 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic Online LQR via Intrinsic Rewards
Mar 30, 2026Optimism in the face of uncertainty is a popular approach to balance exploration and exploitation in reinforcement learning. Here, we consider the online linear quadratic regulator (LQR) problem, i.e., to learn the LQR corresponding to an unknown linear dynamical system by adapting the control policy online based on closed-loop data collected during operation. In this work, we propose Intrinsic Rewards LQR (IR-LQR), an optimistic online LQR algorithm that applies the idea of intrinsic rewards originating from reinforcement learning and the concept of variance regularization to promote uncertainty-driven exploration. IR-LQR retains the structure of a standard LQR synthesis problem by only modifying the cost function, resulting in an intuitively pleasing, simple, computationally cheap, and efficient algorithm. This is in contrast to existing optimistic online LQR formulations that rely on more complicated iterative search algorithms or solve computationally demanding optimization problems. We show that IR-LQR achieves the optimal worst-case regret rate of $\sqrt{T}$, and compare it to various state-of-the-art online LQR algorithms via numerical experiments carried out on an aircraft pitch angle control and an unmanned aerial vehicle example.
ActSafe: Active Exploration with Safety Constraints for Reinforcement Learning
Oct 12, 2024



Reinforcement learning (RL) is ubiquitous in the development of modern AI systems. However, state-of-the-art RL agents require extensive, and potentially unsafe, interactions with their environments to learn effectively. These limitations confine RL agents to simulated environments, hindering their ability to learn directly in real-world settings. In this work, we present ActSafe, a novel model-based RL algorithm for safe and efficient exploration. ActSafe learns a well-calibrated probabilistic model of the system and plans optimistically w.r.t. the epistemic uncertainty about the unknown dynamics, while enforcing pessimism w.r.t. the safety constraints. Under regularity assumptions on the constraints and dynamics, we show that ActSafe guarantees safety during learning while also obtaining a near-optimal policy in finite time. In addition, we propose a practical variant of ActSafe that builds on latest model-based RL advancements and enables safe exploration even in high-dimensional settings such as visual control. We empirically show that ActSafe obtains state-of-the-art performance in difficult exploration tasks on standard safe deep RL benchmarks while ensuring safety during learning.
When to Sense and Control? A Time-adaptive Approach for Continuous-Time RL
Jun 04, 2024Reinforcement learning (RL) excels in optimizing policies for discrete-time Markov decision processes (MDP). However, various systems are inherently continuous in time, making discrete-time MDPs an inexact modeling choice. In many applications, such as greenhouse control or medical treatments, each interaction (measurement or switching of action) involves manual intervention and thus is inherently costly. Therefore, we generally prefer a time-adaptive approach with fewer interactions with the system. In this work, we formalize an RL framework, Time-adaptive Control & Sensing (TaCoS), that tackles this challenge by optimizing over policies that besides control predict the duration of its application. Our formulation results in an extended MDP that any standard RL algorithm can solve. We demonstrate that state-of-the-art RL algorithms trained on TaCoS drastically reduce the interaction amount over their discrete-time counterpart while retaining the same or improved performance, and exhibiting robustness over discretization frequency. Finally, we propose OTaCoS, an efficient model-based algorithm for our setting. We show that OTaCoS enjoys sublinear regret for systems with sufficiently smooth dynamics and empirically results in further sample-efficiency gains.
NeoRL: Efficient Exploration for Nonepisodic RL
Jun 04, 2024We study the problem of nonepisodic reinforcement learning (RL) for nonlinear dynamical systems, where the system dynamics are unknown and the RL agent has to learn from a single trajectory, i.e., without resets. We propose Nonepisodic Optimistic RL (NeoRL), an approach based on the principle of optimism in the face of uncertainty. NeoRL uses well-calibrated probabilistic models and plans optimistically w.r.t. the epistemic uncertainty about the unknown dynamics. Under continuity and bounded energy assumptions on the system, we provide a first-of-its-kind regret bound of $\setO(\beta_T \sqrt{T \Gamma_T})$ for general nonlinear systems with Gaussian process dynamics. We compare NeoRL to other baselines on several deep RL environments and empirically demonstrate that NeoRL achieves the optimal average cost while incurring the least regret.
