 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Training for Vision-Language-Action Models
Oct 01, 2025Using Large Language Models to produce intermediate thoughts, a.k.a. Chain-of-thought (CoT), before providing an answer has been a successful recipe for solving complex language tasks. In robotics, similar embodied CoT strategies, generating thoughts before actions, have also been shown to lead to improved performance when using Vision-Language-Action models (VLAs). As these techniques increase the length of the model's generated outputs to include the thoughts, the inference time is negatively affected. Delaying an agent's actions in real-world executions, as in robotic manipulation settings, strongly affects the usability of a method, as tasks require long sequences of actions. However, is the generation of long chains-of-thought a strong prerequisite for achieving performance improvements? In this work, we explore the idea of Hybrid Training (HyT), a framework that enables VLAs to learn from thoughts and benefit from the associated performance gains, while enabling the possibility to leave out CoT generation during inference. Furthermore, by learning to conditionally predict a diverse set of outputs, HyT supports flexibility at inference time, enabling the model to either predict actions directly, generate thoughts or follow instructions. We evaluate the proposed method in a series of simulated benchmarks and real-world experiments.
SENSEI: Semantic Exploration Guided by Foundation Models to Learn Versatile World Models
Mar 03, 2025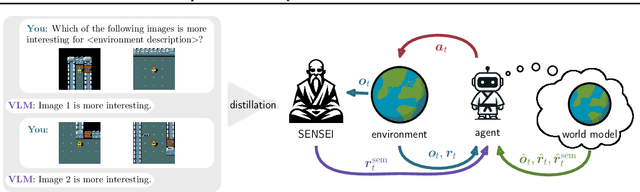
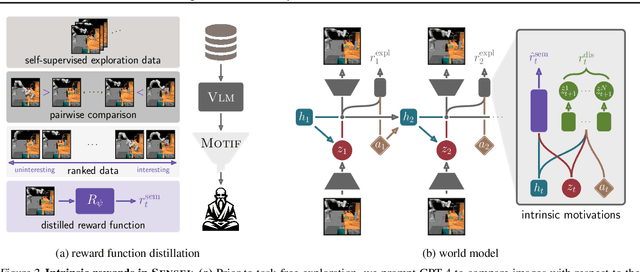
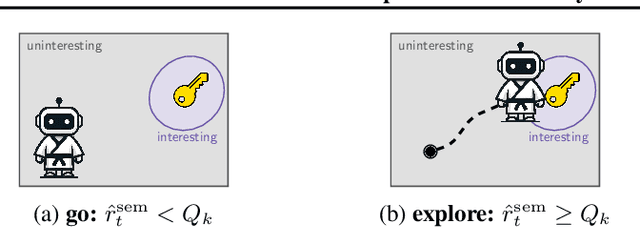
Exploration is a cornerstone of reinforcement learning (RL). Intrinsic motivation attempts to decouple exploration from external, task-based rewards. However, established approaches to intrinsic motivation that follow general principles such as information gain, often only uncover low-level interactions. In contrast, children's play suggests that they engage in meaningful high-level behavior by imitating or interacting with their caregivers. Recent work has focused on using foundation models to inject these semantic biases into exploration. However, these methods often rely on unrealistic assumptions, such as language-embedded environments or access to high-level actions. We propose SEmaNtically Sensible ExploratIon (SENSEI), a framework to equip model-based RL agents with an intrinsic motivation for semantically meaningful behavior. SENSEI distills a reward signal of interestingness from Vision Language Model (VLM) annotations, enabling an agent to predict these rewards through a world model. Using model-based RL, SENSEI trains an exploration policy that jointly maximizes semantic rewards and uncertainty. We show that in both robotic and video game-like simulations SENSEI discovers a variety of meaningful behaviors from image observations and low-level actions. SENSEI provides a general tool for learning from foundation model feedback, a crucial research direction, as VLMs become more powerful.
Regularity as Intrinsic Reward for Free Play
Dec 03, 2023We propose regularity as a novel reward signal for intrinsically-motivated reinforcement learning. Taking inspiration from child development, we postulate that striving for structure and order helps guide exploration towards a subspace of tasks that are not favored by naive uncertainty-based intrinsic rewards. Our generalized formulation of Regularity as Intrinsic Reward (RaIR) allows us to operationalize it within model-based reinforcement learning. In a synthetic environment, we showcase the plethora of structured patterns that can emerge from pursuing this regularity objective. We also demonstrate the strength of our method in a multi-object robotic manipulation environment. We incorporate RaIR into free play and use it to complement the model's epistemic uncertainty as an intrinsic reward. Doing so, we witness the autonomous construction of towers and other regular structures during free play, which leads to a substantial improvement in zero-shot downstream task performance on assembly tasks.
