 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIA: An Inpainting-Based Approach for Music Adversarial Attacks
Sep 05, 2025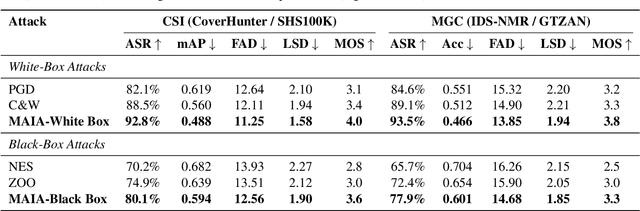
Music adversarial attacks have garnered significant interest in the field of Music Information Retrieval (MIR). In this paper, we present Music Adversarial Inpainting Attack (MAIA), a novel adversarial attack framework that supports both white-box and black-box attack scenarios. MAIA begins with an importance analysis to identify critical audio segments, which are then targeted for modification. Utilizing generative inpainting models, these segments are reconstructed with guidance from the output of the attacked model, ensuring subtle and effective adversarial perturbations. We evaluate MAIA on multiple MIR tasks, demonstrating high attack success rates in both white-box and black-box settings while maintaining minimal perceptual distortion. Additionally, subjective listening tests confirm the high audio fidelity of the adversarial samples. Our findings highlight vulnerabilities in current MIR systems and emphasize the need for more robust and secure models.
Training a Perceptual Model for Evaluating Auditory Similarity in Music Adversarial Attack
Sep 05, 2025
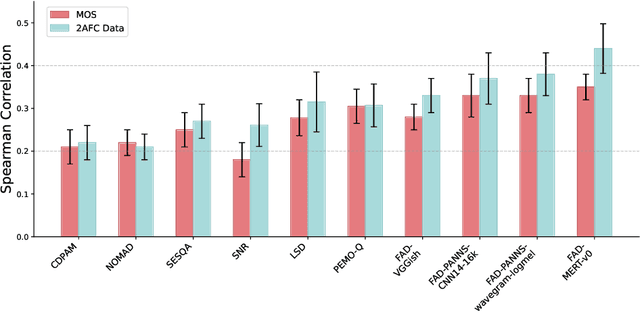
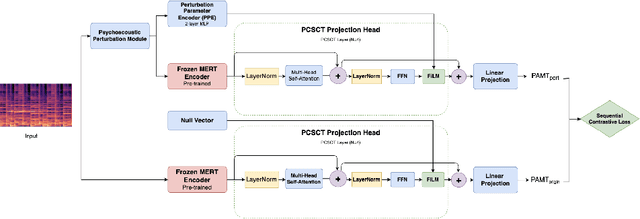
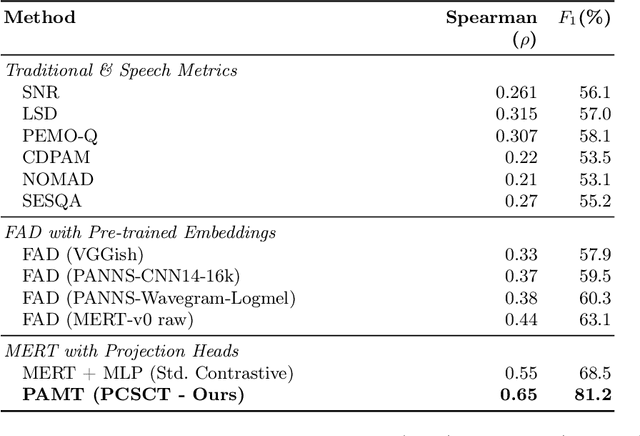
Music Information Retrieval (MIR) systems are highly vulnerable to adversarial attacks that are often imperceptible to humans, primarily due to a misalignment between model feature spaces and human auditory perception. Existing defenses and perceptual metrics frequently fail to adequately capture these auditory nuances, a limitation supported by our initial listening tests showing low correlation between common metrics and human judgments. To bridge this gap, we introduce Perceptually-Aligned MERT Transformer (PAMT), a novel framework for learning robust, perceptually-aligned music representations. Our core innovation lies in the psychoacoustically-conditioned sequential contrastive transformer, a lightweight projection head built atop a frozen MERT encoder. PAMT achieves a Spearman correlation coefficient of 0.65 with subjective scores, outperforming existing perceptual metrics. Our approach also achieves an average of 9.15\% improvement in robust accuracy on challenging MIR tasks, including Cover Song Identification and Music Genre Classification, under diverse perceptual adversarial attacks. This work pioneers architecturally-integrated psychoacoustic conditioning, yielding representations significantly more aligned with human perception and robust against music adversarial attacks.