Bridging the Sim-to-Real Gap with Bayesian Inference
Mar 25, 2024We present SIM-FSVGD for learning robot dynamics from data. As opposed to traditional methods, SIM-FSVGD leverages low-fidelity physical priors, e.g., in the form of simulators, to regularize the training of neural network models. While learning accurate dynamics already in the low data regime, SIM-FSVGD scales and excels also when more data is available. We empirically show that learning with implicit physical priors results in accurate mean model estimation as well as precise uncertainty quantification. We demonstrate the effectiveness of SIM-FSVGD in bridging the sim-to-real gap on a high-performance RC racecar system. Using model-based RL, we demonstrate a highly dynamic parking maneuver with drifting, using less than half the data compared to the state of the art.
Information-based Transductive Active Learning
Feb 13, 2024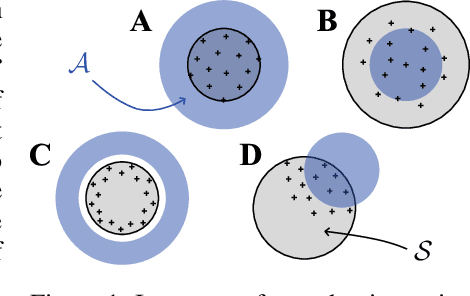
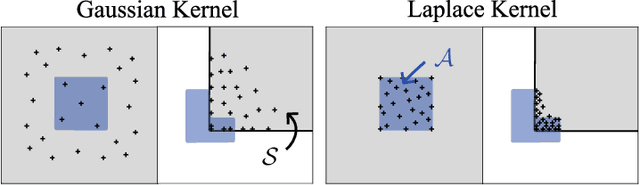
We generalize active learning to address real-world settings where sampling is restricted to an accessible region of the domain, while prediction targets may lie outside this region. To this end, we propose ITL, short for information-based transductive learning, an approach which samples adaptively to maximize the information gained about specified prediction targets. We show, under general regularity assumptions, that ITL converges uniformly to the smallest possible uncertainty obtainable from the accessible data. We demonstrate ITL in two key applications: Few-shot fine-tuning of large neural networks and safe Bayesian optimization, and in both cases, ITL significantly outperforms the state-of-the-art.
Active Few-Shot Fine-Tuning
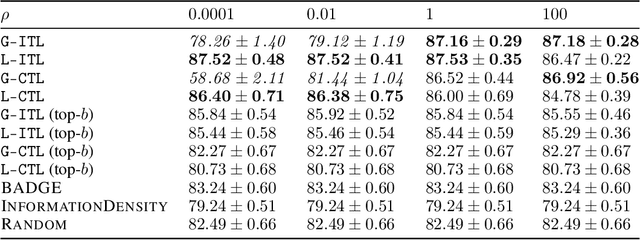
Feb 13, 2024We study the active few-shot fine-tuning of large neural networks to downstream tasks. We show that few-shot fine-tuning is an instance of a generalization of classical active learning, transductive active learning, and we propose ITL, short for information-based transductive learning, an approach which samples adaptively to maximize the information gained about specified downstream tasks. Under general regularity assumptions, we prove that ITL converges uniformly to the smallest possible uncertainty obtainable from the accessible data. To the best of our knowledge, we are the first to derive generalization bounds of this kind, and they may be of independent interest for active learning. We apply ITL to the few-shot fine-tuning of large neural networks and show that ITL substantially improves upon the state-of-the-art.
