 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTool-R0: Self-Evolving LLM Agents for Tool-Learning from Zero Data
Feb 24, 2026Large language models (LLMs) are becoming the foundation for autonomous agents that can use tools to solve complex tasks. Reinforcement learning (RL) has emerged as a common approach for injecting such agentic capabilities, but typically under tightly controlled training setups. It often depends on carefully constructed task-solution pairs and substantial human supervision, which creates a fundamental obstacle to open-ended self-evolution toward superintelligent systems. In this paper, we propose Tool-R0 framework for training general purpose tool-calling agents from scratch with self-play RL, under a zero-data assumption. Initialized from the same base LLM, Tool-R0 co-evolves a Generator and a Solver with complementary rewards: one proposes targeted challenging tasks at the other's competence frontier and the other learns to solve them with real-world tool calls. This creates a self-evolving cycle that requires no pre-existing tasks or datasets. Evaluation on different tool-use benchmarks show that Tool-R0 yields 92.5 relative improvement over the base model and surpasses fully supervised tool-calling baselines under the same setting. Our work further provides empirical insights into self-play LLM agents by analyzing co-evolution, curriculum dynamics, and scaling behavior.
Reinforcement Learning via Self-Distillation
Jan 28, 2026Large language models are increasingly post-trained with reinforcement learning in verifiable domains such as code and math. Yet, current methods for reinforcement learning with verifiable rewards (RLVR) learn only from a scalar outcome reward per attempt, creating a severe credit-assignment bottleneck. Many verifiable environments actually provide rich textual feedback, such as runtime errors or judge evaluations, that explain why an attempt failed. We formalize this setting as reinforcement learning with rich feedback and introduce Self-Distillation Policy Optimization (SDPO), which converts tokenized feedback into a dense learning signal without any external teacher or explicit reward model. SDPO treats the current model conditioned on feedback as a self-teacher and distills its feedback-informed next-token predictions back into the policy. In this way, SDPO leverages the model's ability to retrospectively identify its own mistakes in-context. Across scientific reasoning, tool use, and competitive programming on LiveCodeBench v6, SDPO improves sample efficiency and final accuracy over strong RLVR baselines. Notably, SDPO also outperforms baselines in standard RLVR environments that only return scalar feedback by using successful rollouts as implicit feedback for failed attempts. Finally, applying SDPO to individual questions at test time accelerates discovery on difficult binary-reward tasks, achieving the same discovery probability as best-of-k sampling or multi-turn conversations with 3x fewer attempts.
Self-Distillation Enables Continual Learning
Jan 27, 2026Continual learning, enabling models to acquire new skills and knowledge without degrading existing capabilities, remains a fundamental challenge for foundation models. While on-policy reinforcement learning can reduce forgetting, it requires explicit reward functions that are often unavailable. Learning from expert demonstrations, the primary alternative, is dominated by supervised fine-tuning (SFT), which is inherently off-policy. We introduce Self-Distillation Fine-Tuning (SDFT), a simple method that enables on-policy learning directly from demonstrations. SDFT leverages in-context learning by using a demonstration-conditioned model as its own teacher, generating on-policy training signals that preserve prior capabilities while acquiring new skills. Across skill learning and knowledge acquisition tasks, SDFT consistently outperforms SFT, achieving higher new-task accuracy while substantially reducing catastrophic forgetting. In sequential learning experiments, SDFT enables a single model to accumulate multiple skills over time without performance regression, establishing on-policy distillation as a practical path to continual learning from demonstrations.