Convolutional Feature Enhancement and Attention Fusion BiFPN for Ship Detection in SAR Images
Jun 18, 2025Synthetic Aperture Radar (SAR) enables submeter-resolution imaging and all-weather monitoring via active microwave and advanced signal processing. Currently, SAR has found extensive applications in critical maritime domains such as ship detection. However, SAR ship detection faces several challenges, including significant scale variations among ships, the presence of small offshore vessels mixed with noise, and complex backgrounds for large nearshore ships. To address these issues, this paper proposes a novel feature enhancement and fusion framework named C-AFBiFPN. C-AFBiFPN constructs a Convolutional Feature Enhancement (CFE) module following the backbone network, aiming to enrich feature representation and enhance the ability to capture and represent local details and contextual information. Furthermore, C-AFBiFPN innovatively integrates BiFormer attention within the fusion strategy of BiFPN, creating the AFBiFPN network. AFBiFPN improves the global modeling capability of cross-scale feature fusion and can adaptively focus on critical feature regions. The experimental results on SAR Ship Detection Dataset (SSDD) indicate that the proposed approach substantially enhances detection accuracy for small targets, robustness against occlusions, and adaptability to multi-scale features.
Uncertainty-Aware Prototype Semantic Decoupling for Text-Based Person Search in Full Images
May 07, 2025Text-based pedestrian search (TBPS) in full images aims to locate a target pedestrian in untrimmed images using natural language descriptions. However, in complex scenes with multiple pedestrians, existing methods are limited by uncertainties in detection and matching, leading to degraded performance. To address this, we propose UPD-TBPS, a novel framework comprising three modules: Multi-granularity Uncertainty Estimation (MUE), Prototype-based Uncertainty Decoupling (PUD), and Cross-modal Re-identification (ReID). MUE conducts multi-granularity queries to identify potential targets and assigns confidence scores to reduce early-stage uncertainty. PUD leverages visual context decoupling and prototype mining to extract features of the target pedestrian described in the query. It separates and learns pedestrian prototype representations at both the coarse-grained cluster level and the fine-grained individual level, thereby reducing matching uncertainty. ReID evaluates candidates with varying confidence levels, improving detection and retrieval accuracy. Experiments on CUHK-SYSU-TBPS and PRW-TBPS datasets validate the effectiveness of our framework.
JailPO: A Novel Black-box Jailbreak Framework via Preference Optimization against Aligned LLMs
Dec 20, 2024Large Language Models (LLMs) aligned with human feedback have recently garnered significant attention. However, it remains vulnerable to jailbreak attacks, where adversaries manipulate prompts to induce harmful outputs. Exploring jailbreak attacks enables us to investigate the vulnerabilities of LLMs and further guides us in enhancing their security. Unfortunately, existing techniques mainly rely on handcrafted templates or generated-based optimization, posing challenges in scalability, efficiency and universality. To address these issues, we present JailPO, a novel black-box jailbreak framework to examine LLM alignment. For scalability and universality, JailPO meticulously trains attack models to automatically generate covert jailbreak prompts. Furthermore, we introduce a preference optimization-based attack method to enhance the jailbreak effectiveness, thereby improving efficiency. To analyze model vulnerabilities, we provide three flexible jailbreak patterns. Extensive experiments demonstrate that JailPO not only automates the attack process while maintaining effectiveness but also exhibits superior performance in efficiency, universality, and robustness against defenses compared to baselines. Additionally, our analysis of the three JailPO patterns reveals that attacks based on complex templates exhibit higher attack strength, whereas covert question transformations elicit riskier responses and are more likely to bypass defense mechanisms.