Efficient Exploration in Continuous-time Model-based Reinforcement Learning
Oct 30, 2023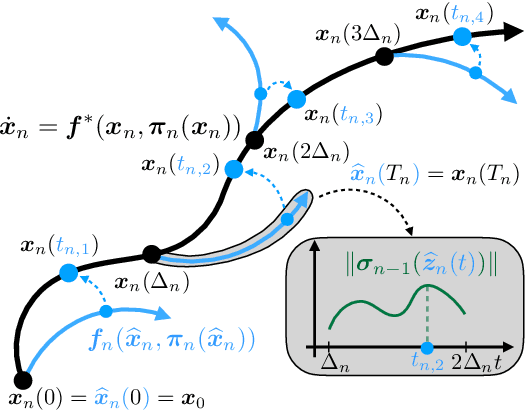
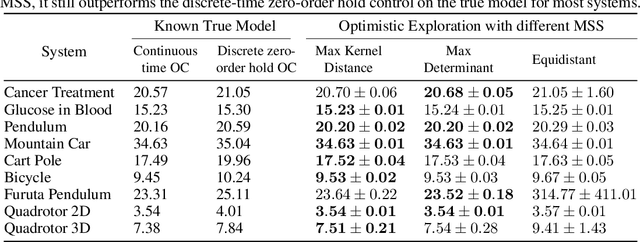
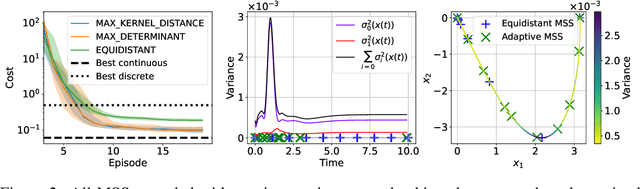
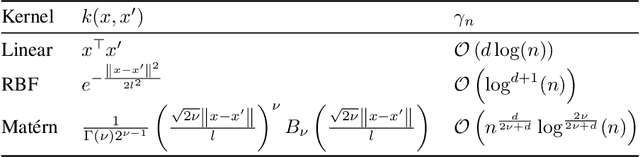
Reinforcement learning algorithms typically consider discrete-time dynamics, even though the underlying systems are often continuous in time. In this paper, we introduce a model-based reinforcement learning algorithm that represents continuous-time dynamics using nonlinear ordinary differential equations (ODEs). We capture epistemic uncertainty using well-calibrated probabilistic models, and use the optimistic principle for exploration. Our regret bounds surface the importance of the measurement selection strategy(MSS), since in continuous time we not only must decide how to explore, but also when to observe the underlying system. Our analysis demonstrates that the regret is sublinear when modeling ODEs with Gaussian Processes (GP) for common choices of MSS, such as equidistant sampling. Additionally, we propose an adaptive, data-dependent, practical MSS that, when combined with GP dynamics, also achieves sublinear regret with significantly fewer samples. We showcase the benefits of continuous-time modeling over its discrete-time counterpart, as well as our proposed adaptive MSS over standard baselines, on several applications.
Optimistic Active Exploration of Dynamical Systems
Jun 21, 2023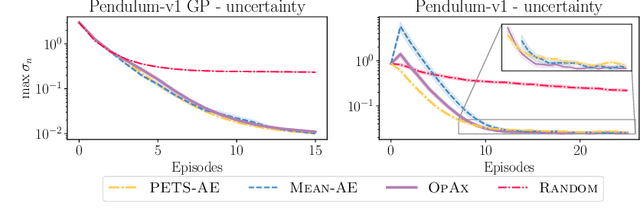
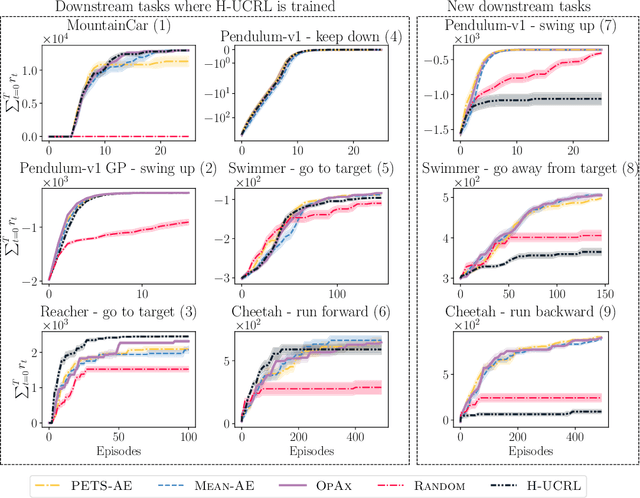
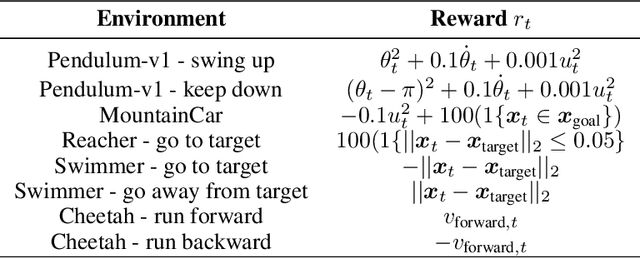
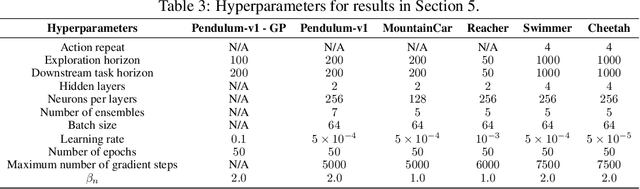
Reinforcement learning algorithms commonly seek to optimize policies for solving one particular task. How should we explore an unknown dynamical system such that the estimated model allows us to solve multiple downstream tasks in a zero-shot manner? In this paper, we address this challenge, by developing an algorithm -- OPAX -- for active exploration. OPAX uses well-calibrated probabilistic models to quantify the epistemic uncertainty about