 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Spiking Neurons for Vision and Language Modeling
Apr 14, 2026Regarded as the third generation of neural networks, Spiking Neural Networks (SNNs) have garnered significant traction due to their biological plausibility and energy efficiency. Recent advancements in large models necessitate spiking neurons capable of high performance, adaptability, and training efficiency. In this work, we first propose a novel functional perspective that provides general guidance for designing the new generation of spiking neurons. Following the insightful guidelines, we propose the Adaptive Spiking Neuron (ASN), which incorporates trainable parameters to learn membrane potential dynamics and enable adaptive firing. ASN adopts an integer training and spike inference paradigm, facilitating efficient SNN training. To further enhance robustness, we propose a specialized variant of ASN, the Normalized Adaptive Spiking Neuron (NASN), which integrates normalization to stabilize training. We evaluate our neuron model on 19 datasets spanning five distinct tasks in both vision and language modalities, demonstrating the effectiveness and versatility of the ASN family. Our ASN family is expected to become the new generation of general-purpose spiking neurons.
Maximum Entropy Behavior Exploration for Sim2Real Zero-Shot Reinforcement Learning
Mar 26, 2026Zero-shot reinforcement learning (RL) algorithms aim to learn a family of policies from a reward-free dataset, and recover optimal policies for any reward function directly at test time. Naturally, the quality of the pretraining dataset determines the performance of the recovered policies across tasks. However, pre-collecting a relevant, diverse dataset without prior knowledge of the downstream tasks of interest remains a challenge. In this work, we study $\textit{online}$ zero-shot RL for quadrupedal control on real robotic systems, building upon the Forward-Backward (FB) algorithm. We observe that undirected exploration yields low-diversity data, leading to poor downstream performance and rendering policies impractical for direct hardware deployment. Therefore, we introduce FB-MEBE, an online zero-shot RL algorithm that combines an unsupervised behavior exploration strategy with a regularization critic. FB-MEBE promotes exploration by maximizing the entropy of the achieved behavior distribution. Additionally, a regularization critic shapes the recovered policies toward more natural and physically plausible behaviors. We empirically demonstrate that FB-MEBE achieves and improved performance compared to other exploration strategies in a range of simulated downstream tasks, and that it renders natural policies that can be seamlessly deployed to hardware without further finetuning. Videos and code available on our website.
Teaching Robots Like Dogs: Learning Agile Navigation from Luring, Gesture, and Speech
Jan 13, 2026In this work, we aim to enable legged robots to learn how to interpret human social cues and produce appropriate behaviors through physical human guidance. However, learning through physical engagement can place a heavy burden on users when the process requires large amounts of human-provided data. To address this, we propose a human-in-the-loop framework that enables robots to acquire navigational behaviors in a data-efficient manner and to be controlled via multimodal natural human inputs, specifically gestural and verbal commands. We reconstruct interaction scenes using a physics-based simulation and aggregate data to mitigate distributional shifts arising from limited demonstration data. Our progressive goal cueing strategy adaptively feeds appropriate commands and navigation goals during training, leading to more accurate navigation and stronger alignment between human input and robot behavior. We evaluate our framework across six real-world agile navigation scenarios, including jumping over or avoiding obstacles. Our experimental results show that our proposed method succeeds in almost all trials across these scenarios, achieving a 97.15% task success rate with less than 1 hour of demonstration data in total.
Trading Vector Data in Vector Databases
Nov 10, 2025Vector data trading is essential for cross-domain learning with vector databases, yet it remains largely unexplored. We study this problem under online learning, where sellers face uncertain retrieval costs and buyers provide stochastic feedback to posted prices. Three main challenges arise: (1) heterogeneous and partial feedback in configuration learning, (2) variable and complex feedback in pricing learning, and (3) inherent coupling between configuration and pricing decisions. We propose a hierarchical bandit framework that jointly optimizes retrieval configurations and pricing. Stage I employs contextual clustering with confidence-based exploration to learn effective configurations with logarithmic regret. Stage II adopts interval-based price selection with local Taylor approximation to estimate buyer responses and achieve sublinear regret. We establish theoretical guarantees with polynomial time complexity and validate the framework on four real-world datasets, demonstrating consistent improvements in cumulative reward and regret reduction compared with existing methods.
RAMBO: RL-augmented Model-based Optimal Control for Whole-body Loco-manipulation
Apr 09, 2025
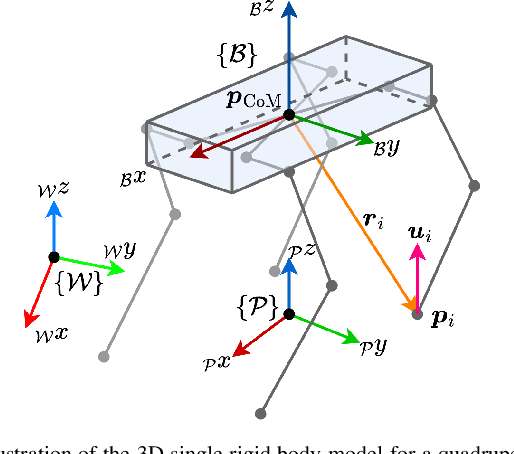
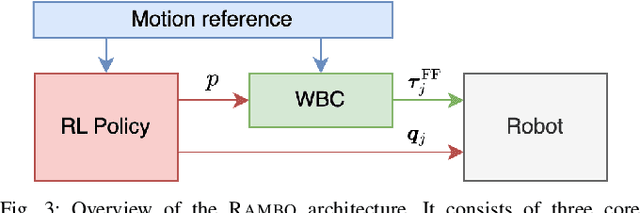