A wearable Gait Assessment Method for Lumbar Disc Herniation Based on Adaptive Kalman Filtering
Dec 15, 2023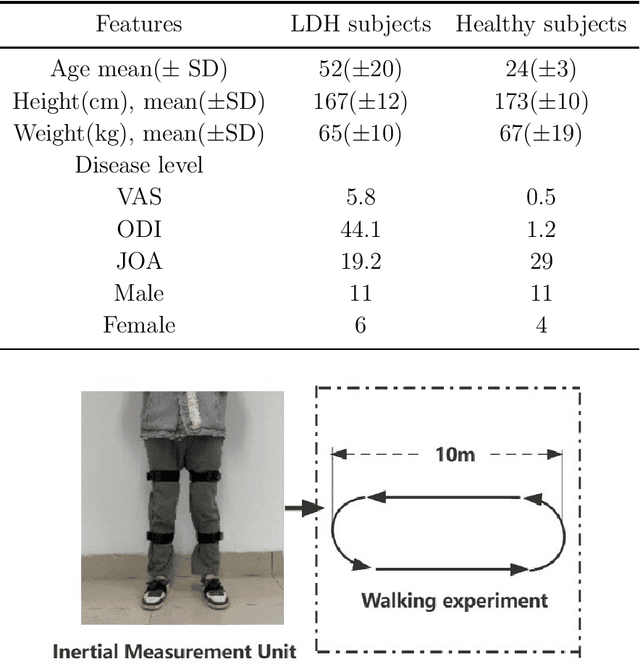
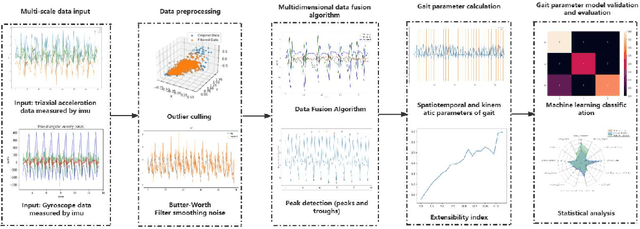

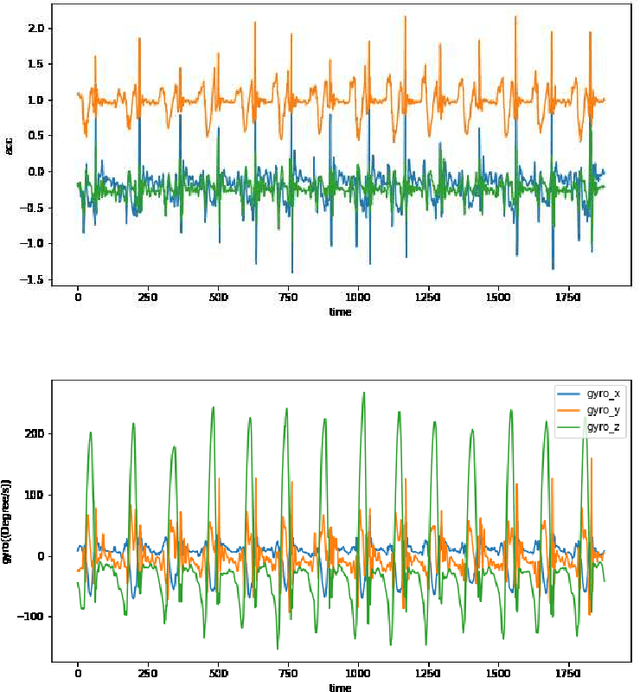
Lumbar disc herniation (LDH) is a prevalent orthopedic condition in clinical practice. Inertial measurement unit sensors (IMUs) are an effective tool for monitoring and assessing gait impairment in patients with lumbar disc herniation (LDH). However, the current gait assessment of LDH focuses solely on single-source acceleration signal data, without considering the diversity of sensor data. It also overlooks the individual differences in motor function deterioration between the healthy and affected lower limbs in patients with LDH. To address this issue, we developed an LDH gait feature model that relies on multi-source adaptive Kalman data fusion of acceleration and angular velocity. We utilized an adaptive Kalman data fusion algorithm for acceleration and angular velocity to estimate the attitude angle and segment the gait phase. Two Inertial Measurement Units (IMUs) were used to analyze the gait characteristics of patients with lumbar disc issues and healthy individuals. This analysis included 12 gait characteristics, such as gait spatiotemporal parameters, kinematic parameters, and expansibility index numbers. Statistical methods were employed to analyze the characteristic model and confirm the biological differences between the healthy affected side of LDH and healthy subjects. Finally, a classifier based on feature engineering was utilized to classify the gait patterns of the affected side of patients with lumbar disc disease and healthy subjects. This approach achieved a classification accuracy of 95.50%, enhancing the recognition of LDH and healthy gait patterns. It also provided effective gait feature sets and methods for assessing LDH clinically.
Viewport Prediction for Volumetric Video Streaming by Exploring Video Saliency and Trajectory Information
Nov 28, 2023Volumetric video, also known as hologram video, is a novel medium that portrays natural content in Virtual Reality (VR), Augmented Reality (AR), and Mixed Reality (MR). It is expected to be the next-gen video technology and a prevalent use case for 5G and beyond wireless communication. Considering that each user typically only watches a section of the volumetric video, known as the viewport, it is essential to have precise viewport prediction for optimal performance. However, research on this topic is still in its infancy. In the end, this paper presents and proposes a novel approach, named Saliency and Trajectory Viewport Prediction (STVP), which aims to improve the precision of viewport