 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWAP: Symmetric Equivariant World-Model for Agile Robot Parkour
Jun 18, 2026While latent world models enable the proactive predictions required for extreme parkour, their purely data-driven nature forces them to redundantly encode left-right symmetric interactions as independent patterns. This inflates the learning burden and hinders the capture of geometric regularities, restricting the latent space's efficiency for downstream policies. To address this, we propose SWAP, an end-to-end equivariant symmetric world model. This framework embeds symmetry directly into both the world model and the actor-critic networks. In real-world tests, the robot leaps across a 2.13 m gap and climbs a 1.63 m platform, breaking records for quadruped parkour. Furthermore, the framework exhibits robust geometric generalization to unseen mirrored terrains and exceptional zero-shot transferability across diverse outdoor environments. These results demonstrate that symmetry equivariance is an effective structural prior for pushing the physical boundaries of learned legged locomotion.
TAGA: Terrain-aware Active Gaze Learning for Generalizable Agile Humanoid Locomotion
Jun 04, 2026Agile humanoid locomotion across diverse challenging terrain demands both wide perceptual coverage and precise local geometry understanding. Motivated by the way humans selectively look at relevant terrain during locomotion, we introduce TAGA, a Terrain-aware Active Gaze learning framework for Attention-based humanoid control. By fusing vision, proprioception, and motion commands, our framework guides the model to learn anticipatory cues and actively attend to specific areas of the height scan, selectively using these informative regions for the downstream network. This adaptively increases the information density of observations under tight onboard computational constraints, thus enabling fine-grained perceptive locomotion over larger-scale terrains. We find that such gaze behaviors can naturally emerge through reinforcement learning alone, without requiring additional supervision or explicit guidance, significantly improve training efficiency. As a result, the trained policy demonstrates robust and generalizable locomotion in simulation and on hardware, including reliable terrain-aware foothold selection, elevated-platform traversal, competitive sparse-foothold traversal, and the largest reported real-world gap traversal distance of 1.2m among perceptive humanoid locomotion systems, while maintaining stability under severe perceptual disturbances and environmental interference.
Hinge Regression Trees and HRT-Boost: Newton-Optimized Oblique Learning for Compact Tabular Models
May 22, 2026Learning high-quality oblique decision trees remains a significant challenge due to the discrete and non-convex nature of split optimization. We present the Hinge Regression Tree (HRT) framework, which reframes each oblique split as a nonlinear least-squares problem over two linear predictors whose max/min envelope induces ReLU-like representation capacity. We show that the resulting node-level optimization can be interpreted as a damped Newton method, and we establish the monotonic decrease of the node objective for its backtracking line-search variant. We establish, theoretically, that HRT is a universal approximator with an explicit $O(δ^2)$ approximation rate. Building upon this base learner, we propose HRT-Boost, a mathematically synergistic ensemble extension that couples node-level Newton updates with stage-wise functional gradient descent. We show that this ensemble construction admits a stage-wise empirical risk reduction guarantee under the squared loss. Empirical evaluations on synthetic and real-world benchmarks show that HRT is highly competitive with established single-tree baselines, and HRT-Boost compares favorably with strong ensemble baselines and often yields substantially more compact models. The code is publicly available at https://github.com/Hongyi-Li-sz/HRT-Boost.
Joint sparse coding and temporal dynamics support context reconfiguration
May 11, 2026Adaptive behavior requires the brain to transition between distinct contexts while maintaining representations of prior experience. The ability to reconfigure neural representations without erasing previously acquired knowledge is central to learning in dynamic environments, yet the neural mechanisms that support this balance remain unclear. Understanding these mechanisms is also critical for addressing catastrophic forgetting in artificial systems designed for lifelong learning. Here, we identify joint sparse coding and temporal dynamics in both the mouse medial prefrontal cortex (mPFC) and computational networks as mechanisms that help preserve prior representations during context transitions. Specifically, sparsity in context-dependent representations reduces cross-context interference, whereas temporal dynamics within the network activity further enhance context separability across time. Strikingly, networks endowed with both properties, such as spiking neural networks, exhibit improved retention during lifelong learning without auxiliary heuristics. These findings establish joint sparse coding and temporal dynamics as a core mechanism supporting flexible context reconfiguration in lifelong learning and, through their activity constraining nature, as an energy-efficient architectural principle for stable adaptation. Together, they provide a mechanistic framework for understanding how the brain preserves prior knowledge while flexibly adapting to new contexts.