Real Robot Challenge 2022: Learning Dexterous Manipulation from Offline Data in the Real World
Sep 04, 2023Experimentation on real robots is demanding in terms of time and costs. For this reason, a large part of the reinforcement learning (RL) community uses simulators to develop and benchmark algorithms. However, insights gained in simulation do not necessarily translate to real robots, in particular for tasks involving complex interactions with the environment. The Real Robot Challenge 2022 therefore served as a bridge between the RL and robotics communities by allowing participants to experiment remotely with a real robot - as easily as in simulation. In the last years, offline reinforcement learning has matured into a promising paradigm for learning from pre-collected datasets, alleviating the reliance on expensive online interactions. We therefore asked the participants to learn two dexterous manipulation tasks involving pushing, grasping, and in-hand orientation from provided real-robot datasets. An extensive software documentation and an initial stage based on a simulation of the real set-up made the competition particularly accessible. By giving each team plenty of access budget to evaluate their offline-learned policies on a cluster of seven identical real TriFinger platforms, we organized an exciting competition for machine learners and roboticists alike. In this work we state the rules of the competition, present the methods used by the winning teams and compare their results with a benchmark of state-of-the-art offline RL algorithms on the challenge datasets.
Optimistic Active Exploration of Dynamical Systems
Jun 21, 2023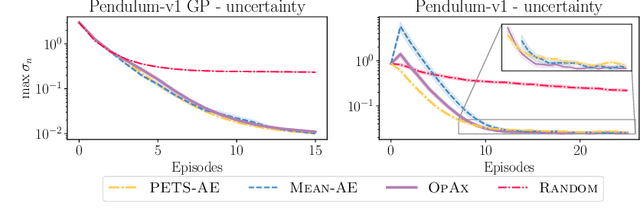
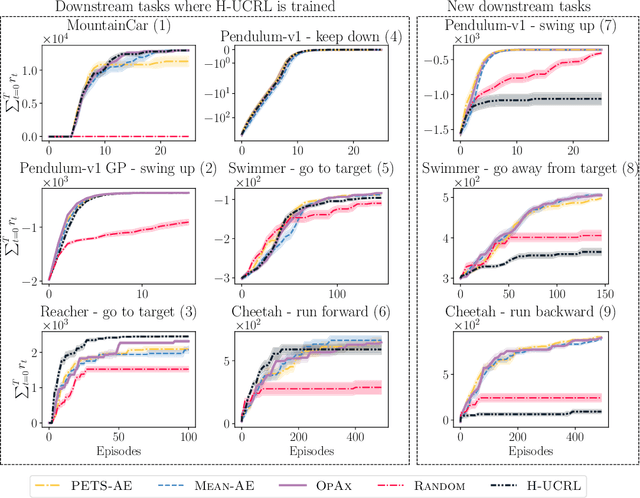
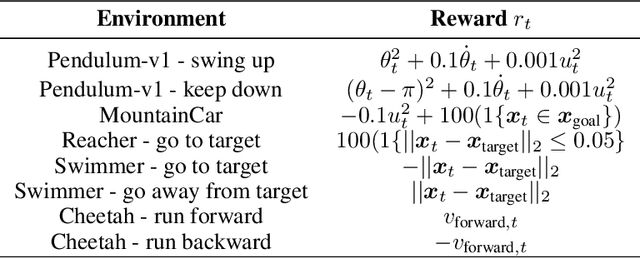
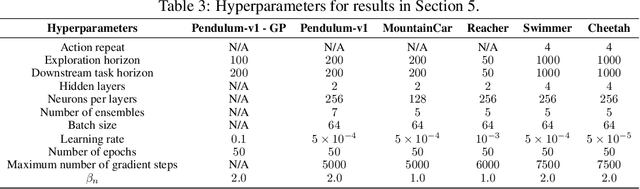
Reinforcement learning algorithms commonly seek to optimize policies for solving one particular task. How should we explore an unknown dynamical system such that the estimated model allows us to solve multiple downstream tasks in a zero-shot manner? In this paper, we address this challenge, by developing an algorithm -- OPAX -- for active exploration. OPAX uses well-calibrated probabilistic models to quantify the epistemic uncertainty about the unknown dynamics. It optimistically -- w.r.t. to plausible dynamics -- maximizes the information gain between the unknown dynamics and state observations. We show how the resulting optimization problem can be reduced to an optimal control problem that can be solved at each episode using standard approaches. We analyze our algorithm for general models, and, in the case of Gaussian process dynamics, we give a sample complexity bound and show that the epistemic uncertainty converges to zero. In our experiments, we compare OPAX with other heuristic active exploration approaches on several environments. Our experiments show that OPAX is not only theoretically sound but also performs well for zero-shot planning on novel downstream tasks.
