 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity-based Layerwise Distributed Training of Graph Convolutional Networks
Paper and Code
Dec 17, 2021
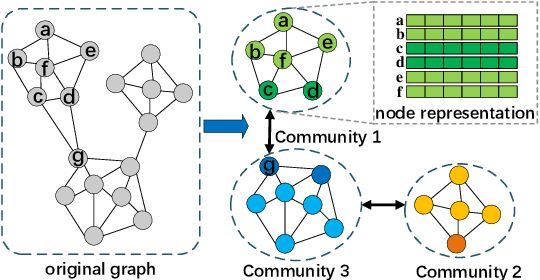
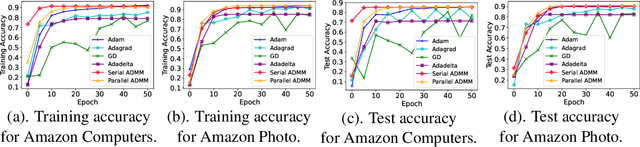

The Graph Convolutional Network (GCN) has been successfully applied to many graph-based applications. Training a large-scale GCN model, however, is still challenging: Due to the node dependency and layer dependency of the GCN architecture, a huge amount of computational time and memory is required in the training process. In this paper, we propose a parallel and distributed GCN training algorithm based on the Alternating Direction Method of Multipliers (ADMM) to tackle the two challenges simultaneously. We first split GCN layers into independent blocks to achieve layer parallelism. Furthermore, we reduce node dependency by dividing the graph into several dense communities such that each of them can be trained with an agent in parallel. Finally, we provide solutions for all subproblems in the community-based ADMM algorithm. Preliminary results demonstrate that our proposed community-based ADMM training algorithm can lead to more than triple speedup while achieving the best performance compared with state-of-the-art methods.