Expert Streaming: Accelerating Low-Batch MoE Inference via Multi-chiplet Architecture and Dynamic Expert Trajectory Scheduling
Mar 29, 2026Mixture-of-Experts is a promising approach for edge AI with low-batch inference. Yet, on-device deployments often face limited on-chip memory and severe workload imbalance; the prevalent use of offloading further incurs off-chip memory access bottlenecks. Moreover, MoE sparsity and dynamic gating shift distributed strategies toward much finer granularity and introduce runtime scheduling considerations. Recently, high die-to-die bandwidth chiplet interconnects have created new opportunities for multi-chiplet systems to address workload imbalance and offloading bottlenecks with fine-grained scheduling. In this paper, we propose Fully Sharded Expert Data Parallelism, a parallelization paradigm specifically architected for low-batch MoE inference on multi-chiplet accelerators. FSE-DP attains adaptive computation-communication overlap and balanced load by orchestrating fine-grained, complementary expert streams along dynamic trajectories across high-bandwidth D2D links. The attendant dataflow complexity is tamed by a minimal, hardware-amenable set of virtualization rules and a lightweight scheduling algorithm. Our approach achieves 1.22 to 2.00 times speedup over state-of-the-art baselines and saves up to 78.8 percent on-chip memory.
Loosely-Structured Software: Engineering Context, Structure, and Evolution Entropy in Runtime-Rewired Multi-Agent Systems
Mar 16, 2026As LLM-based multi-agent systems (MAS) become more autonomous, their free-form interactions increasingly dominate system behavior. However, scaling the number of agents often amplifies context pressure, coordination errors, and system drift. It is well known that building robust MAS requires more than prompt tuning or increased model intelligence. It necessitates engineering discipline focused on architecture to manage complexity under uncertainty. We characterize agentic software by a core property: \emph{runtime generation and evolution under uncertainty}. Drawing upon and extending software engineering experience, especially object-oriented programming, this paper introduces \emph{Loosely-Structured Software (LSS)}, a new class of software systems that shifts the engineering focus from constructing deterministic logic to managing the runtime entropy generated by View-constructed programming, semantic-driven self-organization, and endogenous evolution. To make this entropy governable, we introduce design principles under a three-layer engineering framework: \emph{View/Context Engineering} to manage the execution environment and maintain task-relevant Views, \emph{Structure Engineering} to organize dynamic binding over artifacts and agents, and \emph{Evolution Engineering} to govern the lifecycle of self-rewriting artifacts. Building on this framework, we develop LSS design patterns as semantic control blocks that stabilize fluid, inference-mediated interactions while preserving agent adaptability. Together, these abstractions improve the \emph{designability}, \emph{scalability}, and \emph{evolvability} of agentic infrastructure. We provide basic experimental validation of key mechanisms, demonstrating the effectiveness of LSS.
Hinge Regression Tree: A Newton Method for Oblique Regression Tree Splitting
Feb 05, 2026Oblique decision trees combine the transparency of trees with the power of multivariate decision boundaries, but learning high-quality oblique splits is NP-hard, and practical methods still rely on slow search or theory-free heuristics. We present the Hinge Regression Tree (HRT), which reframes each split as a non-linear least-squares problem over two linear predictors whose max/min envelope induces ReLU-like expressive power. The resulting alternating fitting procedure is exactly equivalent to a damped Newton (Gauss-Newton) method within fixed partitions. We analyze this node-level optimization and, for a backtracking line-search variant, prove that the local objective decreases monotonically and converges; in practice, both fixed and adaptive damping yield fast, stable convergence and can be combined with optional ridge regularization. We further prove that HRT's model class is a universal approximator with an explicit $O(δ^2)$ approximation rate, and show on synthetic and real-world benchmarks that it matches or outperforms single-tree baselines with more compact structures.