prediction in volumetric video streaming. The STVP extensively utilizes video saliency information and viewport trajectory. To our knowledge, this is the first comprehensive study of viewport prediction in volumetric video streaming. In particular, we introduce a novel sampling method, Uniform Random Sampling (URS), to reduce computational complexity while still preserving video features in an efficient manner. Then we present a saliency detection technique that incorporates both spatial and temporal information for detecting static, dynamic geometric, and color salient regions. Finally, we intelligently fuse saliency and trajectory information to achieve more accurate viewport prediction. We conduct extensive simulations to evaluate the effectiveness of our proposed viewport prediction methods using state-of-the-art volumetric video sequences. The experimental results show the superiority of the proposed method over existing schemes. The dataset and source code will be publicly accessible after acceptance.
DBFed: Debiasing Federated Learning Framework based on Domain-Independent
Jul 10, 2023

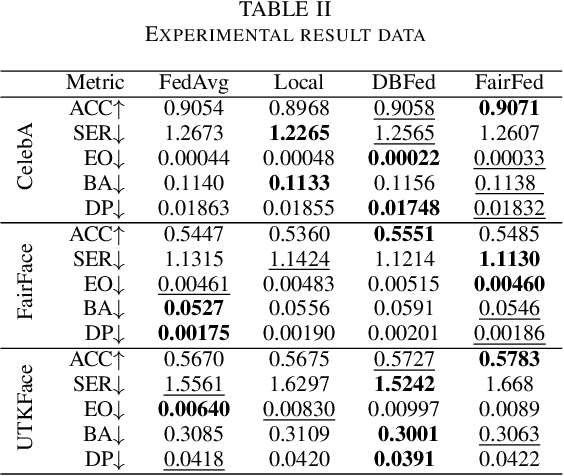
As digital transformation continues, enterprises are generating, managing, and storing vast amounts of data, while artificial intelligence technology is rapidly advancing. However, it brings challenges in information security and data security. Data security refers to the protection of digital information from unauthorized access, damage, theft, etc. throughout its entire life cycle. With the promulgation and implementation of data security laws and the emphasis on data security and data privacy by organizations and users, Privacy-preserving technology represented by federated learning has a wide range of application scenarios. Federated learning is a distributed machine learning computing framework that allows multiple subjects to train joint models without sharing data to protect data privacy and solve the problem of data islands. However, the data among multiple subjects are independent of each other, and the data differences in quality may cause fairness issues in federated learning modeling, such as data bias among multiple subjects, resulting in biased and discriminatory models. Therefore, we propose DBFed, a debiasing federated learning framework based on domain-independent, which mitigates model bias by explicitly encoding sensitive attributes during client-side training. This paper conducts experiments on three real datasets and uses five evaluation metrics of accuracy and fairness to quantify the effect of the model. Most metrics of DBFed exceed those of the other three comparative methods, fully demonstrating the debiasing effect of DBFed.