Learning on the Job: Test-Time Curricula for Targeted Reinforcement Learning
Oct 06, 2025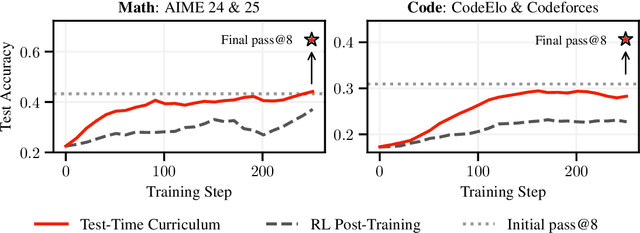
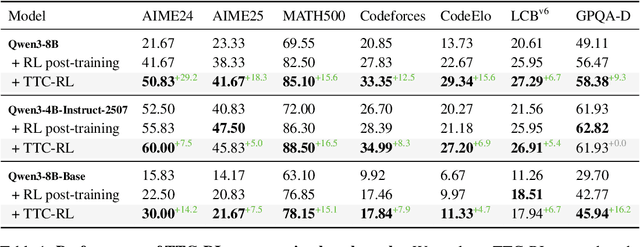
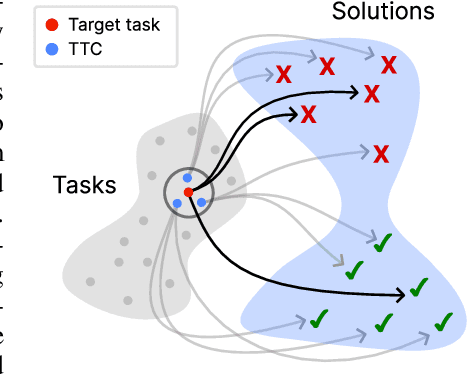
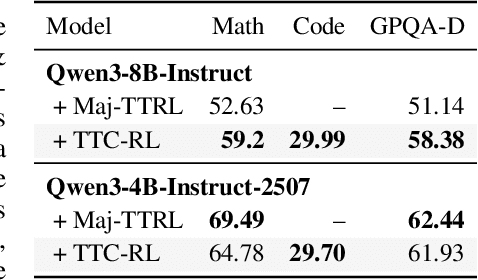
Humans are good at learning on the job: We learn how to solve the tasks we face as we go along. Can a model do the same? We propose an agent that assembles a task-specific curriculum, called test-time curriculum (TTC-RL), and applies reinforcement learning to continue training the model for its target task. The test-time curriculum avoids time-consuming human curation of datasets by automatically selecting the most task-relevant data from a large pool of available training data. Our experiments demonstrate that reinforcement learning on a test-time curriculum consistently improves the model on its target tasks, across a variety of evaluations and models. Notably, on challenging math and coding benchmarks, TTC-RL improves the pass@1 of Qwen3-8B by approximately 1.8x on AIME25 and 2.1x on CodeElo. Moreover, we find that TTC-RL significantly raises the performance ceiling compared to the initial model, increasing pass@8 on AIME25 from 40% to 62% and on CodeElo from 28% to 43%. Our findings show the potential of test-time curricula in extending the test-time scaling paradigm to continual training on thousands of task-relevant experiences during test-time.
DISCOVER: Automated Curricula for Sparse-Reward Reinforcement Learning
May 26, 2025Sparse-reward reinforcement learning (RL) can model a wide range of highly complex tasks. Solving sparse-reward tasks is RL's core premise - requiring efficient exploration coupled with long-horizon credit assignment - and overcoming these challenges is key for building self-improving agents with superhuman ability. We argue that solving complex and high-dimensional tasks requires solving simpler tasks that are relevant to the target task. In contrast, most prior work designs strategies for selecting exploratory tasks with the objective of solving any task, making exploration of challenging high-dimensional, long-horizon tasks intractable. We find that the sense of direction, necessary for effective exploration, can be extracted from existing RL algorithms, without needing any prior information. Based on this finding, we propose a method for directed sparse-reward goal-conditioned very long-horizon RL (DISCOVER), which selects exploratory goals in the direction of the target task. We connect DISCOVER to principled exploration in bandits, formally bounding the time until the target task becomes achievable in terms of the agent's initial distance to the target, but independent of the volume of the space of all tasks. Empirically, we perform a thorough evaluation in high-dimensional environments. We find that the directed goal selection of DISCOVER solves exploration problems that are beyond the reach of prior state-of-the-art exploration methods in RL.
Local Mixtures of Experts: Essentially Free Test-Time Training via Model Merging
May 20, 2025Mixture of expert (MoE) models are a promising approach to increasing model capacity without increasing inference cost, and are core components of many state-of-the-art language models. However, current MoE models typically use only few experts due to prohibitive training and inference cost. We propose Test-Time Model Merging (TTMM) which scales the MoE paradigm to an order of magnitude more experts and uses model merging to avoid almost any test-time overhead. We show that TTMM is an approximation of test-time training (TTT), which fine-tunes an expert model for each prediction task, i.e., prompt. TTT has recently been shown to significantly improve language models, but is computationally expensive. We find that performance of TTMM improves with more experts and approaches the performance of TTT. Moreover, we find that with a 1B parameter base model, TTMM is more than 100x faster than TTT at test-time by amortizing the cost of TTT at train-time. Thus, TTMM offers a promising cost-effective approach to scale test-time training.
