement learning (RL) techniques and privileged learning, we develop a versatile locomotion controller. This controller achieves efficient and robust locomotion over various rough terrains, facilitated by smooth transitions between walking and driving modes. It is tightly integrated with a learned navigation controller through a hierarchical RL framework, enabling effective navigation through challenging terrain and various obstacles at high speed. Our controllers are integrated into a large-scale urban navigation system and validated by autonomous, kilometer-scale navigation missions conducted in Zurich, Switzerland, and Seville, Spain. These missions demonstrate the system's robustness and adaptability, underscoring the importance of integrated control systems in achieving seamless navigation in complex environments. Our findings support the feasibility of wheeled-legged robots and hierarchical RL for autonomous navigation, with implications for last-mile delivery and beyond.
Learning to walk in confined spaces using 3D representation
Feb 29, 2024
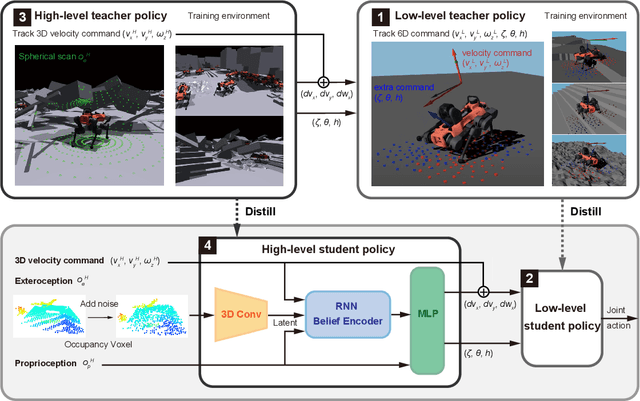
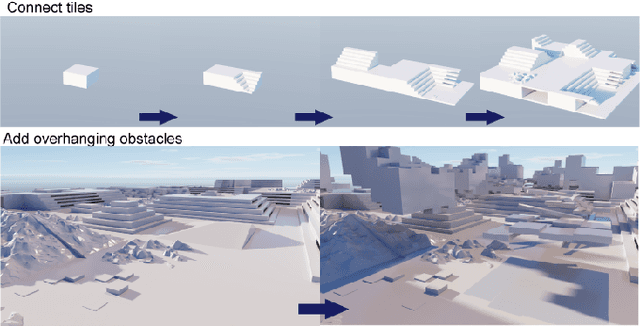
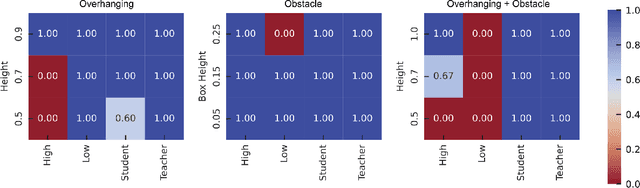
Legged robots have the potential to traverse complex terrain and access confined spaces beyond the reach of traditional platforms thanks to their ability to carefully select footholds and flexibly adapt their body posture while walking. However, robust deployment in real-world applications is still an open challenge. In this paper, we present a method for legged locomotion control using reinforcement learning and 3D volumetric representations to enable robust and versatile locomotion in confined and unstructured environments. By employing a two-layer hierarchical policy structure, we exploit the capabilities of a highly robust low-level policy to follow 6D commands and a high-level policy to enable three-dimensional spatial awareness for navigating under overhanging obstacles. Our study includes the development of a procedural terrain generator to create diverse training environments. We present a series of experimental evaluations in both simulation and real-world settings, demonstrating the effectiveness of our approach in controlling a quadruped robot in confined, rough terrain. By achieving this, our work extends the applicability of legged robots to a broader range of scenarios.
Solving Multi-Entity Robotic Problems Using Permutation Invariant Neural Networks
Feb 28, 2024Challenges in real-world robotic applications often stem from managing multiple, dynamically varying entities such as neighboring robots, manipulable objects, and navigation goals. Existing multi-agent control strategies face scalability limitations, struggling to handle arbitrary numbers of entities. Additionally, they often rely on engineered heuristics for assigning entities among agents. We propose a data driven approach to address these limitations by introducing a decentralized control system using neural network policies trained in simulation. Leveraging permutation invariant neural network architectures and model-free reinforcement learning, our approach allows control agents to autonomously determine the relative importance of different entities without being biased by ordering or limited by a fixed capacity. We validate our approach through both simulations and real-world experiments involving multiple wheeled-legged quadrupedal robots, demonstrating their collaborative control capabilities. We prove the effectiveness of our architectural choice through experiments with three exemplary multi-entity problems. Our analysis underscores the pivotal role of the end-to-end trained permutation invariant encoders in achieving scalability and improving the task performance in multi-object manipulation or multi-goal navigation problems. The adaptability of our policy is further evidenced by its ability to manage varying numbers of entities in a zero-shot manner, showcasing near-optimal autonomous task distribution and collision avoidance behaviors.