Target-Aware Tracking with Long-term Context Attention
Feb 27, 2023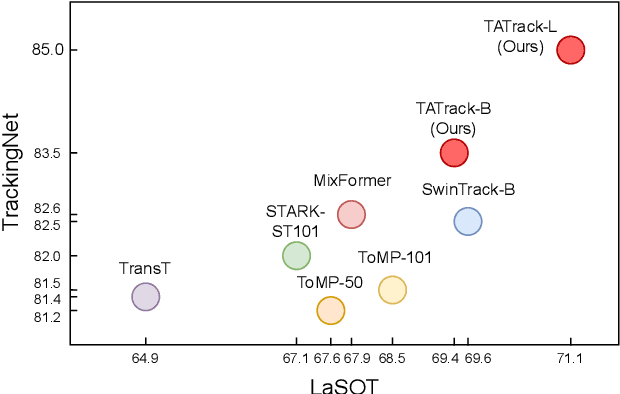
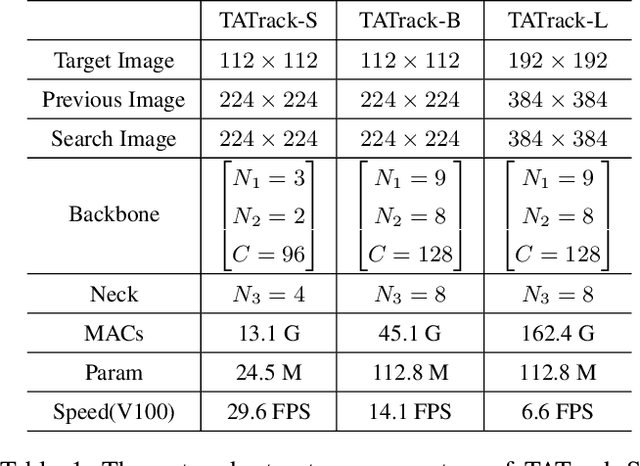
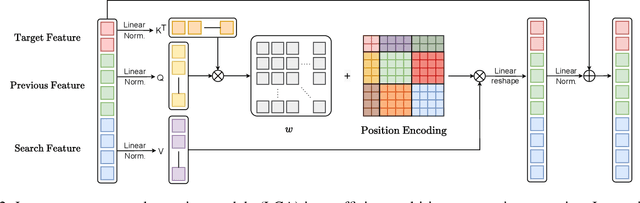
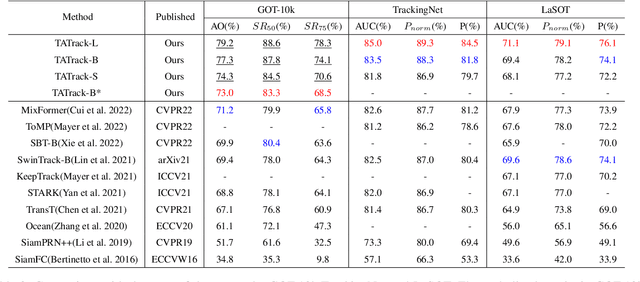
Most deep trackers still follow the guidance of the siamese paradigms and use a template that contains only the target without any contextual information, which makes it difficult for the tracker to cope with large appearance changes, rapid target movement, and attraction from similar objects. To alleviate the above problem, we propose a long-term context attention (LCA) module that can perform extensive information fusion on the target and its context from long-term frames, and calculate the target correlation while enhancing target features. The complete contextual information contains the location of the target as well as the state around the target. LCA uses the target state from the previous frame to exclude the interference of similar objects and complex backgrounds, thus accurately locating the target and enabling the tracker to obtain higher robustness and regression accuracy. By embedding the LCA module in Transformer, we build a powerful online tracker with a target-aware backbone, termed as TATrack. In addition, we propose a dynamic online update algorithm based on the classification confidence of historical information without additional calculation burden. Our tracker achieves state-of-the-art performance on multiple benchmarks, with 71.1\% AUC, 89.3\% NP, and 73.0\% AO on LaSOT, TrackingNet, and GOT-10k. The code and trained models are available on https://github.com/hekaijie123/TATrack.