Probabilistic Artificial Intelligence
Feb 07, 2025Artificial intelligence commonly refers to the science and engineering of artificial systems that can carry out tasks generally associated with requiring aspects of human intelligence, such as playing games, translating languages, and driving cars. In recent years, there have been exciting advances in learning-based, data-driven approaches towards AI, and machine learning and deep learning have enabled computer systems to perceive the world in unprecedented ways. Reinforcement learning has enabled breakthroughs in complex games such as Go and challenging robotics tasks such as quadrupedal locomotion. A key aspect of intelligence is to not only make predictions, but reason about the uncertainty in these predictions, and to consider this uncertainty when making decisions. This is what this manuscript on "Probabilistic Artificial Intelligence" is about. The first part covers probabilistic approaches to machine learning. We discuss the differentiation between "epistemic" uncertainty due to lack of data and "aleatoric" uncertainty, which is irreducible and stems, e.g., from noisy observations and outcomes. We discuss concrete approaches towards probabilistic inference and modern approaches to efficient approximate inference. The second part of the manuscript is about taking uncertainty into account in sequential decision tasks. We consider active learning and Bayesian optimization -- approaches that collect data by proposing experiments that are informative for reducing the epistemic uncertainty. We then consider reinforcement learning and modern deep RL approaches that use neural network function approximation. We close by discussing modern approaches in model-based RL, which harness epistemic and aleatoric uncertainty to guide exploration, while also reasoning about safety.
Efficiently Learning at Test-Time: Active Fine-Tuning of LLMs
Oct 10, 2024Recent efforts in fine-tuning language models often rely on automatic data selection, commonly using Nearest Neighbors retrieval from large datasets. However, we theoretically show that this approach tends to select redundant data, limiting its effectiveness or even hurting performance. To address this, we introduce SIFT, a data selection algorithm designed to reduce uncertainty about the model's response given a prompt, which unifies ideas from retrieval and active learning. Whereas Nearest Neighbor retrieval typically fails in the presence of information duplication, SIFT accounts for information duplication and optimizes the overall information gain of the selected examples. We focus our evaluations on fine-tuning at test-time for