 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Robots Like Dogs: Learning Agile Navigation from Luring, Gesture, and Speech
Jan 13, 2026In this work, we aim to enable legged robots to learn how to interpret human social cues and produce appropriate behaviors through physical human guidance. However, learning through physical engagement can place a heavy burden on users when the process requires large amounts of human-provided data. To address this, we propose a human-in-the-loop framework that enables robots to acquire navigational behaviors in a data-efficient manner and to be controlled via multimodal natural human inputs, specifically gestural and verbal commands. We reconstruct interaction scenes using a physics-based simulation and aggregate data to mitigate distributional shifts arising from limited demonstration data. Our progressive goal cueing strategy adaptively feeds appropriate commands and navigation goals during training, leading to more accurate navigation and stronger alignment between human input and robot behavior. We evaluate our framework across six real-world agile navigation scenarios, including jumping over or avoiding obstacles. Our experimental results show that our proposed method succeeds in almost all trials across these scenarios, achieving a 97.15% task success rate with less than 1 hour of demonstration data in total.
Multi-Domain Motion Embedding: Expressive Real-Time Mimicry for Legged Robots
Dec 08, 2025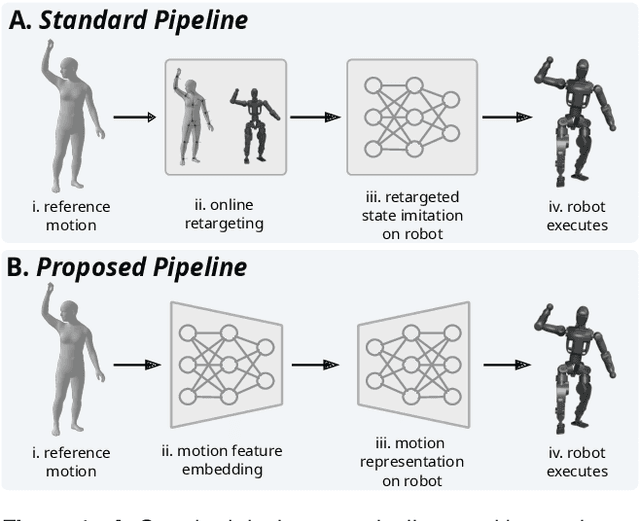