Loco-manipulation -- coordinated locomotion and physical interaction with objects -- remains a major challenge for legged robots due to the need for both accurate force interaction and robustness to unmodeled dynamics. While model-based controllers provide interpretable dynamics-level planning and optimization, they are limited by model inaccuracies and computational cost. In contrast, learning-based methods offer robustness while struggling with precise modulation of interaction forces. We introduce RAMBO -- RL-Augmented Model-Based Optimal Control -- a hybrid framework that integrates model-based reaction force optimization using a simplified dynamics model and a feedback policy trained with reinforcement learning. The model-based module generates feedforward torques by solving a quadratic program, while the policy provides feedback residuals to enhance robustness in control execution. We validate our framework on a quadruped robot across a diverse set of real-world loco-manipulation tasks -- such as pushing a shopping cart, balancing a plate, and holding soft objects -- in both quadrupedal and bipedal walking. Our experiments demonstrate that RAMBO enables precise manipulation while achieving robust and dynamic locomotion, surpassing the performance of policies trained with end-to-end scheme. In addition, our method enables flexible trade-off between end-effector tracking accuracy with compliance.
SATA: Safe and Adaptive Torque-Based Locomotion Policies Inspired by Animal Learning
Feb 18, 2025



Despite recent advances in learning-based controllers for legged robots, deployments in human-centric environments remain limited by safety concerns. Most of these approaches use position-based control, where policies output target joint angles that must be processed by a low-level controller (e.g., PD or impedance controllers) to compute joint torques. Although impressive results have been achieved in controlled real-world scenarios, these methods often struggle with compliance and adaptability when encountering environments or disturbances unseen during training, potentially resulting in extreme or unsafe behaviors. Inspired by how animals achieve smooth and adaptive movements by controlling muscle extension and contraction, torque-based policies offer a promising alternative by enabling precise and direct control of the actuators in torque space. In principle, this approach facilitates more effective interactions with the environment, resulting in safer and more adaptable behaviors. However, challenges such as a highly nonlinear state space and inefficient exploration during training have hindered their broader adoption. To address these limitations, we propose SATA, a bio-inspired framework that mimics key biomechanical principles and adaptive learning mechanisms observed in animal locomotion. Our approach effectively addresses the inherent challenges of learning torque-based policies by significantly improving early-stage exploration, leading to high-performance final policies. Remarkably, our method achieves zero-shot sim-to-real transfer. Our experimental results indicate that SATA demonstrates remarkable compliance and safety, even in challenging environments such as soft/slippery terrain or narrow passages, and under significant external disturbances, highlighting its potential for practical deployments in human-centric and safety-critical scenarios.
CAIMAN: Causal Action Influence Detection for Sample Efficient Loco-manipulation
Feb 02, 2025Enabling legged robots to perform non-prehensile loco-manipulation with large and heavy objects is crucial for enhancing their versatility. However, this is a challenging task, often requiring sophisticated planning strategies or extensive task-specific reward shaping, especially in unstructured scenarios with obstacles. In this work, we present CAIMAN, a novel framework for learning loco-manipulation that relies solely on sparse task rewards. We leverage causal action influence to detect states where the robot is in control over other entities in the environment, and use this measure as an intrinsically motivated objective to enable sample-efficient learning. We employ a hierarchical control strategy, combining a low-level locomotion policy with a high-level policy that prioritizes task-relevant velocity commands. Through simulated and real-world experiments, including object manipulation with obstacles, we demonstrate the framework's superior sample efficiency, adaptability to diverse environments, and successful transfer to hardware without fine-tuning. The proposed approach paves the way for scalable, robust, and autonomous loco-manipulation in real-world applications.
