 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Loco-Manipulation for Pick-and-Place Tasks with Dynamic Reward Curriculum
Sep 16, 2025We present a hierarchical RL pipeline for training one-armed legged robots to perform pick-and-place (P&P) tasks end-to-end -- from approaching the payload to releasing it at a target area -- in both single-robot and cooperative dual-robot settings. We introduce a novel dynamic reward curriculum that enables a single policy to efficiently learn long-horizon P&P operations by progressively guiding the agents through payload-centered sub-objectives. Compared to state-of-the-art approaches for long-horizon RL tasks, our method improves training efficiency by 55% and reduces execution time by 18.6% in simulation experiments. In the dual-robot case, we show that our policy enables each robot to attend to different components of its observation space at distinct task stages, promoting effective coordination via autonomous attention shifts. We validate our method through real-world experiments using ANYmal D platforms in both single- and dual-robot scenarios. To our knowledge, this is the first RL pipeline that tackles the full scope of collaborative P&P with two legged manipulators.
Solving Multi-Entity Robotic Problems Using Permutation Invariant Neural Networks
Feb 28, 2024Challenges in real-world robotic applications often stem from managing multiple, dynamically varying entities such as neighboring robots, manipulable objects, and navigation goals. Existing multi-agent control strategies face scalability limitations, struggling to handle arbitrary numbers of entities. Additionally, they often rely on engineered heuristics for assigning entities among agents. We propose a data driven approach to address these limitations by introducing a decentralized control system using neural network policies trained in simulation. Leveraging permutation invariant neural network architectures and model-free reinforcement learning, our approach allows control agents to autonomously determine the relative importance of different entities without being biased by ordering or limited by a fixed capacity. We validate our approach through both simulations and real-world experiments involving multiple wheeled-legged quadrupedal robots, demonstrating their collaborative control capabilities. We prove the effectiveness of our architectural choice through experiments with three exemplary multi-entity problems. Our analysis underscores the pivotal role of the end-to-end trained permutation invariant encoders in achieving scalability and improving the task performance in multi-object manipulation or multi-goal navigation problems. The adaptability of our policy is further evidenced by its ability to manage varying numbers of entities in a zero-shot manner, showcasing near-optimal autonomous task distribution and collision avoidance behaviors.
Nonlinear Model Predictive Control for Quadrupedal Locomotion Using Second-Order Sensitivity Analysis
Jul 21, 2022
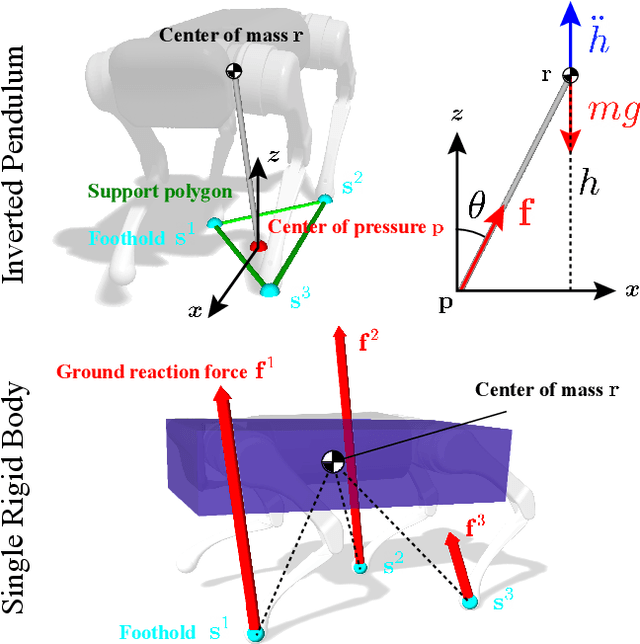

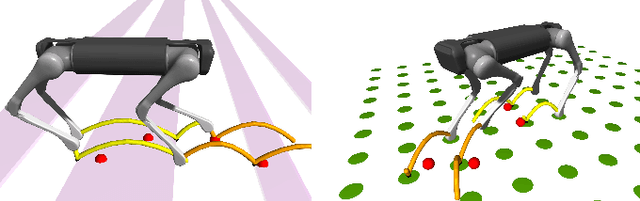
We present a versatile nonlinear model predictive control (NMPC) formulation for quadrupedal locomotion. Our formulation jointly optimizes a base trajectory and a set of footholds over a finite time horizon based on simplified dynamics models. We leverage second-order sensitivity analysis and a sparse Gauss-Newton (SGN) method to solve the resulting optimal control problems. We further describe our ongoing effort to verify our approach through simulation and hardware experiments. Finally, we extend our locomotion framework to deal with challenging tasks that comprise gap crossing, movement on stepping stones, and multi-robot control.