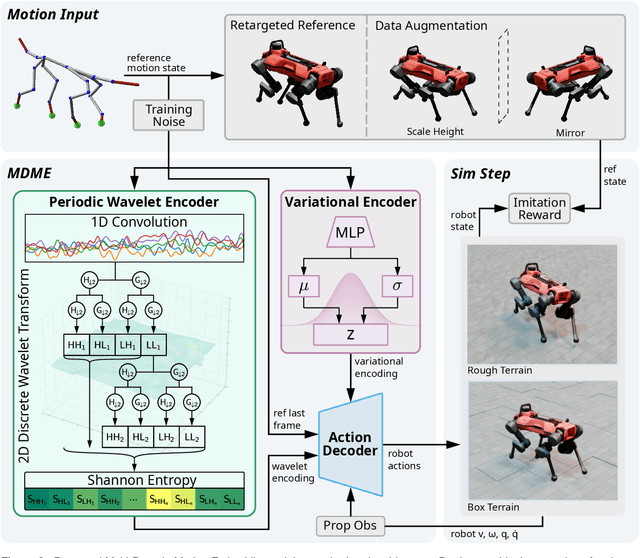

Effective motion representation is crucial for enabling robots to imitate expressive behaviors in real time, yet existing motion controllers often ignore inherent patterns in motion. Previous efforts in representation learning do not attempt to jointly capture structured periodic patterns and irregular variations in human and animal movement. To address this, we present Multi-Domain Motion Embedding (MDME), a motion representation that unifies the embedding of structured and unstructured features using a wavelet-based encoder and a probabilistic embedding in parallel. This produces a rich representation of reference motions from a minimal input set, enabling improved generalization across diverse motion styles and morphologies. We evaluate MDME on retargeting-free real-time motion imitation by conditioning robot control policies on the learned embeddings, demonstrating accurate reproduction of complex trajectories on both humanoid and quadruped platforms. Our comparative studies confirm that MDME outperforms prior approaches in reconstruction fidelity and generalizability to unseen motions. Furthermore, we demonstrate that MDME can reproduce novel motion styles in real-time through zero-shot deployment, eliminating the need for task-specific tuning or online retargeting. These results position MDME as a generalizable and structure-aware foundation for scalable real-time robot imitation.
RAMBO: RL-augmented Model-based Optimal Control for Whole-body Loco-manipulation
Apr 09, 2025
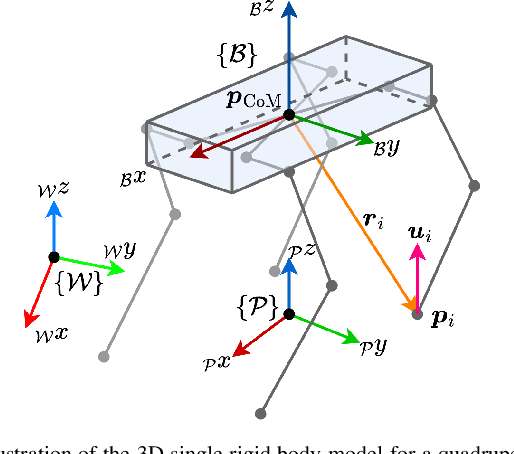
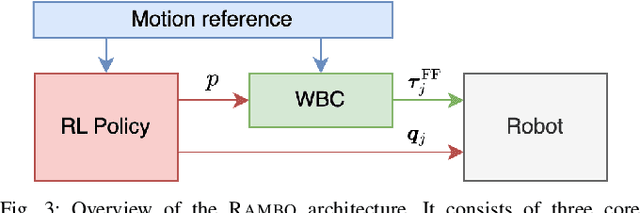

Loco-manipulation -- coordinated locomotion and physical interaction with objects -- remains a major challenge for legged robots due to the need for both accurate force interaction and robustness to unmodeled dynamics. While model-based controllers provide interpretable dynamics-level planning and optimization, they are limited by model inaccuracies and computational cost. In contrast, learning-based methods offer robustness while struggling with precise modulation of interaction forces. We introduce RAMBO -- RL-Augmented Model-Based Optimal Control -- a hybrid framework that integrates model-based reaction force optimization using a simplified dynamics model and a feedback policy trained with reinforcement learning. The model-based module generates feedforward torques by solving a quadratic program, while the policy provides feedback residuals to enhance robustness in control execution. We validate our framework on a quadruped robot across a diverse set of real-world loco-manipulation tasks -- such as pushing a shopping cart, balancing a plate, and holding soft objects -- in both quadrupedal and bipedal walking. Our experiments demonstrate that RAMBO enables precise manipulation while achieving robust and dynamic locomotion, surpassing the performance of policies trained with end-to-end scheme. In addition, our method enables flexible trade-off between end-effector tracking accuracy with compliance.
RobotKeyframing: Learning Locomotion with High-Level Objectives via Mixture of Dense and Sparse Rewards
Jul 16, 2024