prompt-specific language modeling on the Pile dataset, and show that SIFT consistently outperforms Nearest Neighbor retrieval, with minimal computational overhead. Moreover, we show that our uncertainty estimates can predict the performance gain of test-time fine-tuning, and use this to develop an adaptive algorithm that invests test-time compute proportional to realized performance gains. We provide the $\texttt{activeft}$ (Active Fine-Tuning) library which can be used as a drop-in replacement for Nearest Neighbor retrieval.
Active Fine-Tuning of Generalist Policies
Oct 07, 2024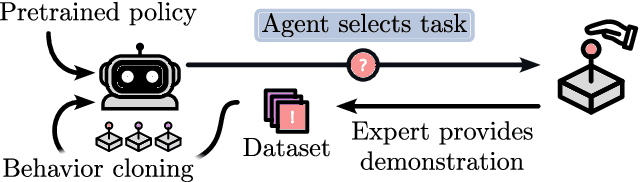
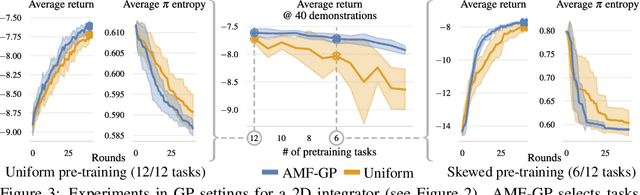
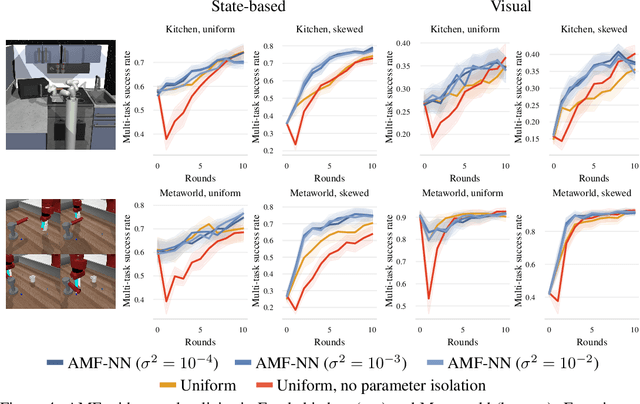
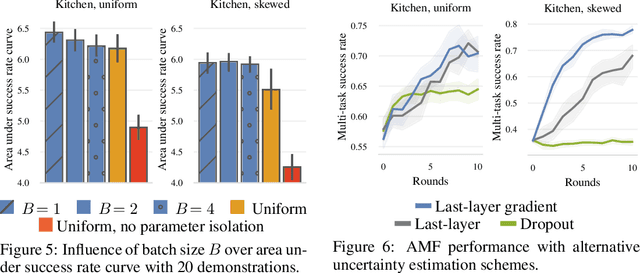
Pre-trained generalist policies are rapidly gaining relevance in robot learning due to their promise of fast adaptation to novel, in-domain tasks. This adaptation often relies on collecting new demonstrations for a specific task of interest and applying imitation learning algorithms, such as behavioral cloning. However, as soon as several tasks need to be learned, we must decide which tasks should be demonstrated and how often? We study this multi-task problem and explore an interactive framework in which the agent adaptively selects the tasks to be demonstrated. We propose AMF (Active Multi-task Fine-tuning), an algorithm to maximize multi-task policy performance under a limited demonstration budget by collecting demonstrations yielding the largest information gain on the expert policy. We derive performance guarantees for AMF under regularity assumptions and demonstrate its empirical effectiveness to efficiently fine-tune neural policies in complex and high-dimensional environments.
Information-based Transductive Active Learning
Feb 13, 2024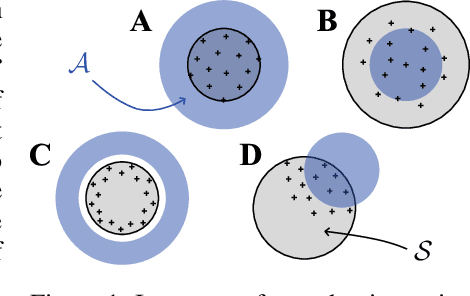
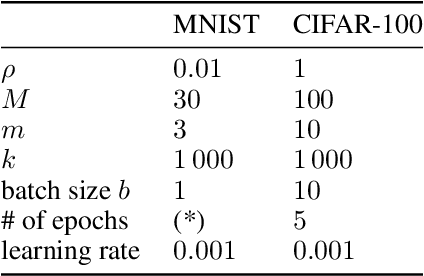
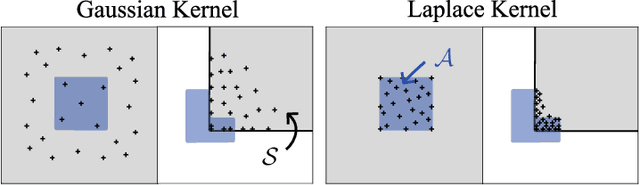
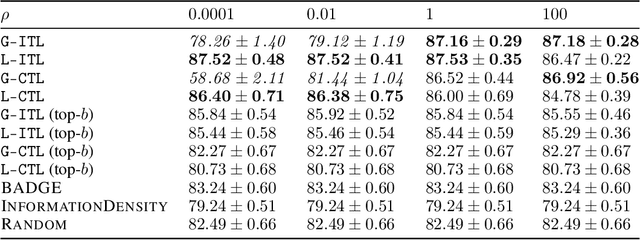
We generalize active learning to address real-world settings where sampling is restricted to an accessible region of the domain, while prediction targets may lie outside this region. To this end, we propose ITL, short for information-based transductive learning, an approach which samples adaptively to maximize the information gained about specified prediction targets. We show, under general regularity assumptions, that ITL converges uniformly to the smallest possible uncertainty obtainable from the accessible data. We demonstrate ITL in two key applications: Few-shot fine-tuning of large neural networks and safe Bayesian optimization, and in both cases, ITL significantly outperforms the state-of-the-art.