Boost Image Captioning with Knowledge Reasoning
Nov 02, 2020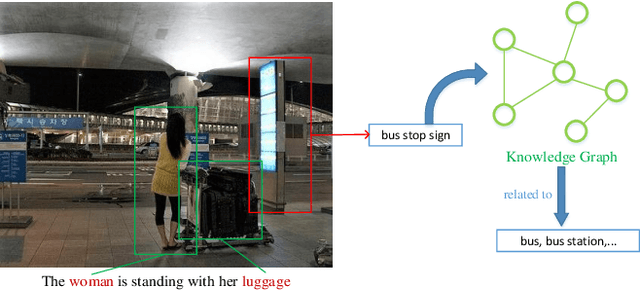
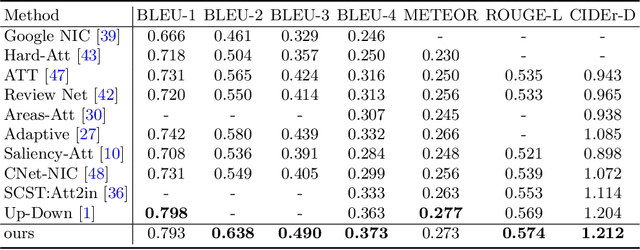
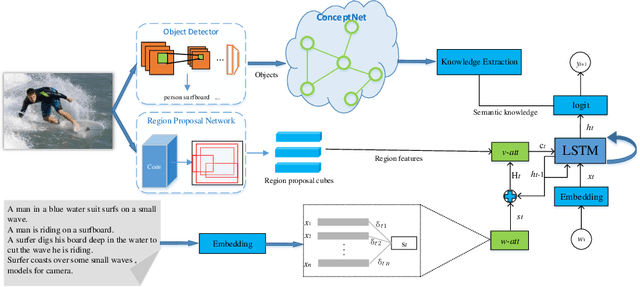

Automatically generating a human-like description for a given image is a potential research in artificial intelligence, which has attracted a great of attention recently. Most of the existing attention methods explore the mapping relationships between words in sentence and regions in image, such unpredictable matching manner sometimes causes inharmonious alignments that may reduce the quality of generated captions. In this paper, we make our efforts to reason about more accurate and meaningful captions. We first propose word attention to improve the correctness of visual attention when generating sequential descriptions word-by-word. The special word attention emphasizes on word importance when focusing on different regions of the input image, and makes full use of the internal annotation knowledge to assist the calculation of visual attention. Then, in order to reveal those incomprehensible intentions that cannot be expressed straightforwardly by machines, we introduce a new strategy to inject external knowledge extracted from knowledge graph into the encoder-decoder framework to facilitate meaningful captioning. Finally, we validate our model on two freely available captioning benchmarks: Microsoft COCO dataset and Flickr30k dataset. The results demonstrate that our approach achieves state-of-the-art performance and outperforms many of the existing approaches.