This paper presents a novel learning-based control framework that uses keyframing to incorporate high-level objectives in natural locomotion for legged robots. These high-level objectives are specified as a variable number of partial or complete pose targets that are spaced arbitrarily in time. Our proposed framework utilizes a multi-critic reinforcement learning algorithm to effectively handle the mixture of dense and sparse rewards. Additionally, it employs a transformer-based encoder to accommodate a variable number of input targets, each associated with specific time-to-arrivals. Throughout simulation and hardware experiments, we demonstrate that our framework can effectively satisfy the target keyframe sequence at the required times. In the experiments, the multi-critic method significantly reduces the effort of hyperparameter tuning compared to the standard single-critic alternative. Moreover, the proposed transformer-based architecture enables robots to anticipate future goals, which results in quantitative improvements in their ability to reach their targets.
Spatio-Temporal Motion Retargeting for Quadruped Robots
Apr 17, 2024This work introduces a motion retargeting approach for legged robots, which aims to create motion controllers that imitate the fine behavior of animals. Our approach, namely spatio-temporal motion retargeting (STMR), guides imitation learning procedures by transferring motion from source to target, effectively bridging the morphological disparities by ensuring the feasibility of imitation on the target system. Our STMR method comprises two components: spatial motion retargeting (SMR) and temporal motion retargeting (TMR). On the one hand, SMR tackles motion retargeting at the kinematic level by generating kinematically feasible whole-body motions from keypoint trajectories. On the other hand, TMR aims to retarget motion at the dynamic level by optimizing motion in the temporal domain. We showcase the effectiveness of our method in facilitating Imitation Learning (IL) for complex animal movements through a series of simulation and hardware experiments. In these experiments, our STMR method successfully tailored complex animal motions from various media, including video captured by a hand-held camera, to fit the morphology and physical properties of the target robots. This enabled RL policy training for precise motion tracking, while baseline methods struggled with highly dynamic motion involving flying phases. Moreover, we validated that the control policy can successfully imitate six different motions in two quadruped robots with different dimensions and physical properties in real-world settings.
Tuning Legged Locomotion Controllers via Safe Bayesian Optimization
Jun 12, 2023In this paper, we present a data-driven strategy to simplify the deployment of model-based controllers in legged robotic hardware platforms. Our approach leverages a model-free safe learning algorithm to automate the tuning of control gains, addressing the mismatch between the simplified model used in the control formulation and the real system. This method substantially mitigates the risk of hazardous interactions with the robot by sample-efficiently optimizing parameters within a probably safe region. Additionally, we extend the applicability of our approach to incorporate the different gait parameters as contexts, leading to a safe, sample-efficient exploration algorithm capable of tuning a motion controller for diverse gait patterns. We validate our method through simulation and hardware experiments, where we demonstrate that the algorithm obtains superior performance on tuning a model-based motion controller for multiple gaits safely.
RL + Model-based Control: Using On-demand Optimal Control to Learn Versatile Legged Locomotion
May 29, 2023This letter presents a versatile control method for dynamic and robust legged locomotion that integrates model-based optimal control with reinforcement learning (RL). Our approach involves training an RL policy to imitate reference motions generated on-demand through solving a finite-horizon optimal control problem. This integration enables the policy to leverage human expertise in generating motions to imitate while also allowing it to generalize to more complex scenarios that require a more complex dynamics model. Our method successfully learns control policies capable of generating diverse quadrupedal gait patterns and maintaining stability against unexpected external perturbations in both simulation and hardware experiments. Furthermore, we demonstrate the adaptability of our method to more complex locomotion tasks on uneven terrain without the need for excessive reward shaping or hyperparameter tuning.
Nonlinear Model Predictive Control for Quadrupedal Locomotion Using Second-Order Sensitivity Analysis
Jul 21, 2022
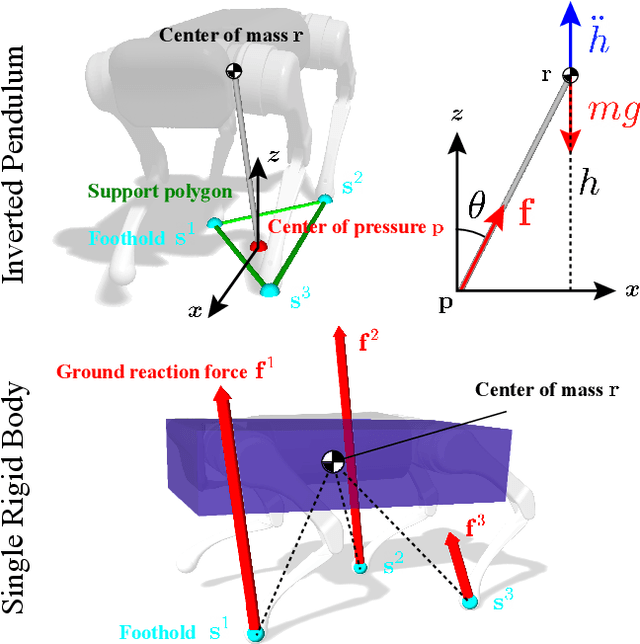

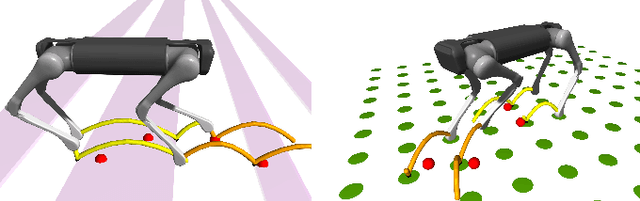
We present a versatile nonlinear model predictive control (NMPC) formulation for quadrupedal locomotion. Our formulation jointly optimizes a base trajectory and a set of footholds over a finite time horizon based on simplified dynamics models. We leverage second-order sensitivity analysis and a sparse Gauss-Newton (SGN) method to solve the resulting optimal control problems. We further describe our ongoing effort to verify our approach through simulation and hardware experiments. Finally, we extend our locomotion framework to deal with challenging tasks that comprise gap crossing, movement on stepping stones, and multi-robot control.