Evaluation of Constrained Reinforcement Learning Algorithms for Legged Locomotion
Sep 27, 2023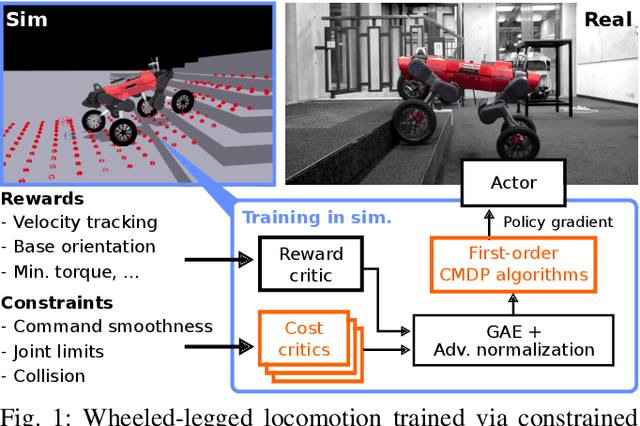
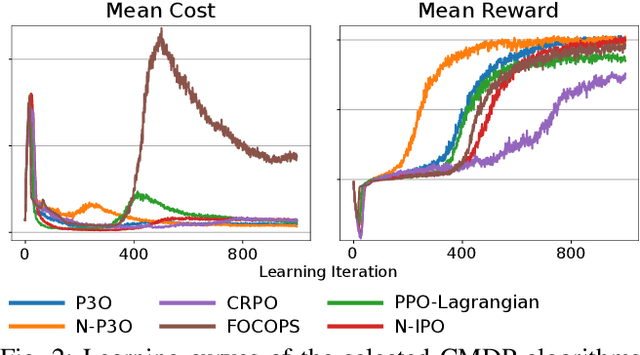
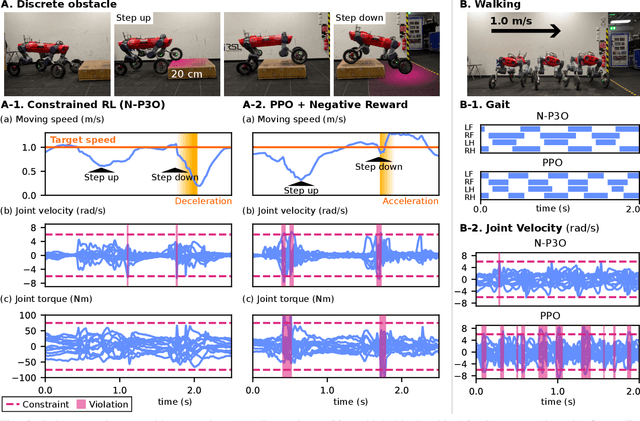
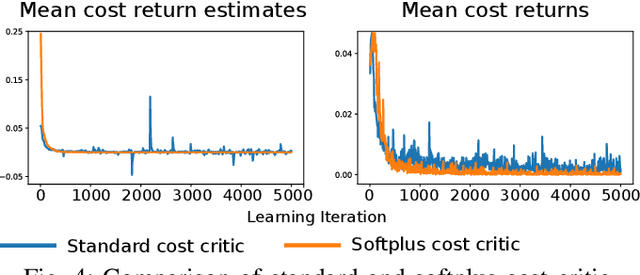
Shifting from traditional control strategies to Deep Reinforcement Learning (RL) for legged robots poses inherent challenges, especially when addressing real-world physical constraints during training. While high-fidelity simulations provide significant benefits, they often bypass these essential physical limitations. In this paper, we experiment with the Constrained Markov Decision Process (CMDP) framework instead of the conventional unconstrained RL for robotic applications. We perform a comparative study of different constrained policy optimization algorithms to identify suitable methods for practical implementation. Our robot experiments demonstrate the critical role of incorporating physical constraints, yielding successful sim-to-real transfers, and reducing operational errors on physical systems. The CMDP formulation streamlines the training process by separately handling constraints from rewards. Our findings underscore the potential of constrained RL for the effective development and deployment of learned controllers in robotics.
Seeing Through the Grass: Semantic Pointcloud Filter for Support Surface Learning
May 13, 2023Mobile ground robots require perceiving and understanding their surrounding support surface to move around autonomously and safely. The support surface is commonly estimated based on exteroceptive depth measurements, e.g., from LiDARs. However, the measured depth fails to align with the true support surface in the presence of high grass or other penetrable vegetation. In this work, we present the Semantic Pointcloud Filter (SPF), a Convolutional Neural Network (CNN) that learns to adjust LiDAR measurements to align with the underlying support surface. The SPF is trained in a semi-self-supervised manner and takes as an input a LiDAR pointcloud and RGB image. The network predicts a binary segmentation mask that identifies the specific points requiring adjustment, along with estimating their corresponding depth values. To train the segmentation task, 300 distinct images are manually labeled into rigid and non-rigid terrain. The depth estimation task is trained in a self-supervised manner by utilizing the future footholds of the robot to estimate the support surface based on a Gaussian process. Our method can correctly adjust the support surface prior to interacting with the terrain and is extensively tested on the quadruped robot ANYmal. We show the qualitative benefits of SPF in natural environments for elevation mapping and traversability estimation compared to using raw sensor measurements and existing smoothing methods. Quantitative analysis is performed in various natural environments, and an improvement by 48% RMSE is achieved within a meadow terrain.
Learning-based Design and Control for Quadrupedal Robots with Parallel-Elastic Actuators
Jan 09, 2023



Parallel-elastic joints can improve the efficiency and strength of robots by assisting the actuators with additional torques. For these benefits to be realized, a spring needs to be carefully designed. However, designing robots is an iterative and tedious process, often relying on intuition and heuristics. We introduce a design optimization framework that allows us to co-optimize a parallel elastic knee joint and locomotion controller for quadrupedal robots with minimal human intuition. We design a parallel elastic joint and optimize its parameters with respect to the efficiency in a model-free fashion. In the first step, we train a design-conditioned policy using model-free Reinforcement Learning, capable of controlling the quadruped in the predefined range of design parameters. Afterwards, we use Bayesian Optimization to find the best design using the policy. We use this framework to optimize the parallel-elastic spring parameters for the knee of our quadrupedal robot ANYmal together with the optimal controller. We evaluate the optimized design and controller in real-world experiments over various terrains. Our results show that the new system improves the torque-square efficiency of the robot by 33% compared to the baseline and reduces maximum joint torque by 30% without compromising tracking performance. The improved design resulted in 11% longer operation time on flat terrain.