the unknown dynamics. It optimistically -- w.r.t. to plausible dynamics -- maximizes the information gain between the unknown dynamics and state observations. We show how the resulting optimization problem can be reduced to an optimal control problem that can be solved at each episode using standard approaches. We analyze our algorithm for general models, and, in the case of Gaussian process dynamics, we give a sample complexity bound and show that the epistemic uncertainty converges to zero. In our experiments, we compare OPAX with other heuristic active exploration approaches on several environments. Our experiments show that OPAX is not only theoretically sound but also performs well for zero-shot planning on novel downstream tasks.
Distributional Gradient Matching for Learning Uncertain Neural Dynamics Models
Jun 22, 2021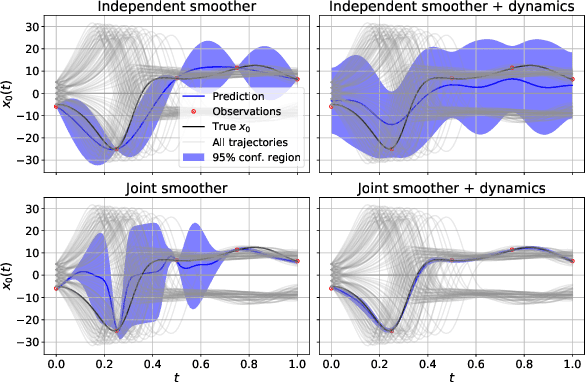

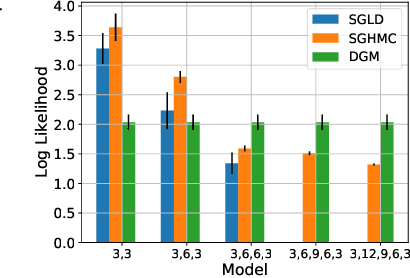
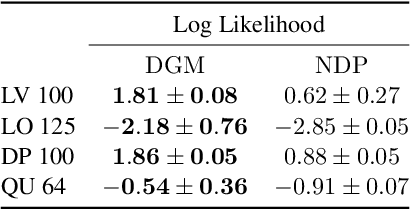
Differential equations in general and neural ODEs in particular are an essential technique in continuous-time system identification. While many deterministic learning algorithms have been designed based on numerical integration via the adjoint method, many downstream tasks such as active learning, exploration in reinforcement learning, robust control, or filtering require accurate estimates of predictive uncertainties. In this work, we propose a novel approach towards estimating epistemically uncertain neural ODEs, avoiding the numerical integration bottleneck. Instead of modeling uncertainty in the ODE parameters, we directly model uncertainties in the state space. Our algorithm - distributional gradient matching (DGM) - jointly trains a smoother and a dynamics model and matches their gradients via minimizing a Wasserstein loss. Our experiments show that, compared to traditional approximate inference methods based on numerical integration, our approach is faster to train, faster at predicting previously unseen trajectories, and in the context of neural ODEs, significantly more accurate.