 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Prototype Semantic Decoupling for Text-Based Person Search in Full Images
May 07, 2025Text-based pedestrian search (TBPS) in full images aims to locate a target pedestrian in untrimmed images using natural language descriptions. However, in complex scenes with multiple pedestrians, existing methods are limited by uncertainties in detection and matching, leading to degraded performance. To address this, we propose UPD-TBPS, a novel framework comprising three modules: Multi-granularity Uncertainty Estimation (MUE), Prototype-based Uncertainty Decoupling (PUD), and Cross-modal Re-identification (ReID). MUE conducts multi-granularity queries to identify potential targets and assigns confidence scores to reduce early-stage uncertainty. PUD leverages visual context decoupling and prototype mining to extract features of the target pedestrian described in the query. It separates and learns pedestrian prototype representations at both the coarse-grained cluster level and the fine-grained individual level, thereby reducing matching uncertainty. ReID evaluates candidates with varying confidence levels, improving detection and retrieval accuracy. Experiments on CUHK-SYSU-TBPS and PRW-TBPS datasets validate the effectiveness of our framework.
Target-Aware Tracking with Long-term Context Attention
Feb 27, 2023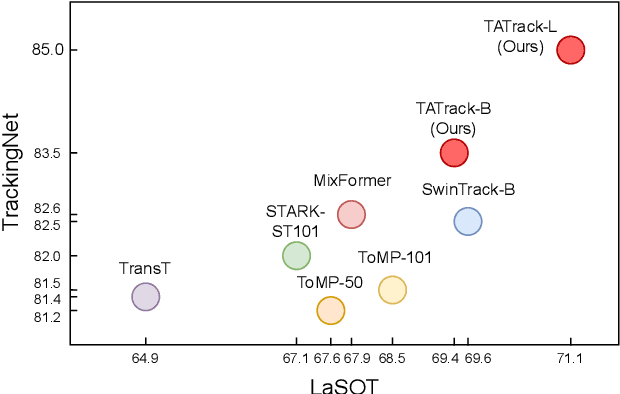
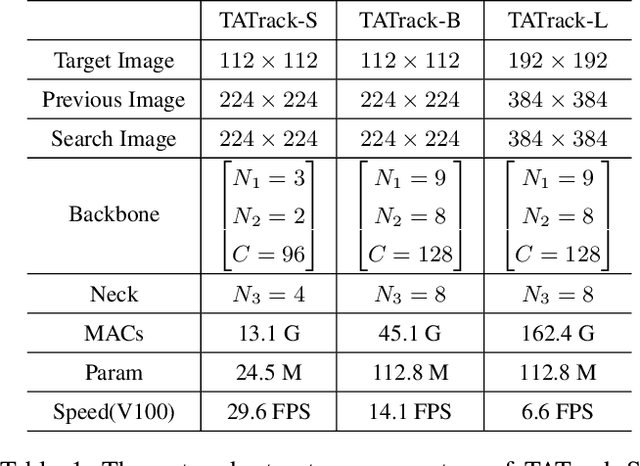
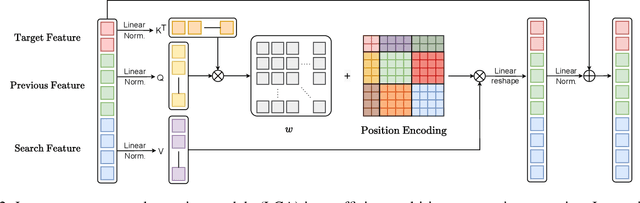
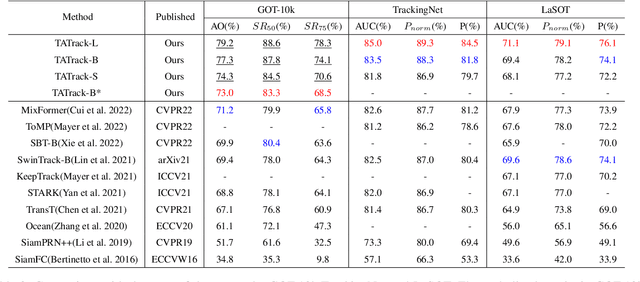
Most deep trackers still follow the guidance of the siamese paradigms and use a template that contains only the target without any contextual information, which makes it difficult for the tracker to cope with large appearance changes, rapid target movement, and attraction from similar objects. To alleviate the above problem, we propose a long-term context attention (LCA) module that can perform extensive information fusion on the target and its context from long-term frames, and calculate the target correlation while enhancing target features. The complete contextual information contains the location of the target as well as the state around the target. LCA uses the target state from the previous frame to exclude the interference of similar objects and complex backgrounds, thus accurately locating the target and enabling the tracker to obtain higher robustness and regression accuracy. By embedding the LCA module in Transformer, we build a powerful online tracker with a target-aware backbone, termed as TATrack. In addition, we propose a dynamic online update algorithm based on the classification confidence of historical information without additional calculation burden. Our tracker achieves state-of-the-art performance on multiple benchmarks, with 71.1\% AUC, 89.3\% NP, and 73.0\% AO on LaSOT, TrackingNet, and GOT-10k. The code and trained models are available on https://github.com/hekaijie123/TATrack.
