 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Convergent ADMM Framework for Efficient Neural Network Training
Paper and Code
Dec 22, 2021


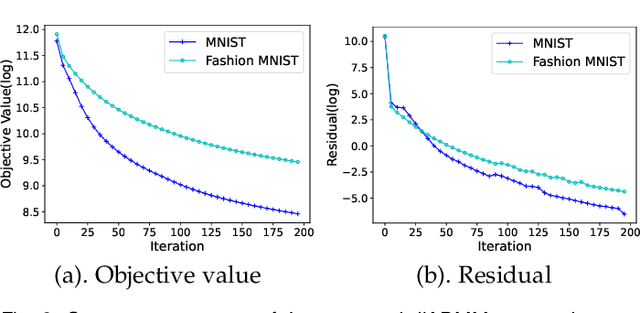
As a well-known optimization framework, the Alternating Direction Method of Multipliers (ADMM) has achieved tremendous success in many classification and regression applications. Recently, it has attracted the attention of deep learning researchers and is considered to be a potential substitute to Gradient Descent (GD). However, as an emerging domain, several challenges remain unsolved, including 1) The lack of global convergence guarantees, 2) Slow convergence towards solutions, and 3) Cubic time complexity with regard to feature dimensions. In this paper, we propose a novel optimization framework to solve a general neural network training problem via ADMM (dlADMM) to address these challenges simultaneously. Specifically, the parameters in each layer are updated backward and then forward so that parameter information in each layer is exchanged efficiently. When the dlADMM is applied to specific architectures, the time complexity of subproblems is reduced from cubic to quadratic via a dedicated algorithm design utilizing quadratic approximations and backtracking techniques. Last but not least, we provide the first proof of convergence to a critical point sublinearly for an ADMM-type method (dlADMM) under mild conditions. Experiments on seven benchmark datasets demonstrate the convergence, efficiency, and effectiveness of our proposed dlADMM algorithm.