Rotation-Robust Regression with Convolutional Model Trees
Jan 08, 2026We study rotation-robust learning for image inputs using Convolutional Model Trees (CMTs) [1], whose split and leaf coefficients can be structured on the image grid and transformed geometrically at deployment time. In a controlled MNIST setting with a rotation-invariant regression target, we introduce three geometry-aware inductive biases for split directions -- convolutional smoothing, a tilt dominance constraint, and importance-based pruning -- and quantify their impact on robustness under in-plane rotations. We further evaluate a deployment-time orientation search that selects a discrete rotation maximizing a forest-level confidence proxy without updating model parameters. Orientation search improves robustness under severe rotations but can be harmful near the canonical orientation when confidence is misaligned with correctness. Finally, we observe consistent trends on MNIST digit recognition implemented as one-vs-rest regression, highlighting both the promise and limitations of confidence-based orientation selection for model-tree ensembles.
START: Traversing Sparse Footholds with Terrain Reconstruction
Dec 15, 2025

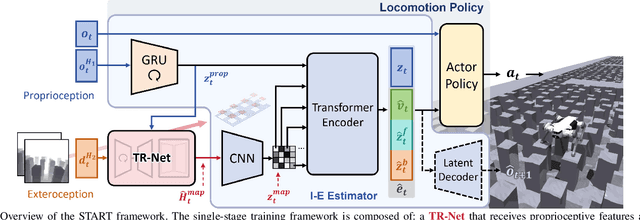
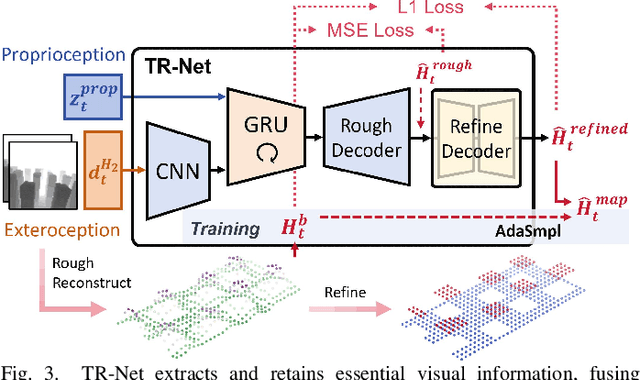
Traversing terrains with sparse footholds like legged animals presents a promising yet challenging task for quadruped robots, as it requires precise environmental perception and agile control to secure safe foot placement while maintaining dynamic stability. Model-based hierarchical controllers excel in laboratory settings, but suffer from limited generalization and overly conservative behaviors. End-to-end learning-based approaches unlock greater flexibility and adaptability, but existing state-of-the-art methods either rely on heightmaps that introduce noise and complex, costly pipelines, or implicitly infer terrain features from egocentric depth images, often missing accurate critical geometric cues and leading to inefficient learning and rigid gaits. To overcome these limitations, we propose START, a single-stage learning framework that enables agile, stable locomotion on highly sparse and randomized footholds. START leverages only low-cost onboard vision and proprioception to accurately reconstruct local terrain heightmap, providing an explicit intermediate representation to convey essential features relevant to sparse foothold regions. This supports comprehensive environmental understanding and precise terrain assessment, reducing exploration cost and accelerating skill acquisition. Experimental results demonstrate that START achieves zero-shot transfer across diverse real-world scenarios, showcasing superior adaptability, precise foothold placement, and robust locomotion.
LHT: Statistically-Driven Oblique Decision Trees for Interpretable Classification
May 07, 2025We introduce the Learning Hyperplane Tree (LHT), a novel oblique decision tree model designed for expressive and interpretable classification. LHT fundamentally distinguishes itself through a non-iterative, statistically-driven approach to constructing splitting hyperplanes. Unlike methods that rely on iterative optimization or heuristics, LHT directly computes the hyperplane parameters, which are derived from feature weights based on the differences in feature expectations between classes within each node. This deterministic mechanism enables a direct and well-defined hyperplane construction process. Predictions leverage a unique piecewise linear membership function within leaf nodes, obtained via local least-squares fitting. We formally analyze the convergence of the LHT splitting process, ensuring that each split yields meaningful, non-empty partitions. Furthermore, we establish that the time complexity for building an LHT up to depth $d$ is $O(mnd)$, demonstrating the practical feasibility of constructing trees with powerful oblique splits using this methodology. The explicit feature weighting at each split provides inherent interpretability. Experimental results on benchmark datasets demonstrate LHT's competitive accuracy, positioning it as a practical, theoretically grounded, and interpretable alternative in the landscape of tree-based models. The implementation of the proposed method is available at https://github.com/Hongyi-Li-sz/LHT_model.