Curious Exploration via Structured World Models Yields Zero-Shot Object Manipulation
Jun 22, 2022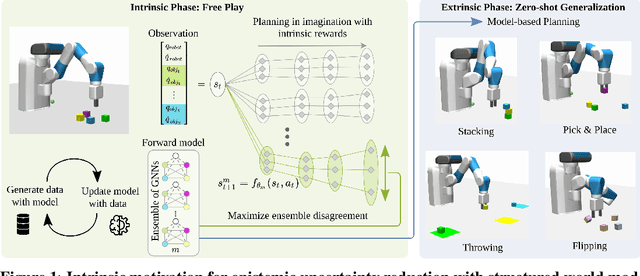

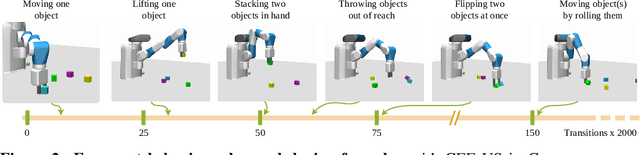
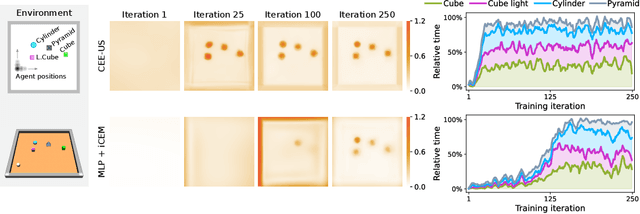
It has been a long-standing dream to design artificial agents that explore their environment efficiently via intrinsic motivation, similar to how children perform curious free play. Despite recent advances in intrinsically motivated reinforcement learning (RL), sample-efficient exploration in object manipulation scenarios remains a significant challenge as most of the relevant information lies in the sparse agent-object and object-object interactions. In this paper, we propose to use structured world models to incorporate relational inductive biases in the control loop to achieve sample-efficient and interaction-rich exploration in compositional multi-object environments. By planning for future novelty inside structured world models, our method generates free-play behavior that starts to interact with objects early on and develops more complex behavior over time. Instead of using models only to compute intrinsic rewards, as commonly done, our method showcases that the self-reinforcing cycle between good models and good exploration also opens up another avenue: zero-shot generalization to downstream tasks via model-based planning. After the entirely intrinsic task-agnostic exploration phase, our method solves challenging downstream tasks such as stacking, flipping, pick & place, and throwing that generalizes to unseen numbers and arrangements of objects without any additional training.
End-to-End Pixel-Based Deep Active Inference for Body Perception and Action
Dec 28, 2019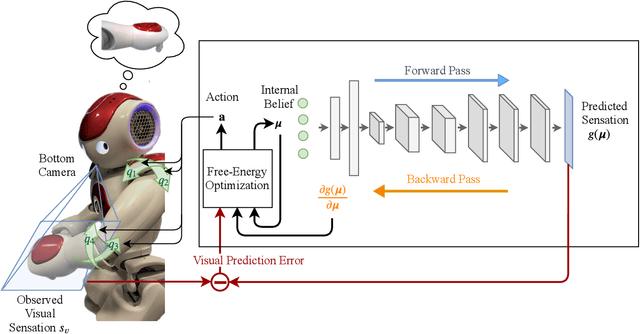

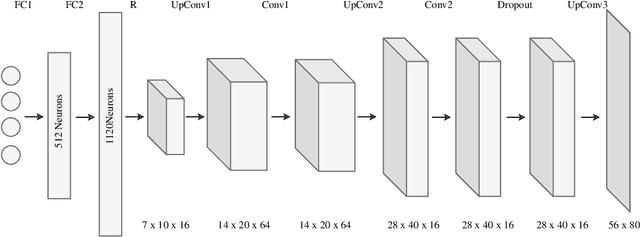

We present a pixel-based deep Active Inference algorithm (PixelAI) inspired in human body perception and successfully validated in robot body perception and action as a use case. Our algorithm combines the free energy principle from neuroscience, rooted in variational inference, with deep convolutional decoders to scale the algorithm to directly deal with images input and provide online adaptive inference. The approach enables the robot to perform 1) dynamical body estimation of arm using only raw monocular camera images and 2) autonomous reaching to "imagined" arm poses in the visual space. We statistically analyzed the algorithm performance in a simulated and a real Nao robot. Results show how the same algorithm deals with both perception an action, modelled as an inference optimization problem.