Learning More With Less: Sample Efficient Dynamics Learning and Model-Based RL for Loco-Manipulation
Jan 17, 2025



Combining the agility of legged locomotion with the capabilities of manipulation, loco-manipulation platforms have the potential to perform complex tasks in real-world applications. To this end, state-of-the-art quadrupeds with attached manipulators, such as the Boston Dynamics Spot, have emerged to provide a capable and robust platform. However, both the complexity of loco-manipulation control, as well as the black-box nature of commercial platforms pose challenges for developing accurate dynamics models and control policies. We address these challenges by developing a hand-crafted kinematic model for a quadruped-with-arm platform and, together with recent advances in Bayesian Neural Network (BNN)-based dynamics learning using physical priors, efficiently learn an accurate dynamics model from data. We then derive control policies for loco-manipulation via model-based reinforcement learning (RL). We demonstrate the effectiveness of this approach on hardware using the Boston Dynamics Spot with a manipulator, accurately performing dynamic end-effector trajectory tracking even in low data regimes.
DARE: Diffusion Policy for Autonomous Robot Exploration
Oct 22, 2024



Autonomous robot exploration requires a robot to efficiently explore and map unknown environments. Compared to conventional methods that can only optimize paths based on the current robot belief, learning-based methods show the potential to achieve improved performance by drawing on past experiences to reason about unknown areas. In this paper, we propose DARE, a novel generative approach that leverages diffusion models trained on expert demonstrations, which can explicitly generate an exploration path through one-time inference. We build DARE upon an attention-based encoder and a diffusion policy model, and introduce ground truth optimal demonstrations for training to learn better patterns for exploration. The trained planner can reason about the partial belief to recognize the potential structure in unknown areas and consider these areas during path planning. Our experiments demonstrate that DARE achieves on-par performance with both conventional and learning-based state-of-the-art exploration planners, as well as good generalizability in both simulations and real-life scenarios.
RobotKeyframing: Learning Locomotion with High-Level Objectives via Mixture of Dense and Sparse Rewards
Jul 16, 2024



This paper presents a novel learning-based control framework that uses keyframing to incorporate high-level objectives in natural locomotion for legged robots. These high-level objectives are specified as a variable number of partial or complete pose targets that are spaced arbitrarily in time. Our proposed framework utilizes a multi-critic reinforcement learning algorithm to effectively handle the mixture of dense and sparse rewards. Additionally, it employs a transformer-based encoder to accommodate a variable number of input targets, each associated with specific time-to-arrivals. Throughout simulation and hardware experiments, we demonstrate that our framework can effectively satisfy the target keyframe sequence at the required times. In the experiments, the multi-critic method significantly reduces the effort of hyperparameter tuning compared to the standard single-critic alternative. Moreover, the proposed transformer-based architecture enables robots to anticipate future goals, which results in quantitative improvements in their ability to reach their targets.