Boost Image Captioning with Knowledge Reasoning
Nov 02, 2020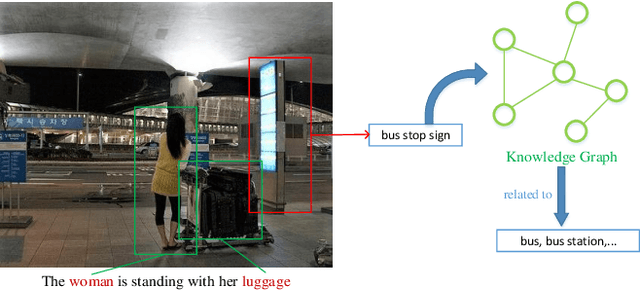
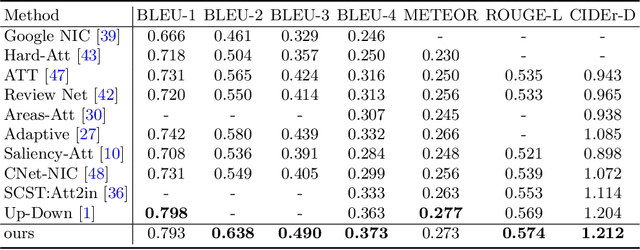
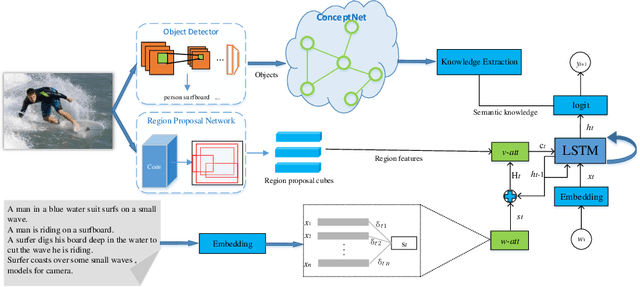

Automatically generating a human-like description for a given image is a potential research in artificial intelligence, which has attracted a great of attention recently. Most of the existing attention methods explore the mapping relationships between words in sentence and regions in image, such unpredictable matching manner sometimes causes inharmonious alignments that may reduce the quality of generated captions. In this paper, we make our efforts to reason about more accurate and meaningful captions. We first propose word attention to improve the correctness of visual attention when generating sequential descriptions word-by-word. The special word attention emphasizes on word importance when focusing on different regions of the input image, and makes full use of the internal annotation knowledge to assist the calculation of visual attention. Then, in order to reveal those incomprehensible intentions that cannot be expressed straightforwardly by machines, we introduce a new strategy to inject external knowledge extracted from knowledge graph into the encoder-decoder framework to facilitate meaningful captioning. Finally, we validate our model on two freely available captioning benchmarks: Microsoft COCO dataset and Flickr30k dataset. The results demonstrate that our approach achieves state-of-the-art performance and outperforms many of the existing approaches.